논문 선정 이유
vector database 검색을 다루면서 다양한 modalities에 대한 embedding에 관심이 생겼다.
대규모 image-text pairs를 contrastive learning method로 pre-training한 "CLIP"에 이어 6가지 modalities를 표현하는 "ImageBind"를 알아보게 되었다.
간단 ImageBind 요약
ImageBind는 meta에서 발표한 CVPR 2023 하이라이트 페이퍼.
ImageBind의 핵심
1. 이미지를 기준으로 6가지 modalities를 하나의 공간에 임베딩
image를 기준으로 6가지 modalites를 joint embedding space로 임베딩.
2. Emergent Alignment
학습 과정에서 보지 못한 pair에 대해 align이 잘됨. (image-audio) / (image-text) -> (audio-text) align
즉 ImageBind를 한 줄로 표현하자면,
6가지 모달리티를 이미지를 기준으로 공통 임베딩 공간에 임베딩함으로써 모든 모달리티들 간의 연관성을 찾을 수 있었다는 것!
IMAGEBIND: One Embedding Space To Bind Them All
- 2023년 5월
- Meta
Introduction
- 기존에는 이러한 멀티모달 임베딩 모델을 학습하기 위해 모든 모달리티간의 pair가 필요했다. 이러한 모든 조합으로 구성된 대량의 멀티모달 데이터는 없기 때문에 여러 멀티모달을 표현하는 임베딩 모델을 학습하는데 여러움이 있었다. (video-audio embedding을 image-text task에 사용할 수 없었다.)
- "하나의 이미지는 많은 경험을 하나로 묶을 수 있다."는 아이디어에서 여러 모달리티를 이미지를 기준으로 bind
- 본 논문에서는 모든 모달리티간의 쌍을 학습하지 않아도 cross-modality를 가능하게 함으로써 무려 6가지의 모달리티를 표현하는 모델을 만들어 냈다.
Method

- 6가지 modalites: Image(Video), Text, Audio, Depth(3D), Thermal(열화상), IMU(움직임)
- image와 각 모달리티의 pair 데이터셋을 학습.
- image의 embedding space에 modality들을 align 시킴. (Joint Embedding)
Contrastive learning
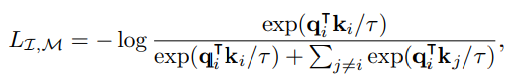
-
Loss: infoNCE loss
-
: i번째 이미지
-
: 에 대응되는 해당 modality의 positive sample
-
: 의 임베딩 ()
-
: 의 임베딩 ()
-
이미지와 postivie sample의 내적은 크게, negative samples과의 내적은 작아지도록 학습.
(와 는 가깝고 와 는 멀어짐.)
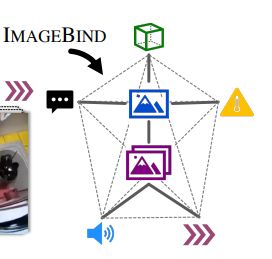
위 그림에서 실선은 실제로 학습에 사용되어 이미지와 각 모달리티간의 align된 관계이고, 점선은 학습되지 않았지만 서로 align이 된 관계를 나타낸다.
Implementation Details
모달리티의 각 인코더는 모두 Tranfromers 기반 모델을 사용.
- Image (Video): ViT
- Audio: mel-spectrogram으로 변환, ViT
- Thermal, Depth image: 1 channel image로 처리, ViT
- IMU signals: 관측치를 1D Convolution으로 처리, Transformers
- Text: CLIP의 text encoder (Transformers)
Experiments
Emergent zero-shot: 학습 과정에서 보지 못한 modality pair에 대한 zero-shot
Emergent zero-shot classification

- 각 modality를 텍스트로 분류했을 때의 성능 테스트. 나머지 모달리티와 text embedding 간의 align을 확인함.
- 각 benchmark의 SOTA에 비해 성능이 좋지 않지만, text embedding과 이미지 외의 모달리티 임베딩이 서로 align되어 있음을 확인.
Emergent zero-shot audio retrieval and classification
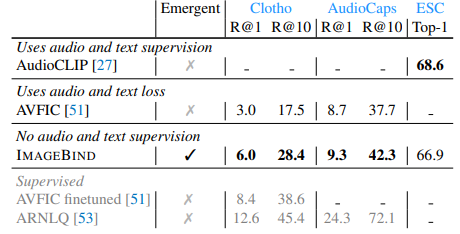
- 특히 Zero-shot text to audio retrieval and classification task에 성능이 좋음.
- emergent zero-shot임에도 불구하고 기존의 audio-specific supervision 모델보다 좋거나 비등한 성능을 보임.
Embedding space arithmetic

- 모달리티 임베딩 간 산술 연산을 통한 retireve 가능.
Object detection with audio queries

- Detic 모델의 CLIP 기반 text 임베딩을 ImageBind의 audio 임베딩으로 교체.
- audio embedding으로 이미지 내에서 object를 detection, segmentation함.
Reference
