
오차행렬이란
오차행렬(confusion matrix, 혼동행렬)은 학습된 분류 모델이 예측을 수행하면서 얼마나 헷갈리고(confused) 있는지를 함께 보여주며 이진 분류에서의 성능 지표로 자주 사용됩니다.
분류 모델이 예측을 수행하면서 헷갈린다의 의미는 어떠한 유형의 예측 오류가 발생하는지를 뜻합니다.
오차행렬이 사용되는 이유
오차행렬(confusion matrix, 혼동행렬)은 평가지표라고도 하는데, 이 평가지표를 사용하는 이유는 "모델을 평가하기 위해서 사용"합니다.
모델을 사용해서 예측을 하고 어느 관점에서 볼지를 정하는 것이 평가지표입니다.
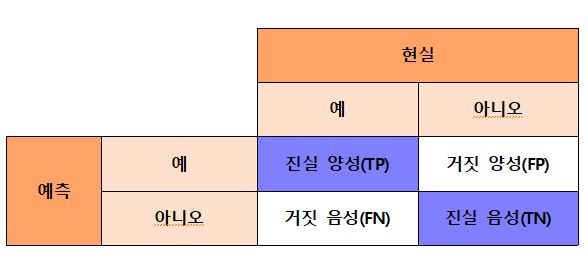
비가 온다는 것을 예시로 한다면
- 진실양성(TP) : 현실에서 비가 왔다 / 모델이 비가 온다고 예측을 했다
- 거짓양성(FP) : 현실에서 비가 안 왔다 / 모델이 비가 온다고 예측했다
- 거짓음성(FN) : 현실에서 비가 왔다 / 비가 안 온다고 예측했다
- 진실음성(TN) : 현실에서 비가 안 왔다 / 비가 안 온다고 예측했다
.
정확도, 정밀도, 재현율
오차행렬(confusion matrix, 혼동행렬)에서 정확도, 정밀도, 재현율을 알 수 있습니다.
- 정확도 ( Accuracy )
-정확도는 모든 관찰 중 정확한 예측의 백분율
-정확한 예측 / 모든 경우
-( TP + TN ) / ( TP + FP + TN + FN )
- 정밀도 ( Precision )
-예측을 기준으로 계산
-양성(TP+FP)으로 예측되는 경우 중 진실양성(TP)의 비율
-예측이 '예' 중에서 얼마나 잘 맞혔는지 보는 것이 정밀도
-(진실양성) / (총예측양성)
-TP / ( TP + FP )
- 재현율 ( Recall )
-실제 상황을 기준으로 계산
-리콜은 양성사례(TP+FN) 중 진실양성(TP)의 비율
-(진실양성) / (총 실제양성)
-TP / ( TP + FN )
.
그렇다면 정확도가 높다고 모델의 성능이 좋은걸까?
꼭 그렇지는 않습니다. 왜냐하면
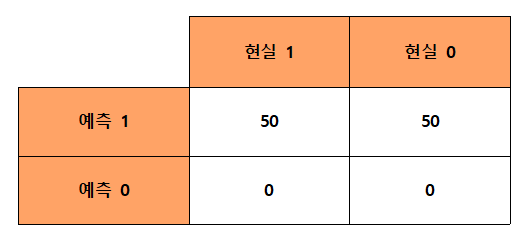
위와 같은 경우처럼 항상 'Yes'라고만 예측하는 데이터처럼 데이터의 편향이 있을 수 있기 때문입니다.
