🤓오늘의 공부 주제: Apache kafka, Redis, hexagonal architecture🤓
Q. Apache kafka란 무엇인가?
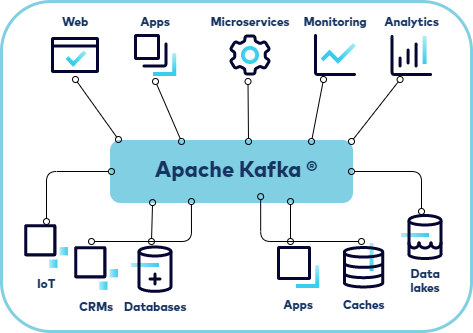
A. Apache kafka란 웹사이트, 어플리케이션, 센서 등에서 취합한 데이터를 스트림 파이프라인을 통해 실시간으로 관리하고 보내기 위한 분산 스트리밍 플랫폼이다.
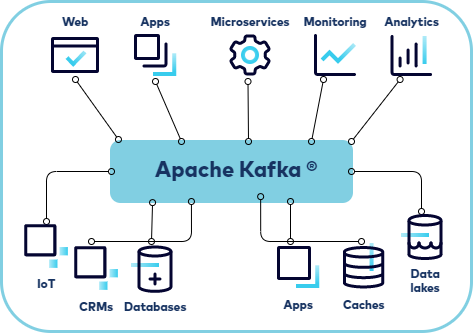
데이터 생성 어플리케이션과 소비 어플리케이션 간의 중재자 역할로 데이터의 전송 제어, 처리, 관리 역할을 담당한다. 어플리케이션과 서비스간의 비동기 데이터 교환을 용이하게 하고 하루 수 조개의 이벤트 처리를 가능하게 한다.
kafka의 특징
- 여러 전달자가 동시에 메시지 전송 가능. 반대로 여러 소비자가 동시에 메세지 읽기 가능.
- 전송된 메세지는 일정기간 파일 형태로 저장되어 처리 속도, 장애 복구 가능. 한 노드가 메세지 전송하면 전달자와 소비자를 중재하는 브로커에서 전달자가 전달한 메세지를 브로커의 동작에 영향을 주지 않고 처리 속도 및 장애 복구를 유지하도록 해 일정 기간 동안 파일 형태로 저장.
- 시스템 트래픽이 높아지면 브로커를 추가해 처리량을 늘릴 수 있음.
- 처리 속도 저하의 경우 소비자나 생산자를 추가해 처리량을 느릴 수 있음.
- 컨슈머를 그룹으로 묶어 프로듀서에서 보내는 속도와 읽는 속도의 균형을 맞출 수 있음.
활용 기업 및 방안
트위터 - 사용자에게 트윗 보내고 받는 방법에 사용
링크드인 - 이용자의 사이트 활동 데이터 분석
넷플릭스 - 실시간 모니터링 및 이벤트 처리
💡요약💡
장점: 빠른 속도로 대용량의 데이터 처리 용이. 낮은 지연 시간으로 메세지 빠르게 처리. 시스템 확장 용이. 전달할 메세지를 파일로 저장해 안정성과 신뢰성이 높음.
단점: 모니터링 및 관리 도구가 불편하여 메세지 조정이 필요한 경우 성능이 크게 저하될 수 있음. 클러스터의 대기열 수가 증가하면 상태적으로 느리게 동작하는 경우가 있음.
Q. Redis란 무엇인가?
A. Redis란 remote dictionary server의 약자로 인메모리 데이터 저장소. 주로 데이터베이스, 캐싱 및 메세지 브로커의 역할을 수행하는 오픈소스 소프트웨어.
Redis의 특징
- 인메모리 데이터 저장: 매우 빠른 읽기 및 쓰기 속도. 캐싱에 유리
- 다양한 데이터 구조 지원: 문자열, 해시맵, 리스트, 셋, 정렬된 집합과 같은 다양한 구조 지원하여 용도에 맞게 사용 가능
- 영속성 지원: 메모리에 데이터를 저장하여 시스템 재시작 후에도 데이터 유지 가능.
- pub/sub 메시징 시스템: publish/subscribe 매커니즘을 지원하여 메시지 브로커로 사용 가능. 다수의 클라이언트가 메세지를 발행하고 수신 가능.
💡요약💡
장점: 빠른 속도, 단순하고 간결한 인터페이스, 다양한 데이터 구조 지원, 높은 가용성 및 확장성, 오픈소스
단점: 데이터 크기 제한, 영속성 저장하는 부분이 제한적, 단일 스레드 모델, 복잡한 쿼리 지원 부족, 오프라인 백업 어려움, 설정 및 튜닝이 필요
Q. kafka와 Redis는 어떤 차이가 있는가?
A. redis는 데이터를 실시간으로 저장하고 읽기 위한 인메모리 데이터베이스이며, kafka는 대규모 데이터를 분산 스트리밍 처리를 위한 플랫폼으로 각기 다른 목적과 사용 사례를 가진다.
Redis는 주로 인메모리 데이터베이스로 사용. 데이터를 메모리에 저장하고, 다양한 데이터 구조를 지원하여 빠른 읽기 및 쓰기 작업에 특화. 주로 캐싱, 세션 저장, 메시지 브로커 등 다양한 용도로 사용. Redis는 데이터를 영속적으로 저장하는 기능도 제공하지만, 주로 인메모리 데이터를 활용한 빠른 데이터 액세스에 중점.
반면, Apache Kafka는 데이터의 실시간 스트리밍을 처리하기 위한 플랫폼. 주로 대량의 데이터를 신속하게 처리하고 여러 시스템 간에 데이터를 실시간으로 전송하는 데 사용. Kafka는 대용량의 데이터를 안정적으로 분산 및 스트리밍 처리할 수 있는 기능을 제공하며, 이벤트 소싱, 로그 집계, 데이터 허브 등 다양한 사용 사례에서 활용. 하지만 Kafka 자체는 데이터를 영속적으로 저장하는 데이터베이스로 사용되는 것이 아니라, 데이터를 안정적으로 전달하고 스트리밍 처리하는 역할.
- 데이터 저장 방식의 차이: redis는 인메모리 방식이므로 메모리에 저장하고 영속적인 데이터 저장 지원. kafka는 대용량 데이터를 디스크에 영속적 저장하고 분산 로그로 활용.
- 활용 목적과 범위: redis가 캐싱, 세션 저장, 실시간 분석과 같은 인메모리 데이터 스토어인 반면 kafkasms 대규모 데이터 스트리밍 및 이벤트 처리에 사용.
- 메시징 모델: redis는 pub/sub모델 지원. kafka는 고성능 메시지 큐 및 메시지 브로커로 사용.
- 저장구조: redis는 주로 키-값 형태로 저장하나 다양한 구조를 지원. kafka는 토픽과 파티션으로 이루어진 로그 기반의 저장 구조.
Q. Hexagonal architecture란 무엇인가?
A. Hexagonal architecture란 유연하고 확장 가능한 소프트웨어 디자인을 일컫는다.

Hexagonal architecture의 특징
주요 목표는 응용 프로그램의 비즈니스 로직을 외부로부터 격리시켜 유연하고 테스트하기 쉬운 구조로 만드는 것이다. 핵심 비즈니스 로직은 중앙의 도메인에 위치하며 입출력 포트와 어뎁터를 통해 외부와 소통한다.
가장 대중적인 아키텍처는 3계층으로 비즈니스 로직, 데이터 엑세스, 프레젠테이션 계층으로 구성. 비즈니스 로직이 서비스 클래스에 있고 리포지토리 인터페이스를 통해서 데이터 엑세스 계층과 소통.
3계층 아키텍처 구현 예시)
// UserService.java
public class UserService {
private UserRepository userRepository;
public UserService(UserRepository userRepository) {
this.userRepository = userRepository;
}
public void createUser(String name, String email) {
User user = new User(name, email);
userRepository.save(user);
}
}
// UserRepository.java
public interface UserRepository {
void save(User user);
}
// UserRepositoryImpl.java
public class UserRepositoryImpl implements UserRepository {
public void save(User user) {
// 데이터베이스에 사용자 저장
}
}3계층 아키텍처 Kafka 적용 예시)
// KafkaProducer.java
public class KafkaProducer {
public void send(User user) {
// 카프카에 사용자 정보 전송
}
}
// UserService.java
public class UserService {
private UserRepository userRepository;
private KafkaProducer kafkaProducer;
public UserService(UserRepository userRepository, KafkaProducer kafkaProducer) {
this.userRepository = userRepository;
this.kafkaProducer = kafkaProducer;
}
public void createUser(String name, String email) {
User user = new User(name, email);
userRepository.save(user);
kafkaProducer.send(user);
}
}반면, 헥사고날 아키텍쳐에서는 별도의 usecase 인터페이스를 통해서 비즈니스 로직 정의 후 impl클래스로 구현. 레포지토리 어뎁터가 레포지토리 인터페이스를 구현해서 외부와 소통. 따라서 비즈니스 로직과 외부 요소를 격리시켜 유연성과 테스트 용이성을 지원. kafka와 같은 외부 시스템을 연결하면 장점이 돋보이게 됨. 기존 3 tier architecture에서는 service가 kafka에 의존성을 가지지만 hexagonal architecture의 경우 외부 시스템과의 의존성 분리를 통해 시스템 변경 시에도 비즈니스 로직 영향이 최소화 된다.
헥사고날 아키텍쳐 구현 예시)
// CreateUserUseCase.java
public interface CreateUserUseCase {
void createUser(String name, String email);
}
// CreateUserUseCaseImpl.java
public class CreateUserUseCaseImpl implements CreateUserUseCase {
private UserRepository userRepository;
public CreateUserUseCaseImpl(UserRepository userRepository) {
this.userRepository = userRepository;
}
public void createUser(String name, String email) {
User user = new User(name, email);
userRepository.save(user);
}
}
// UserRepository.java
public interface UserRepository {
void save(User user);
}
// UserRepositoryAdapter.java
public class UserRepositoryAdapter implements UserRepository {
public void save(User user) {
// 데이터베이스에 사용자 저장
}
}헥사고날 아키텍쳐 Kafka 적용 예시)
// OutputPort.java
public interface OutputPort {
void sendMessage(User user);
}
// KafkaAdapter.java
public class KafkaAdapter implements OutputPort {
private KafkaProducer kafkaProducer;
public KafkaAdapter(KafkaProducer kafkaProducer) {
this.kafkaProducer = kafkaProducer;
}
public void sendMessage(User user) {
kafkaProducer.send(user);
}
}
// CreateUserUseCaseImpl.java
public class CreateUserUseCaseImpl implements CreateUserUseCase {
private UserRepository userRepository;
private OutputPort outputPort;
public CreateUserUseCaseImpl(UserRepository userRepository, OutputPort outputPort) {
this.userRepository = userRepository;
this.outputPort = outputPort;
}
public void createUser(String name, String email) {
User user = new User(name, email);
userRepository.save(user);
outputPort.sendMessage(user);
}
}💡요약💡
장점: 유연성, 테스트 용이성(비즈니스 로직 독립적 테스트 가능), 유지보수성
단점: 구현 복잡성(포트와 어뎁터를 구성하고 관리), 초반 개발 시간 증가(처음 구축시)
