논문 선정 이유
embedding model을 다루면서 다양한 모달리티를 표현할 수 있는 multimodal embedding에 관심이 생겼다.
2023년 5월 Meta에서 6가지 modalites에 대한 모델을 소개하는 IMAGEBIND라는 논문을 했는데, 이를 알아보기 앞서 multimodal에서 가장 유명한 연구 중 하나인 CLIP을 먼저 알아보기로 했다.
CLIP 간단 요약
CLIP은 OpenAI에서 2021년에 DALL-E와 함께 발표한 모델
DALLE-E: text -> image
CLIP: image -> text
CLIP은 아래 두 가지 개념을 아이디어로 활용
1. Vision Language Pre-trainig
: LLMs처럼 가공되지 않은 대량의 데이터를 학습하는 방법을 Vision에 적용한 학습 방법.
2. Natural Language Supervision
: 본 논문은 text-image pairs로부터 visual representation을 학습하는 것을 Natural Language Supervision이라는 이름으로 선언 (처음 나온 개념은 아님)
CLIP = 거대한 데이터(VLP) + pair repersentation 학습(NLS)
장점
1. crowd-sourced labeling보다 인터넷 긁어서 데이터의 scale을 키우는 것이 더 쉽다.
2. vision representation을 text representation과 연결지음으로써 downstream task에 transfer하기 용이해짐. (image retrieval, image captioning 등)
즉 CLIP(Contrastive Language-Image Pre-training)을 한 줄로 표현하자면,
다양하고 방대한 image와 text pair를 contrastive learning method로 pre-training한 것!
Learning Transferable Visual Models From Natural Language Supevision
- 2021년
- OpenAI
Introduction
- 이전 class label을 활용한 supervised learning은 semantic 정보를 잘 담아내지 못했기 때문에 image retrieval, image captioning, VQA 등 다양한 downstream tasks에 적용하기 쉽지 않았음.
- 따라서 매우 방대한 데이터를 학습하는 LLMs 학습 방법을 차용하여 4억개 가량의 raw pair data(image, text)를 Contrastive Learning함.
Main Method
스탠다드 이미지 모델은 image feature extractor와 linear classifier를 함께 학습을 시켰다면, CLIP은 text와 image pair를 예측하는 방법으로 image encoder와 text encoder를 학습함.
Contrastive pre-training
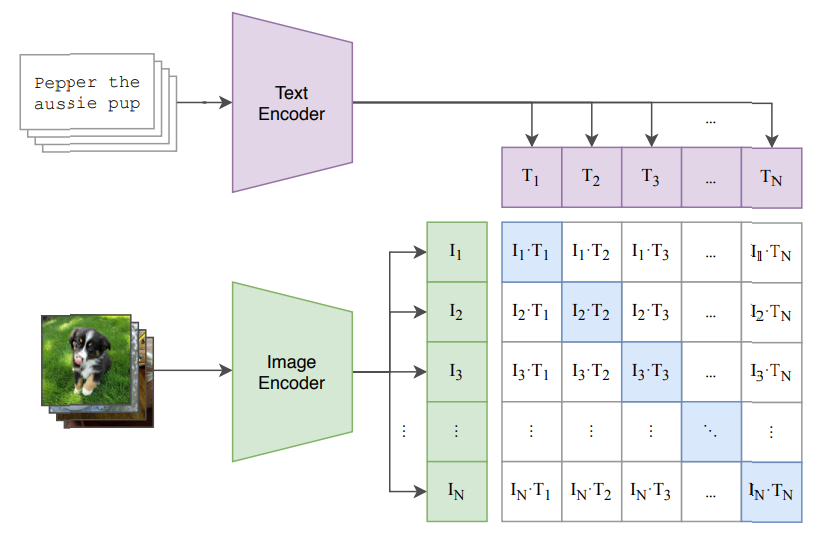
학습 방법
1. image encoder, text encoder를 통해 각 데이터를 인코딩
2. 같은 공간 상에 projection
3. cosine similarity 계산
4. cosine similarity의 CrossEntropy Loss를 통해 postive pairs의 유사도를 최대화, negative pairs의 유사도를 최소화하도록 cross modality 학습

downstream task transfer (zero-shot prediction)
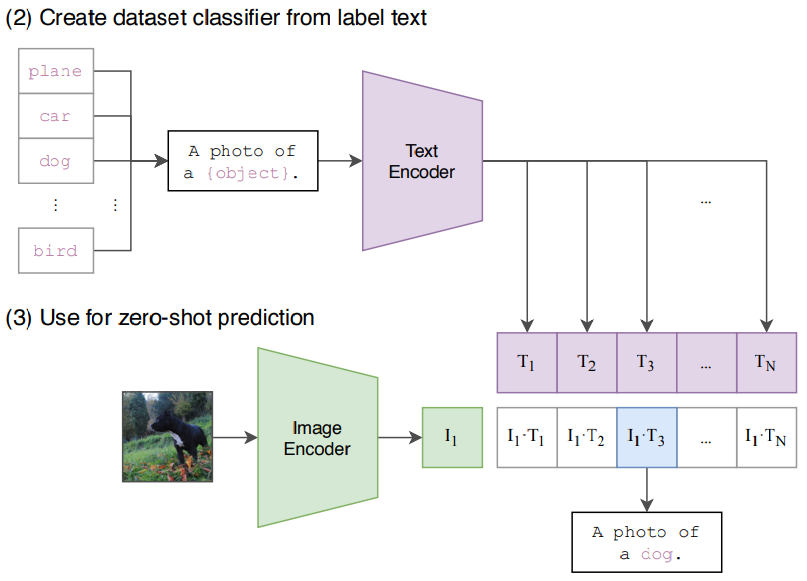
- 스크래치 학습에 사용되지 않은 데이터를 학습 과정없이 zero-shot으로 prediction 가능
- image encoder와 text encoder를 통해 나온 embedding의 dot-product가 가장 큰 것이 output이 됨.
prompt engineering
: 문장형으로 변형 후 text encoder에 입력
이전에는 image classification task의 class를 단일 라벨로 구성. (dog, plane, cat)
-> 문제점: 1) 다의성 문제(동음이의어) 2) 학습한 인터넷에서 긁은 데이터가 문장형으로 구성 3) semantic 정보 없음(context information X)
-> 해결: text prompt engineering을 통해 문장으로 표현함.
=> 이 간단한 방법을 추가함으로써 ImageNet 예측 accuracy가 1.3% 향상함.
=> 같은 의미의 다양한 프롬프트를 앙상블했더니 성능이 3.5% 더 올랐다고 함.
=> 즉, prompt engineering이 성능에 꽤 영향을 준다.
training details
- image encoder: 5 ResNets and 3 ViTs (일부 변형)
- text encoder: Transformers (일부 변형)
- minibatch size (32,768)
- ResNet model 중 가장 큰 모델(RN50x64)를 592개의 V100 GPU에서 학습하는데 18일 소요
- ViT-L/14 모델의 성능이 가장 좋았음.
Results
Image Classification Task
1. Zero-Shot vs. Zero-Shot
CLIP vs. Visual N-Grams
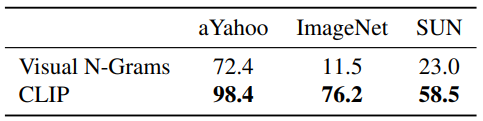
- Visual N-Grams(2017): 당시 zero-shot transfer를 할 수 있는 유일한 모델
2. Zero-Shot vs. fully-supervised model
CLIP vs. ResNet50
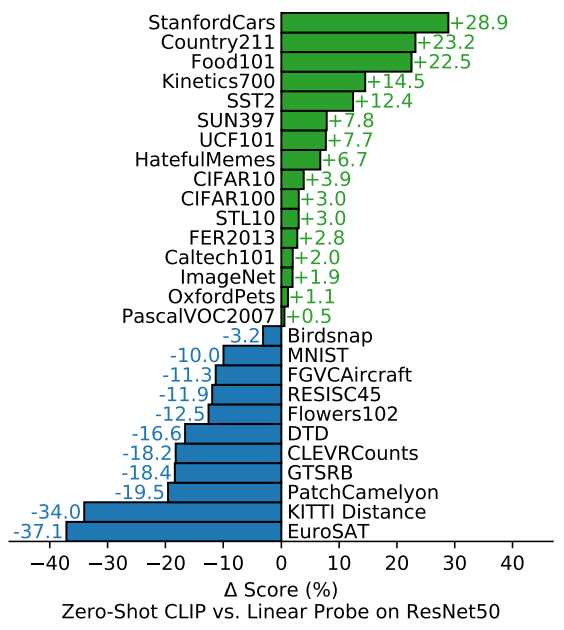
- zero-shot CLIP이 fully-supervised classifiers와 견줄 만큼의 성능을 보임.
- STL10 dataset의 경우, CLIP이 zero-shot만으로 SOTA 달성.
- video에서 action을 인식하는 데이터셋(Kinetics700, UCF101)에 대해 월등히 높은 성능
-> visual representation을 학습하며 동시에 verbs를 포함한 natural language representation을 연결해서 배울 수 있었기 때문이라고 해석. - 구체저, 복잡, 추상적인 이미지 데이터에 대해서는 성능이 좋지 않았음. (위성사진, medical)
학습 데이터가 인터넷에서 긁어온 이미지라 그렇다는 해석
3. Zero-Shot vs. Few-Shot
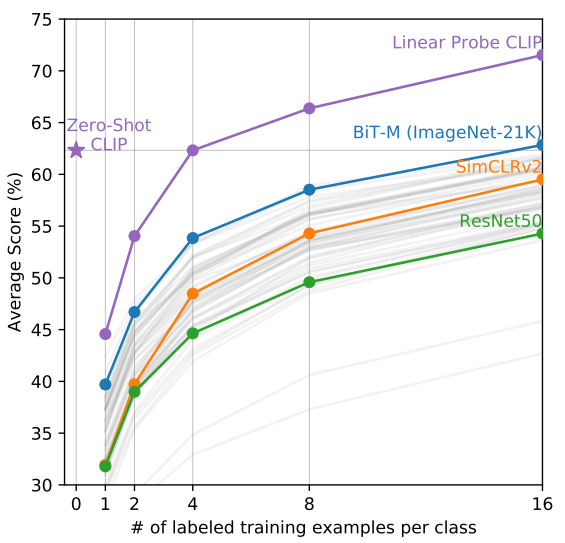
- Few-Shot을 적용했을 때 CLIP의 성능이 월등히 가장 높음
- training sample이 적을 때는 Zero-Shot CLIP이 나머지 Few-Shot 적용 모델보다 성능이 좋음.
이유: Zero-Shot에서는 dot product로 결과를 냄. few-shot에서는 linear layer를 덧붙여서 학습을 시키기 때문에 training example가 적을 때는 성능이 떨어졌다가 충분히 주어지면 zero-shot보다 더 높은 성능을 보이게 되기 때문이다.
Representation
4. Robustness to natural distribution shift

ImageNet 데이터셋에 natural distribution shift를 준 variant 데이터셋들에 대해 ImageNet을 학습한 ResNet101보다 높은 정확도를 보임.
즉, generalization 성능이 뛰어나다.
limitations
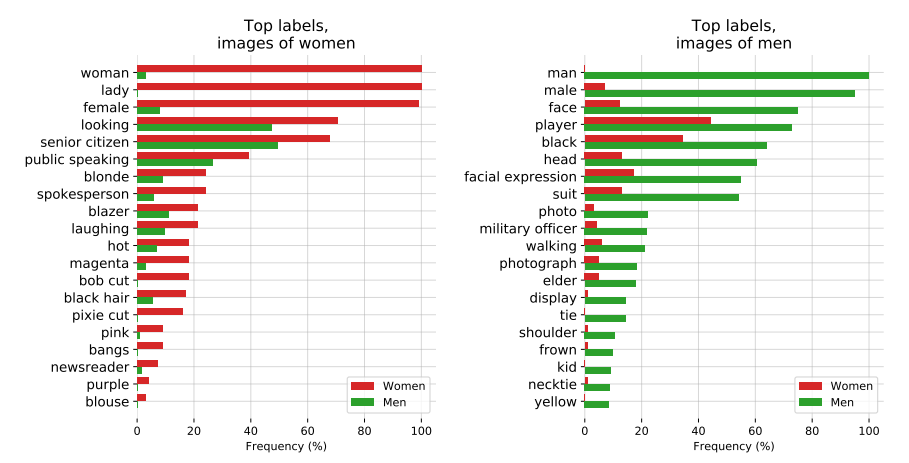
인터넷의 방대한 데이터를 학습하다보니 bias 문제가 있음. (성별에 따른 편향 등)
Reference
paper: https://arxiv.org/pdf/2103.00020.pdf
Blog: https://openai.com/blog/clip/
Code: https://github.com/openai/CLIP
https://www.youtube.com/watch?v=T9XSU0pKX2E
