
2021.11. 걸어서 World Trade Center Station까지. 뉴욕의 지하철 역 중에 가장 깨끗.
RFM segmentation
앞선 글에서 cohort 분석에 사용한 e-commerce 주문 내역 데이터를 그대로 사용하여 이번 포스팅에서는 RFM segmentation을 해보겠습니다.
1. Intro
1. 분석 목표
RFM 프레임에 따라 주문고객들을 분류해보겠습니다. RFM은 아래와 같은 의미를 지니고 있습니다.
- R : Recency(최근 주문일로부터의 경과 일수) → 숫자가 작을수록 좋음
- F : Frequency(최근 ○개월간 주문 횟수) → 숫자가 클수록 좋음
- M : Monetary Value(최근 ○개월간 주문 금액) → 숫자가 클수록 좋음
"○"의 값은 비즈니스 모델과 제품 성격에 따라 적절한 값이 달라지겠습니다. 오늘 분석에서는 '12개월'을 사용하겠습니다.
2. EDA & Manipulation
앞선 글 "[Product] 고객님, 언제 처음 오셨어요?"에서 데이터프레임의 구조를 이미 살펴보았습니다.

1. Manipulation
1) snapshot day 만들기
분석 대상이 되는 시계열 데이터의 기간을 먼저 확인해보겠습니다.
print(min(df['InvoiceDate']), max(df['InvoiceDate']))가장 빠른 날짜는 2010-12-01, 가장 최신 날짜는 2011-12-09입니다. 가상의 분석일을 snapshot_date로 설정하겠습니다. 분석대상의 마지막 날짜에 1을 더해준 날짜입니다.
snapshot_date = max(df.InvoiceDate) + dt.timedelta(days=1)
print(snapshot_date)snapshot_date를 출력해보니 2011-12-10 이라고 나옵니다.
2) TotalSum 컬럼 만들기
우리가 구할 RFM중의 M은 구매액입니다. 그런데 주어진 테이블에 구매액은 따로 표시되어 있지 않습니다. 구매액은 Quantity 컬럼과 Unitprice 컬럼을 곱한 값이므로 TotalSum이라는 컬럼을 하나 따로 만들어주겠습니다.
df['TotalSum'] = df['Quantity'] * df['UnitPrice']3. RFM metrics 구하기
RFM 값을 계산하는데 필요한 내용이 이제 df 데이터프레임에 모두 준비되었습니다.
- Recency : snapshot_date(분석일)에서 CustomerID의 InvoiceDate 중 가장 큰 값(최근 날짜)을 빼면 그 고객이 "가장 최근 구매로부터 몇일이 지났는지" 알 수 있습니다.
- Frequecy : 분석기간 중의 InvoiceNo 숫자를 세면 구매 횟수입니다.
- Monetary Value : 앞서 새로 만든 Total Sum을 CustomerID 별로 합산하면 그 고객의 총구매액이 됩니다.
위 방식대로 RFM을 계산한 뒤 datamart라는 변수에 저장하겠습니다.
datamart = df.groupby(['CustomerID']).agg({'InvoiceDate': lambda x: (snapshot_date - x.max()).days, 'InvoiceNo':'count', 'TotalSum':'sum'})
datamart.head()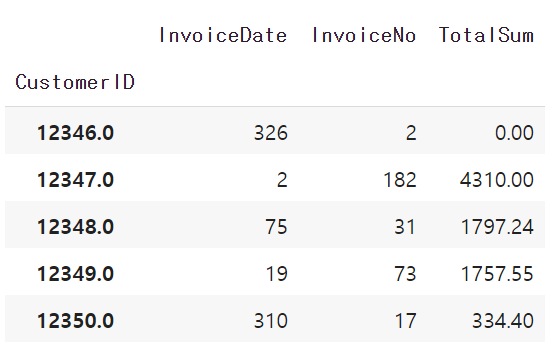
구하고자 하는 숫자는 나왔는데 컬럼 이름과 값들이 일치하지 않습니다. Recency, Frequency, MonetaryValue 컬럼으로 바꿔주겠습니다. inplace 파라미터를 True로 하면 원본 데이터프레임이 변경됩니다.
datamart.rename(columns = {'InvoiceDate': 'Recency', 'InvoiceNo': 'Frequency', 'TotalSum': 'MonetaryValue'}, inplace=True)
datamart.head()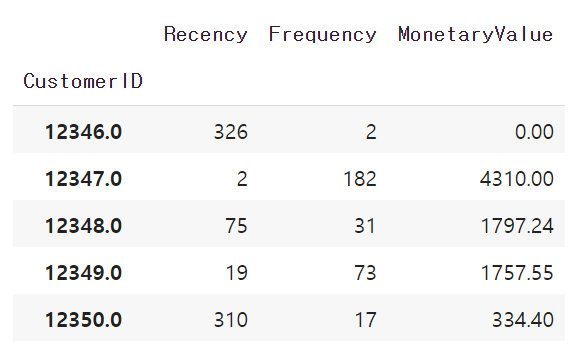
RFM 테이블이 드디어 완성되었습니다.
이제 각 고객의 Recency, Frequecy, Moneytary Values를 알고 있습니다.
그렇다면 이제 RFM을 기준으로 고객들을 segment해볼까요?
4. RFM Segmentation
각 고객의 Recency, Frequecy, MoneytaryValue에 1부터 4까지 각각 label을 부여하려고 합니다.
여기서 주의할 점은 Recency는 낮을 수록 좋은 것이고, Frequency와 MonetaryValue는 높은 값일 수록 좋다는 것입니다. 따라서 일관된 segentation을 하려면 R 값은 낮은 그룹에 4를 부여하고, F와 M 값은 높은 그룹에 4를 부여하는 것이 좋을 것 같습니다.
1.Recency quarile 만들기
r_labels = range(4, 0, -1)
r_quartiles = pd.qcut(datamart['Recency'], 4, labels = r_labels)
datamart = datamart.assign(R = r_quartiles)
datamart.head() 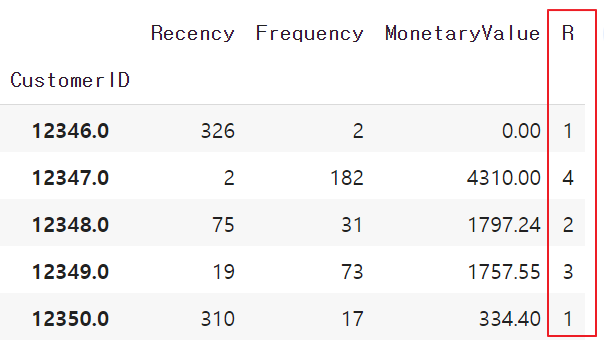
구매한지 2일된 고객은 "1", 구매한지 182일 된 고객은 "4"로 label이 잘 형성되었습니다.
2.Frequecy와 MonetaryValue quarile 만들기
Recency와 같은 방법으로 Frequency와 MonetaryValue에도 label을 붙여보겠습니다. label 순서는 정 반대로 해야됩니다!
f_labels = range(1,5)
m_labels = range(1,5)
f_quartiles = pd.qcut(datamart['Frequency'], 4, labels=f_labels)
m_quartiles = pd.qcut(datamart['MonetaryValue'], 4, labels = m_labels)
datamart = datamart.assign(F = f_quartiles.values)
datamart = datamart.assign(M = m_quartiles.values)
datamart.head()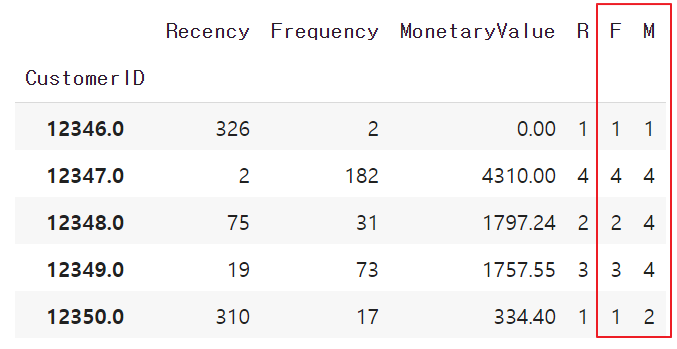
자주 구매한 고객, 구매금액이 더 높은 고객에게는 F와 M의 label이 4가 붙은 것을 볼 수 있습니다.
3. RFM Score 부여하고 분포 확인해보기
R, F, M의 값을 모두 더한 값을 RFM_score라는 별도의 컬럼에 저장하겠습니다. 고객이 지닌 value의 척도로 사용할 수 있습니다. 새로 만든 RFM_score 를 기준으로 그룹핑도 해볼 수 있습니다. 당연하게도 제일 낮은 score는 3, 제일 높은 score는 12 입니다.
datamart['RFM_score'] = datamart[['R', 'F', 'M']].sum(axis=1)
datamart.groupby('RFM_score').agg({'Recency':'mean', 'Frequency': 'mean', 'MonetaryValue': ['mean','count']}).round(1)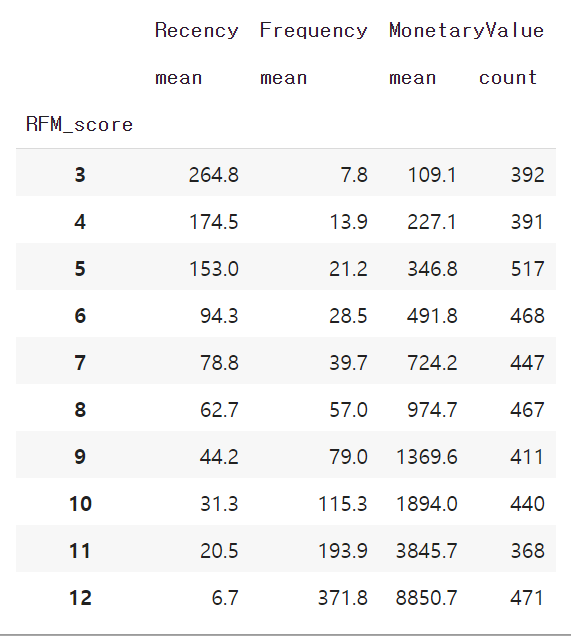
score 기준으로는 고객을 12개의 그룹으로 나눌 수 있었습니다. 이것을 좀 더 간편하게 3개의 그룹으로 압축하겠습니다. 고객을 세분화하면 할수록 의사결정은 정교해지지만 액션은 느려지게 됩니다. 3개 정도면 적당할 것 같습니다. 높은 밸류의 고객군부터 Gold, Silver, Bronze 라는 이름을 붙여주겠습니다. 이것은 RFM_medal 이라는 컬럼에 저장하겠습니다.
def medal_seg(df):
if df['RFM_score'] >= 9:
return 'Gold'
elif (df['RFM_score'] >= 5) and (df['RFM_score'] < 9):
return 'Silver'
else:
return 'Bronze'
datamart['RFM_medal'] = datamart.apply(medal_seg, axis=1)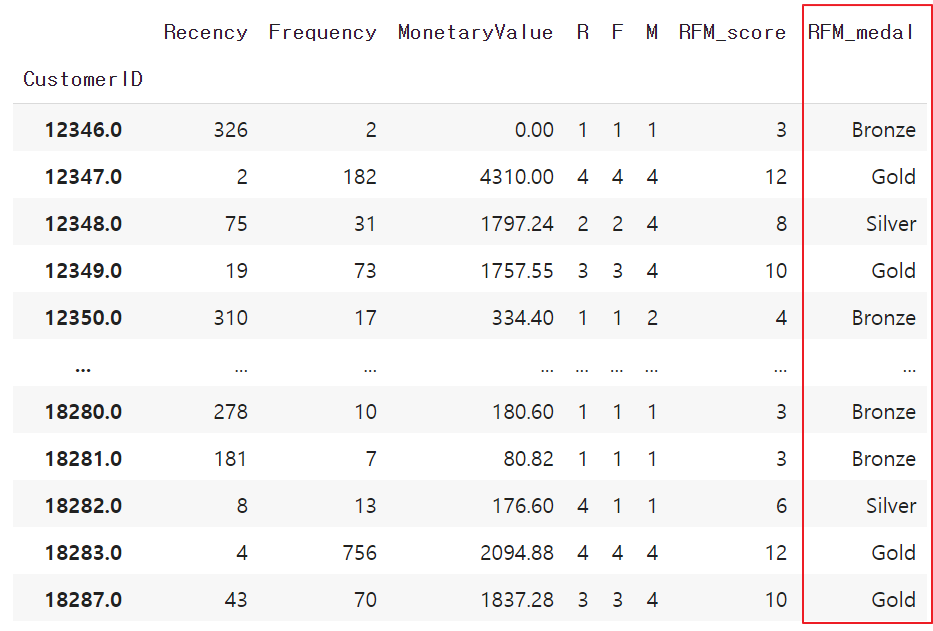
datamart 데이터프레임에 RFM_medal 컬럼이 생긴 것을 확인했습니다.
마지막으로 RFM_medal 별로 RFM 값의 평균은 얼마나 되는지, RFM_medal 별로 몇명이나 되는지 확인해보겠습니다.
datamart.groupby('RFM_medal').agg({'Recency':'mean', 'Frequency':'mean', 'MonetaryValue': ['mean','count']})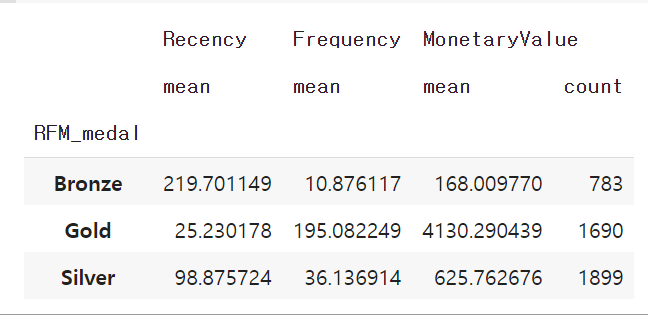
가장 우량한 고객군인 Gold 고객들이 recency, frequency, moneytary value 세가지 측면에서 모두 우수한 성과를 보여주고 있습니다. 이들이 전체 고객의 40%에 가까운 비율을 차지하고 있습니다.
제가 개인적으로 느끼기에는 RFM segmentation에서 무언가 action item이 바로 도출되지는 않는 것 같습니다. 다만 e-commerce 기업의 경우 비즈니스 health를 평가하기 위한 프레임 중 하나로는 유용해 보입니다.
마무리
이번 섹션에서는 RFM 프레임으로 고객들을 segment 해보았습니다.
RFM이 이해하기 쉬운 프레임워크이긴 하지만, 인사이트를 주기는 어려운 것 같습니다. 학생들을 1등부터 100등까지 세워놓은 다음 10등은 몇점인지, 30등은 몇점인지 따져보면 저의 기대치에서 크게 다르지 않을 것이기 때문입니다.
제 눈이 발견할 수 없는 customer segmentation을 컴퓨터의 힘으로 발견해보고 싶습니다.
머신러닝의 한종류인 unsupervised learning, 그 중에서도 clustering 테크닉을 이용해서 customer segmentation을 해볼 수 있습니다.
이것은 다음 포스팅에서 도전해보겠습니다!
- 포스팅의 오류를 지적해주시면 저의 공부에 많은 도움이 됩니다😀
