
2022.3. 학교앞 워싱턴스퀘어파크의 이름모를 피아니스트.
Cohort 분석
이번 포스팅에서는 cohort 분석을 해보겠습니다.
저의 첫번째 데이터 분석 실습입니다.
고객을 cohort별로 구분하면 무엇이 좋을까요?
전체를 놓고 봤을 때는 안보이던 패턴을 찾을 수 있습니다.
고객들은 제품에 온보딩 된 이후 lifecycle에 따라 제품 사용 패턴이 달라집니다. 최초구매일, 최초가입일 등을 기준으로 cohort를 나눈다면 여러 시점에 온보딩한 고객들을 같은 선상에 놓고 비교할 수 있습니다.
가령 온보딩 이후 3개월차에 고객들이 여전히 우리 제품을 사용하는 비율은 얼마인지, 그 비율이 계속 개선되고 있는지 알 수 있습니다.
1. Intro
1. 데이터 소개
오늘 분석할 데이터는 영국 UCI Machine Learning Repository에 공개되어 있는 Online Retail Data Set 입니다. 영국 e-commerce 회사의 2010.1.2~2011.9.12 의 판매 내역을 담고 있습니다. 회사의 고객중 상당수는 도매업체라고 합니다.
2. 분석 목표
오늘 해볼 분석은 Cohort 분석입니다. cohort는 time(구매일시), behavior(구매패턴), size(구매액수) 등 다양한 기준으로 나눠볼 수 있는데 오늘은 time을 기준으로 나눠보겠습니다.
최초 주문 날짜를 기준으로 cohort를 구성한 후에 "1개월씩 경과함에 따라 cohort 별 retention이 어떻게 변화하는지" 확인해보겠습니다.
2. EDA & Manipulation
분석을 시작하기에 앞서 1) pandas 라이브러리, 2) 데이터(csv 포맷)를 불러옵니다. 데이터는 데이터프레임 형태로 df 변수에 할당하겠습니다.
import pandas as pd
df = pd.read_csv('/content/drive/MyDrive/practice/data.csv')1. 자료구조, 요약통계
본격적인 분석에 앞서 테이블의 대략적인 모양을 확인해보려고 합니다. 데이터프레임의 컬럼과 첫 5개줄 내용만 확인해보겠습니다. head 메소드의 괄호 안에 숫자를 넣으면 그 숫자만큼 row를 불러올 수 있습니다. 아무 것도 넣지 않으면 디폴트는 5입니다.
df.head()
대략 이런 테이블입니다. 어떤 고객(CustomerID)이 어떤 상품(Description)을 몇 개(Quantity), 언제(InvoiceDate), 얼마치(UnitPrice)를 구매했는지 기록한 데이터입니다.
2. 데이터타입, missing value
데이터 중 null 이 얼마나 있는지 궁금합니다.
df.info()
컬럼별로 숫자를 살펴보았습니다. 총 541,909개의 주문 데이터가 있는 것 같은데, Description과 CustomeID 컬럼이 다른 컬럼에 비해 유독 숫자가 적습니다. 이 컬럼들에 null 값이 꽤 많은 것 같습니다. 아래 방법으로도 확인해볼 수 있습니다.
df.isna().any().count()null이 존재할 경우 분석이 왜곡될 수 있으므로 본격적인 분석 전에 적절한 처치를 해주어야 합니다.
1) null이 포함된 row를 삭제하거나,
2) null을 0으로 대체하거나,
3) 컬럼의 mean 또는 median 으로 대체
해볼 수 있습니다. 맥락에 따라 선택은 달라집니다.
여기서는 null을 어떻게 처치하더라도 분석에 영향을 주지 않는 상황입니다. 특별히 처치는 하지 않고 넘어가겠습니다.
3. 시각화
여러 변수들 간의 관계를 살펴보려면 pairplot을 먼저 그려볼 수 있습니다. 그렇지만 이번 분석에서는 딱히 필요하지 않기 때문에 EDA를 위한 시각화는 생략하고 넘어가겠습니다.
4. Manipulation
데이터 가공은 두가지 방법으로 나눠서 해보겠습니다.
1) 데이터타입 변경 : to_datetime()
InvoiceDate의 Dtype을 보니 datetime이 아니라 object로 되어 있습니다. 시계열 분석을 위해 datetime으로 타입을 바꾸고 다시 info 메소드로 확인해보겠습니다.
import datetime as dt
df['InvoiceDate'] = pd.to_datetime(df['InvoiceDate'])
df.info()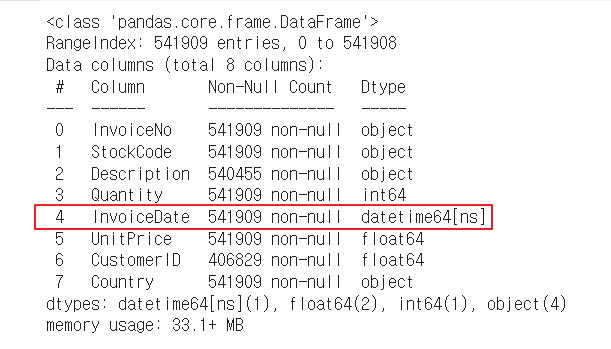
InvoiceDate컬럼이 datetime64 타입으로 바뀐 것을 확인했습니다.
2) 구매'월' 뽑아내기
InvoiceDate 컬럼은 구매 일시입니다. 연,월,일,시,분,초가 정확하게 기재되어 있습니다.
이 InvoiceDate 컬럼의 최초 구매'월'을 기준으로 cohort를 나누려고 합니다. 구매'월'만 담긴 별도의 컬럼을 만들어보겠습니다.
먼저 구매일시를 구매월(1일)로 바꿔주는 함수를 정의한 후 InvoiceDate 컬럼에 적용하고,
결과는 InvoiceMonth라는 별도의 컬럼에 저장하겠습니다.
def get_month(x): return dt.datetime(x.year, x.month, 1)
df['InvoiceMonth'] = df['InvoiceDate'].apply(get_month)
InvoiceMonth 컬럼이 생겼습니다. 모든 구매내역의 '월'이 담겨있습니다.
우리는 최초 구매월을 기준으로 cohort를 나눌 것이기 때문에 구매자별로 최초 구매월이 필요합니다. CustomerID 컬럼을 기준으로 그룹핑하고 각각의 InvoiceMonth를 InvoiceMonth 중 가장 작은 값으로 변형합니다.
df['CohortMonth'] = df.groupby('CustomerID')['InvoiceMonth'].transform('min')
df.head()
InvoiceMonth와 CohortMonth라는 컬럼을 성공적으로 만들었습니다.
3) Cohort Index 만들기
최초구매월을 기준으로 1개월씩 경과할 때마다 retention이 어떻게 변하는지 살펴보는게 이번 분석의 목적이었습니다. 피벗 테이블의 형태가 되겠습니다.
row에는 모든 cohort가 있고, column에는 시간 경과가 있고, value에는 retention rate를 넣겠습니다. column에서 보여줄 시간 경과는 1(개월), 2(개월), 3(개월)... 이렇게 숫자로 보여주려고 합니다. 이것을 Cohortindex라고 부르겠습니다.
InvoiceMonth컬럼에서 CohortMonth 컬럼을 빼면 그 구매건이 최초 구매로부터 "몇 개월" 경과한 구매인지를 알 수 있습니다. 이 값을 정수로 표현하려는 것입니다.
정수 형태의 CohortIndex를 부여하기 위해 연/월/일을 integer로 뽑아오는 함수를 정의하겠습니다.
def get_date_int(df, column):
year = df[column].dt.year
month = df[column].dt.month
day = df[column].dt.day
return year, month, day그 다음 InvoiceMonth 컬럼과 CohortMonth컬럼에 get_date_int 함수를 적용한 후, 그 차이를 CohortIndex라는 컬럼에 저장하겠습니다. year와 month 값만 추출하면 되기 때문에 언팩킹을 사용합니다.
invoice_year, invoice_month, _ = get_date_int(df, 'InvoiceMonth')
cohort_year, cohort_month, _ = get_date_int(df, 'CohortMonth')
years_diff = invoice_year - cohort_year
months_diff = invoice_month - cohort_month
df['CohortIndex'] = years_diff * 12 + months_diff + 1
df.head()최초 구매월의 cohort index를 1로 둘 것이기 때문에, (각 구매시점 - 최초구매시점)에 1씩 더해줬습니다. CohortIndex 컬럼이 제대로 들어갔는지 확인해보겠습니다.

4) 피벗테이블 만들기
CohortMonth컬럼과 CohortIndex컬럼 모두 같은 값을 가진 CustomerID들의 unique한 숫자를 구해보겠습니다. 피벗테이블 형태로 보는 것이 편할 것 같습니다. Series.nunique함수를 써서 구해보고 출력해보겠습니다.
cohort_data = df.groupby(['CohortMonth', 'CohortIndex'])['CustomerID'].apply(pd.Series.nunique)
print(cohort_data)
CohortMonth가 인덱스로 들어가있습니다. 보기좋게 reset_index하여 컬럼을 CohortMonth, CohortIndex, CustomerID 이렇게 3개로 정리한 후 피벗테이블을 만들고 DataFrame 형태로 저장하겠습니다.
cohort_data = cohort_data.reset_index()
cohort_counts = cohort_data.pivot_table(index='CohortMonth', columns='CohortIndex', values='CustomerID')
print(cohort_counts)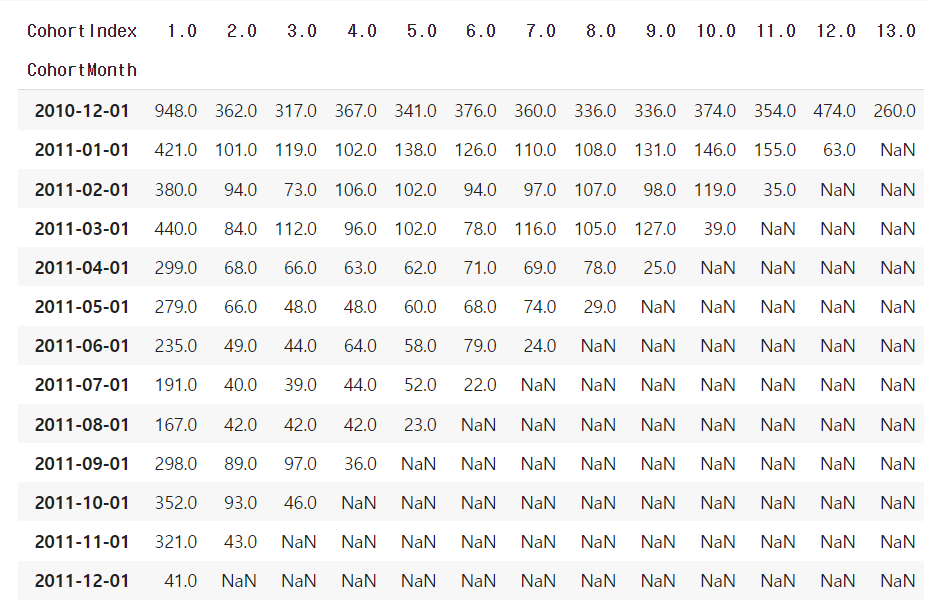
cohort 별로 1개월씩 경과함에 따라 구매내역이 있는 CustomerID의 갯수를 보여주는 피벗테이블이 완성되었습니다. NaN으로 표기된 부분은 아직 도래하지 않은 시점이어서 자료가 없는 구간입니다.
데이터 manipulation은 여기까지 하고, 본격적으로 Cohort 분석을 해보겠습니다. manupulation만 해도 제법 일이 많습니다.
3. Cohort 분석
CohortIndex가 1.0인 컬럼, 즉 첫번째 컬럼이 cohort 분석의 기초가 되는 cohort 사이즈입니다. 이 것을 cohort_sizes라는 변수에 새로 할당하겠습니다. 데이터프레임을 인덱스를 이용해 슬라이실할때는 iloc 메소드를, row나 column 이름으로 슬라이싱할 때는 loc를 사용합니다.
cohort_sizes = cohort_counts.iloc[:,0]위에서 만든 피벗테이블은 각 CohortMonth별, 각 CohortIndex별 CusomerId의 유니크한 숫자를 보여주고 있습니다. 이 숫자들을 각 cohort의 사이즈로 나눠주면 비율로 바꿔줄 수 있습니다. 이 테이블을 retention 이란 변수에 먼저 저장합니다. divide 함수의 파라미터 중에 axis=0은 row 방향으로 나눠준다는 뜻입니다. (axis=1이면 column 방향, 즉 vertical로 적용됩니다.)
"%" 단위로 보기 위해 100을 곱하고, 깔끔하게 소수 셋째자리에서 반올림하겠습니다.
retention = cohort_counts.divide(cohort_sizes, axis= 0)
retention.round(3)*100피벗테이블이 어떤 모양으로 변했는지 살펴보겠습니다.
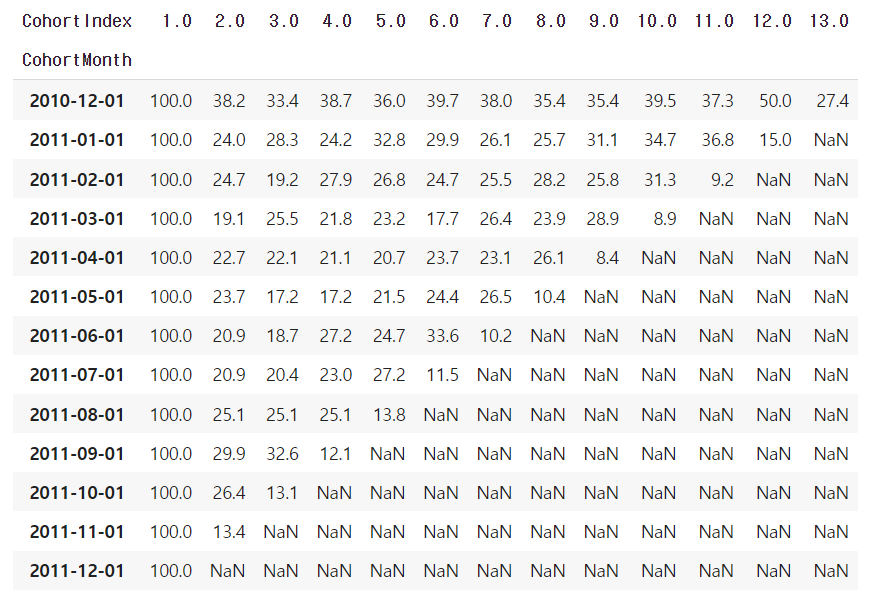
retention 테이블이 완성되었습니다. 첫번째 row를 보면, 2010년 12월에 최초구매한 사용자들중 27.4%가 12개월이 경과한 후에도 여전히 구매하고 있는 것을 알 수 있습니다.
시각화
이 테이블을 팀원들과 공유하려고 합니다. business stakeholder와 소통하는 좋은 방법 중 하나는 시각화입니다. retention talbe은 heatmap 으로 시각화하면 의미가 잘 전달될 것 같습니다.
시각화 패키지 중 seaborn이 커스텀화된 시각화를 하기 좋습니다. seaborn은 matplotlib의 바탕 위에 만들어진 패키지입니다. seaborn과 matplotlib을 모두 import한 뒤 위에서 만든 retention 테이블을 시각화를 해보겠습니다.
import seaborn as sns
import matplotlib.pyplot as plt
plt.figure(figsize=(10,8))
plt.title('Retention rates')
sns.heatmap(data=retention,
annot = True,
fmt= '.0%',
vmin = 0.0,
vmax = 0.5,
cmap = 'Blues')
plt.show()annot 파라미터를 True로 지정하면 각 셀마다 value가 표기됩니다.소수점 첫째자리까지 표기하는 포맷으로 하고요. vmin과 vmax는 outlier들의 영향을 받지 않게 해줍니다.
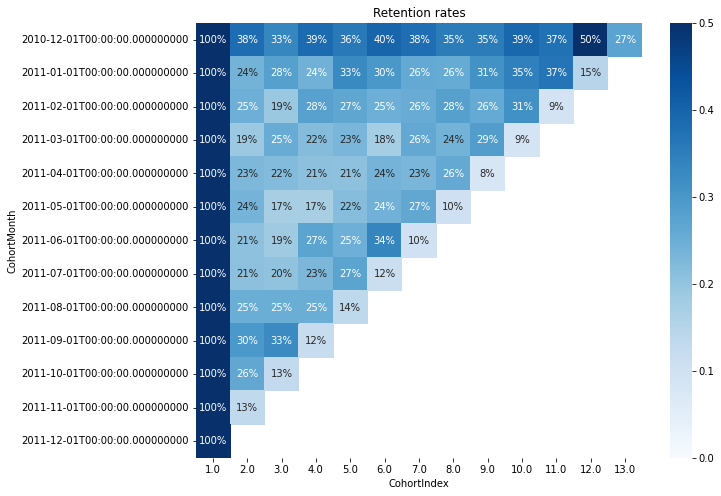
2010년 12월에 최초 구매한 cohort의 리텐션이 압도적으로 높습니다.
이 때 도대체 무슨 일이 일어났던 것일까요? 당시의 마케팅 채널이 무엇이었는지, 마케팅 메시지는 무엇이었는지, 이 고객들의 주된 구매품목은 무엇인지 추가적인 리뷰의 필요성이 생겼습니다.
또한 cohort 별로 retention rate가 시간이 갈수록 떨어진다기보다는, 오르락 내리락 하는 모습을 보이고 있습니다. 고객들이 매월 '꾸준히' 구매할 수 있도록 유도하는 장치를 고안해볼 수 있습니다. 기업 입장에서는 예측 가능성도 소중한 자산입니다.
가령 저는 Amazon Prime 회원인데요. 초기에 납부한 가입비가 아까워서 그냥 아무생각 없이 대부분의 쇼핑은 Amazon에서만 합니다. 저의 생필품 구매 가격은 매월 일정한 수준으로 유지될 테니, Amazon 입장에서는 revenue forecast를 하기가 쉬울 것입니다. 그렇다면 회사의 투자, 지출 계획을 세우기가 훨씬 용이해집니다.
마무리
쉽지 않았습니다.
강의들을 때 보았던 샘플처럼 잘 되지 않았던 이유는, 강의 때 보았던 raw data와 제가 실습용으로 다운받은 raw data의 포맷이 조금씩 달라서입니다. 데이터 포맷을 바꾸느라고 강의 자료와 구글을 계속 뒤져가면서 해야 했습니다. 현재로서는 전체 과정 중에 데이터 전처리가 가장 까다롭게 느껴지는데, 전처리에 관한 기초를 탄탄히 해야 버벅이지 않을 것 같습니다. DataCamp에 데이터 전처리 관련 course가 아주 많이 개설되어 있습니다. 이번 4월 안에 그것들을 전부 수강해야하겠습니다.
- 포스팅의 오류를 지적해주시면 저의 공부에 많은 도움이 됩니다😀
