NAS에 대한 논문 https://jmlr.org/papers/volume20/18-598/18-598.pdf 을 리뷰해보도록 하겠습니다.
개요
딥러닝은 지난 몇 년 동안 이미지 인식, 음성 인식 및 기계 번역과 같은 다양한 작업에서 놀라운 발전을 가능하게 했습니다.
이러한 진보를 위한 중요한 측면 중 하나는 새로운 신경 구조입니다.
현재 사용되는 아키텍처는 대부분 전문가에 의해 수동으로 개발되었으며,
이는 시간이 많이 걸리고 오류가 발생하기 쉬운 프로세스입니다.
이 때문에 자동화된 신경 아키텍처 검색 방법에 대한 관심이 높아지고 있습니다.
소개할 논문에서는 이 연구 분야의 기존 작업에 대한 개요를 제공하고 검색 공간, 검색 전략 및 성능 추정 전략의 세 가지 차원에 따라 분류하여 리뷰해보도록 하겠습니다.
1. NAS 소개
- NAS는 AutoML의 한 분야이며, 이미지 분류, 객체 탐지, semantic segmentation 등에서 이미 수동 설계된 아키텍쳐보다 능가하는 것을 보여주었습니다.
하이퍼 파라미터 최적화(Feurer and Hutter, 2019) 및메타 학습(Vanschoren, 2019)과
상당히 겹친다.- 리뷰할 논문에서는
NAS의 방법을검색 공간,검색 전략및성능 추정 전략의 세 가지 차원에 따라 분류한다.
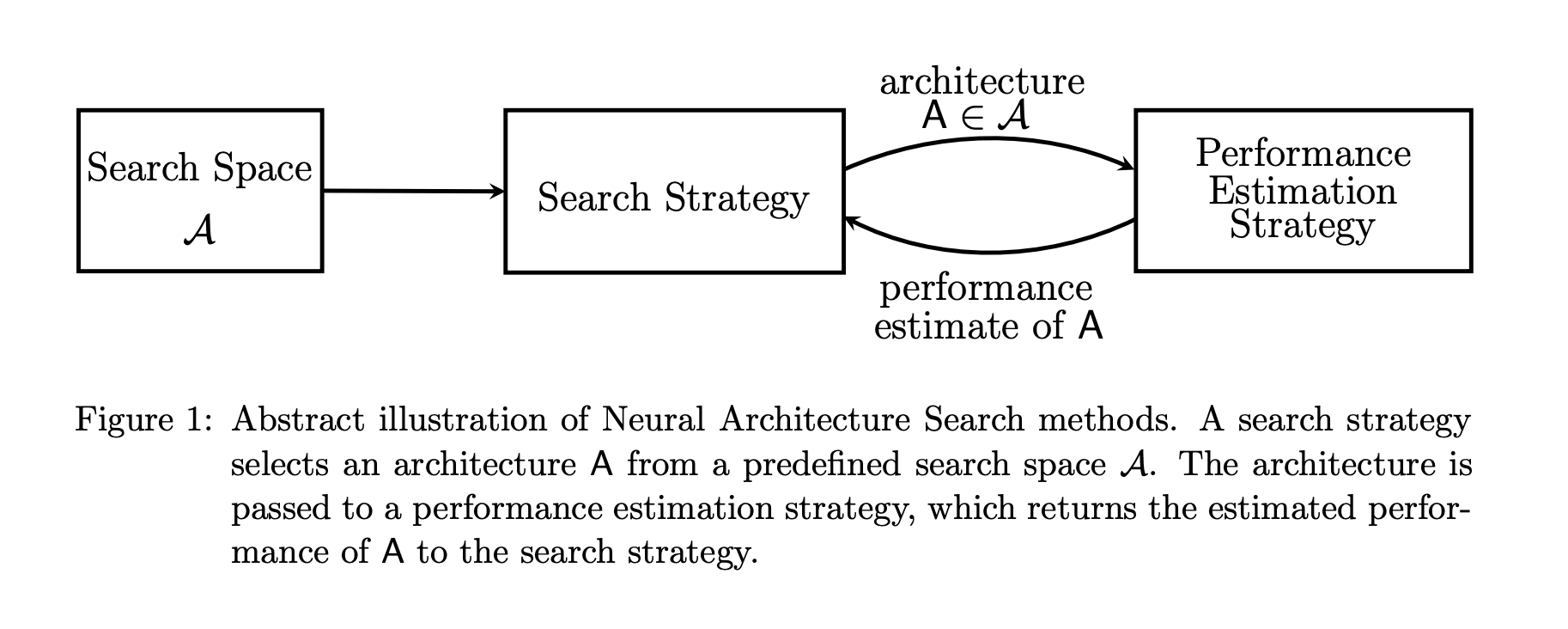
-
Search Space
: 검색 공간은원칙적으로 나타낼 수 있는 아키텍처를 정의합니다.
즉, 문제를 해결할 수 있는 아키텍처들이 있는 곳! 이라고 생각하면 쉬울 것 같습니다.
작업에 적합할 것 같은 아키텍처를 추려내면 검색 공간을 줄일 수는 있으나,
이 또한 전문가의 인간의 판단이 개입할 가능성이 있습니다!
이는 현재의 인간 지식을 뛰어넘는 새로운 건축 구성 요소를 발견하는 것을 방해할 수 있습니다. -
Search Strategy
: 검색 전략은 말 그대로 검색 방법입니다. 최적의 아키텍처를 선택하는 것이 검색 전략의 좋은 알고리즘입니다.
검색 전략은exploration-exploitation trade-off에 빠질 수 있는데,
exploration은 전체적인 부분을 탐색하는 것이고,exploitation은 특정 부분에 집중하여 탐색하는 것입니다.
따라서Search Strategy는 exploration과 exploitation 을 둘 다 잘해야 합니다. -
Performance Estimation Strategy
: NAS의 목적은 일반적으로 보이지 않는 데이터에서높은 예측 성능을 달성하는 아키텍처를 찾는 것입니다.
성능 추정은 이 성능을 추정하는 프로세스를 의미합니다.
가장 간단한 옵션은 데이터에 대해아키텍처의 표준 교육 및 검증을 수행하는 것이지만,
안타깝게도 이 방법은 계산 비용이 많이 들고 탐색할 수 있는 아키텍처의 수를 제한합니다.
최근 연구는 이러한 성능 추정의 비용을 줄이는 방법을 개발하는 데 초점을 맞추고 있습니다.
2. Search Space
Search Space는 NAS 접근 방식이 원칙적으로 발견할 수 있는 신경 구조를 정의합니다!
이제 최근 작업의 공통 Search Space에 대해 논의합니다.
1. 비교적 단순한 Search Space
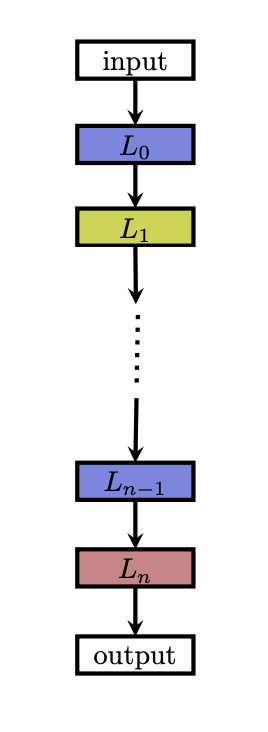
체인 구조화된 신경망 아키텍처 A(chain-structed neural network architecture)는 n개의 레이어의 Sequence 기록될 수 있는데, 여기서 i번째 레이어 Li은 레이어 i - 1로부터 입력을 받고 출력은 레이어 i + 1에 대한 입력, 즉 A = Ln x ... x L1xL0의 입력으로 사용됩니다.
각 레이어마다 layer 수, Operation 종류, 하이퍼 파라미터 등을 가지고 있습니다.
2. 최근의 Search Space ( Multi-branch networks )
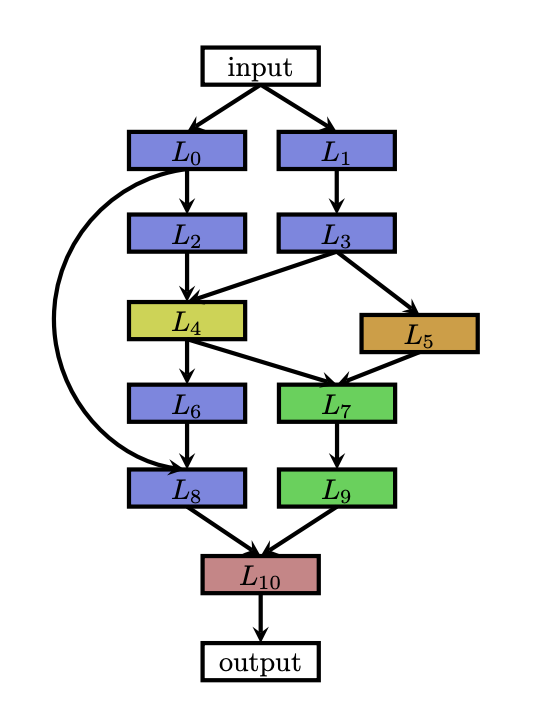
NAS에 대한 최근의 연구에는 위 그림에 나온 것처럼 복잡한 다중 지점 네트워크를 구축할 수 있는, 수작업으로 만들어진 아키텍처에서 알려진 최신 설계 요소가 포함되어 있습니다. (예 : 스킵 연결 )
이러한 기능을 사용하면 훨씬 더 많은 자유도를 얻을 수 있습니다.
3. cell Search Space
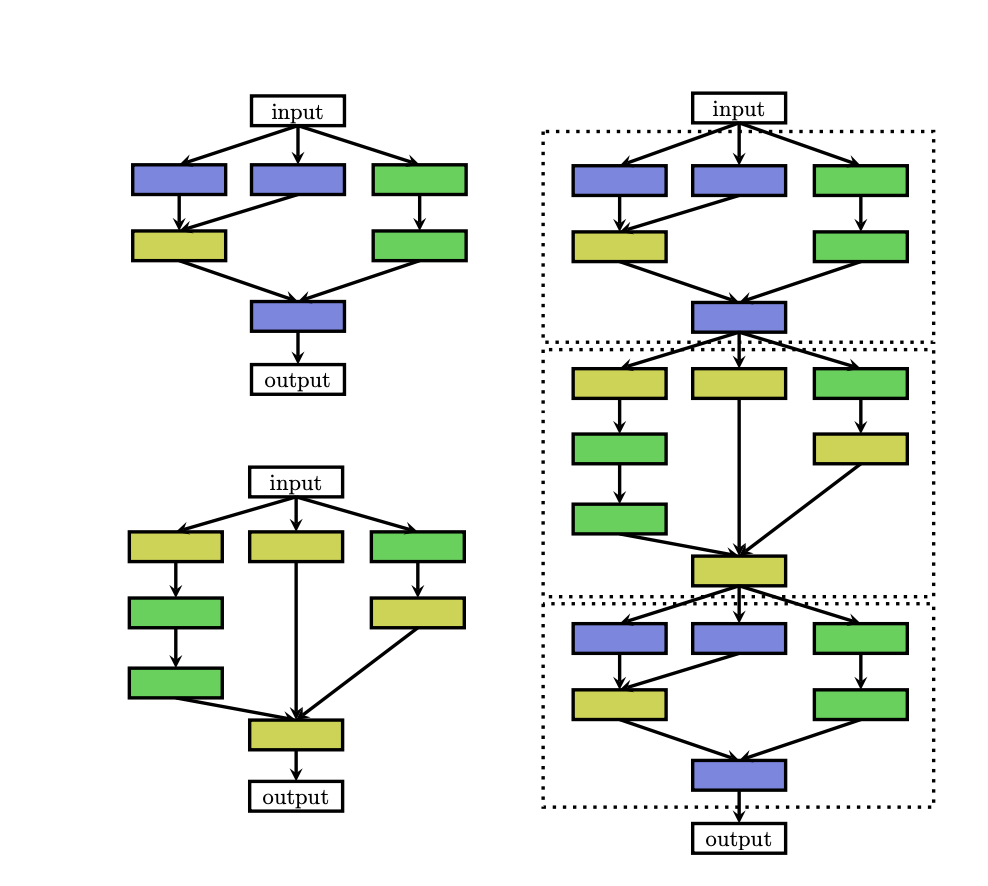
- VGG, ResNet 등은
repeated motif방법으로 모델 구성 - Cell Search Space : 하나의 Cell (덩어리) 를 NAS를 통해 탐색. Cell을 반복적으로 쌓으면서 모델 구성하는 방법입니다.
- 장점
- 탐색하는 범위가 줄어듭니다.
- 다른 데이터에 쉽게 적용할 수 있습니다.
그러나, cell Search Space를 사용할 때는 또 하나의 고려 사항이 생깁니다.
얼마나 Cell을 쌓을 지?, 어떻게 연결해야 할 지?에 대한 고려 사항이 생기겠죠 !
4. Search Strategy
random search, 베이지안 최적화, evolutionary methods, 강화 학습(RL) 및 그레이디언트 기반 방법을 포함하여 신경 아키텍처의 공간을 탐색하는 데 다양한 검색 전략을 사용할 수 있습니다.
-
evolutionary 알고리즘은 이미 수십 년 전부터 전문가들이 Neural Network를 발전시키기 위해 사용하였습니다. -
Bayesian optimization는 2013년 이후 NAS에서 몇 가지 초기 성공을 거두어 최첨단(SOTA) 비전 아키텍처로 앞장섰고, 데이터 증강 없이 CIFAR-10에서 가장 좋은 성능을 보여주었습니다.
Bayesian optimization 은 인간 전문가와의 경쟁 데이터 세트에서 승리한 최초의 자동 조정 신경망이 되었습니다.
- Reinforcement Learning 이 최근에는 NAS에서 주목받는 방법 중 하나입니다.
- Action :
Architecture 생성 - Reward :
Architecture Performance - 환경과의 interaction이 없으므로
multi-armed bandit problem으로 생각할 수도 있습니다.
- Action :
- Neuro evolutionaly
- 과거에는 아키텍처와 파라미터를 모두 진화 알고리즘을 통해 구했습니다.
- 현재는 파리미터는 SGD(경사하강법)을 사용하여 구하며, 아키텍처만 진화 알고리즘을 사용합니다.
- model population -> evaluation -> offspring 생성 (mutation) 의 방식으로 진행됩니다.
- mutation 은 layer를 생성/삭제, 하이퍼 파라미터 변경 , skip connection 등이 있습니다.
- RL VS Neuro evolutinaly
- RL과 evolution 성능은 유사합니다.
- 그러나 anytime performance가 evolution이 더 좋고 더 작은 모델을 잘 찾습니다.
5. Performance Estimation Strategy
The search strategies에서 최적의 아키텍처 A를 찾기 위한 가장 간단한 방법은
A 를 train data로 Train하고, validation data로 평가하는 방법입니다.
그러나, 각 아키텍처를 처음부터 다시 평가하도록 하는 것은 NAS의 경우 GPU가 수천 일동안 계산해야 할 일이 자주 발생할 것입니다.
이것을 해결하기 위해서 full training 이후에, 실제 수행의 lower fidelities를 기준으로 성능을 추정할 수 있습니다.
lower fidelities에는
짧은 training 시간, 데이터의 일부분만 training, 저해상도 이미지를 이용하여 training, layer별 적은 filter들과 적은 cell들 설정
등이 있습니다.
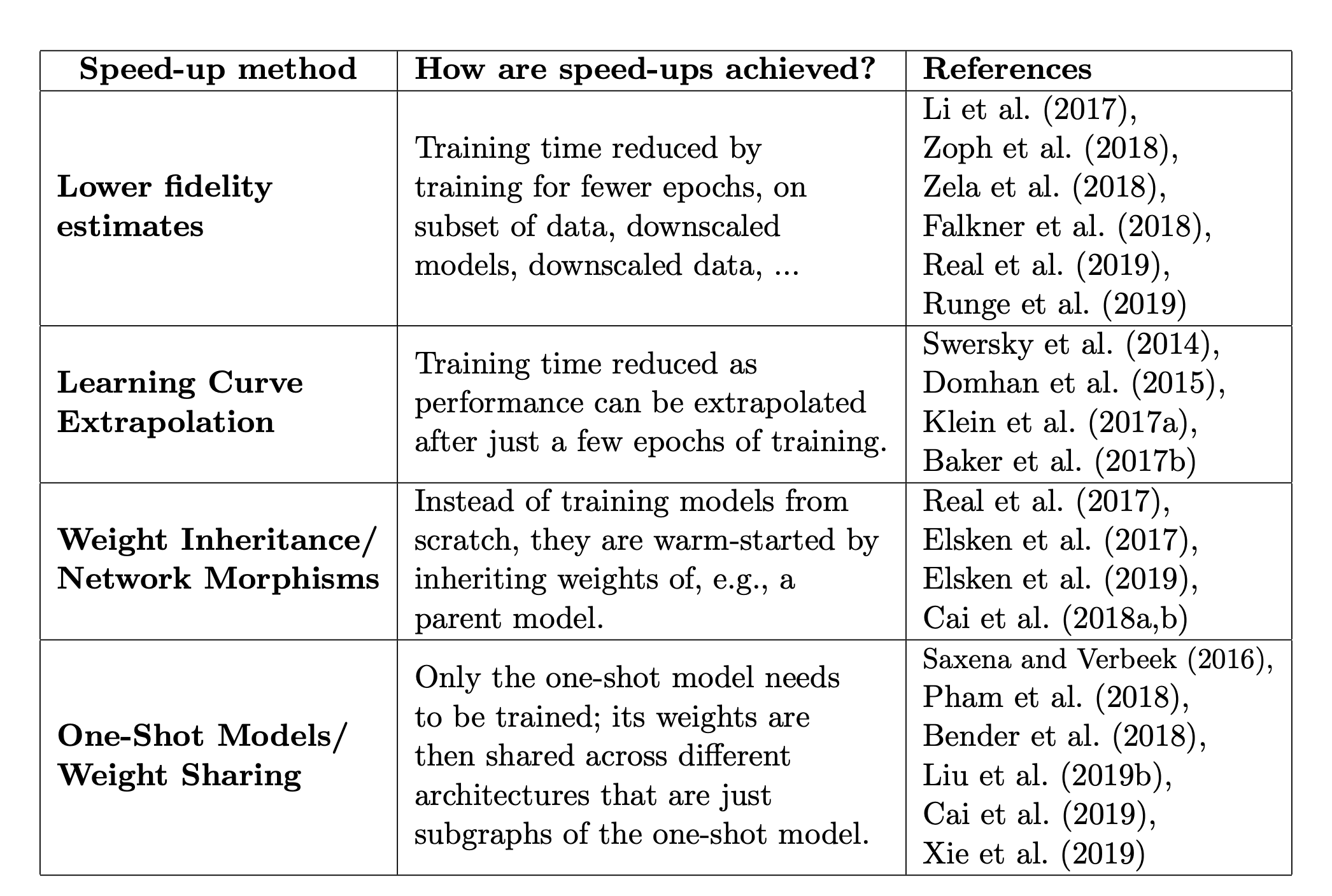
-
위의 표는 NAS의 평가 성능을 높이는 여러가지 방법들입니다.
-
lower fidelities근사치는 계산 비용을 감소시키지만, 일반적으로 성능이 과소평가되기 때문에 추정치에 편향을 초래하기도 합니다.
Learning Curve Extrapolation
Learning Curve Extrapolation을 기반- 초기 학습 곡선을 추론하고, 아키텍처 검색 프로세스의 속도를 높이기 위해 성능이 저하될 것으로 예상되는 곡선을 종료할 것을 제안합니다.
- 어떤 부분 학습 곡선이 가장 유망한지를 예측하기 위해 아키텍처의
hyperparameters를 고려합니다.
Weight Inheritance / Network Morphisms
- 가중치 값을 다른 아키텍쳐에서 Train 된 가중치를 사용하여 아키텍처를 초기화 (train된 가중치를 사용)
network morphisms라고 하며, network에 의한 기능을 그대로 두고 아키텍처를 수정할 수 있으므로 빠릅니다.- strict한
network morphsims는 아키텍처를 더 크고 복잡하게 만들 위험성이 있음. - 아키텍처를 감소시킬 수 있는
approximate network morphisms을 사용하여 줄일 수 있습니다.
one-shot Architecture Search
- 1개의 큰 아키텍처를 만든 뒤 큰 아키텍처 안에서 sub-아키텍처들로 취급합니다.
- sub-architecture들끼리 가중치를 공유
