BERT
Bidirectional Encoder Representations form Transformer
Abstract
- unlabeled data로 학습시킨 후, 특정 task를 가진 labeled data로 transfer learning 하는 모델
- 이전 모델의 문제점
-
shallow bidirectional한 접근 방식
-
unidirectional한 접근 방식
→ language representation이 부족
-
- network 붙일 필요 없이 BERT 자체의 fine-tuning → SOTA 달성
Introduction
- Language model pre-training 방식
- feature-based approach
- 특정 task를 수행하는 network에 pre-trained language representation을 추가적인 feature로 제공합니다.
- 대표적인 모델로는 ELMo가 있습니다.
- fine-tuning approach
- task-specific한 parameter를 최대한 줄이고, pre-trained된 parameter들을 downstream task 학습을 통해 조금만 바꿔주는(fine-tuning) 방식입니다.
- 대표적인 모델로는 Generative Pre-trained Transformer(OpenAI GPT)가 있습니다.
- feature-based approach
- BERT의 pre-training
- Masked Language Model(MLM)
- input에서 무작위하게 몇개의 token만을 mask
- Transformer 구조에 넣어 context만을 보고 mask된 단어 예측
- next sentence prediction
- 두 문장을 pre-training시에 같이 넣어줘서 두 문장이 이어지는 문장인지 아닌지 맞추는 것
- pre-training시에는 50:50 비율로 실제로 이어지는 두 문장과 랜덤하게 추출된 두 문장을 넣어줘서 BERT가 맞추게 시킵니다
- Masked Language Model(MLM)
Model Architecture
-
BERT는 transformer 중에서도 encoder 부분만을 사용합니다.
-
BERT는 모델의 크기에 따라 base 모델과 large 모델을 제공합니다.
- BERT_Base : L=12, H=768, A=12, Total Parameters = 110M
- OPENAI의 GPT 모델과의 차이점은 무엇일까?
open ai의 gpt와 hyper parameter가 동일합니다. 저자는 model의 pre-training concept를 바꿔주는 것만으로도 훨씬 높은 성능을 보여줄 수 있다고 했습니다.
- OPENAI의 GPT 모델과의 차이점은 무엇일까?
- BERT_Large : L=24, H=1024, A=16, Total Parameters = 340M
- L : transformer block의 layer 수,
H : hidden size,
A : self-attention heads 수,
feed-forward/filter size = 4H
- L : transformer block의 layer 수,
- BERT_Base : L=12, H=768, A=12, Total Parameters = 110M
Input Representation
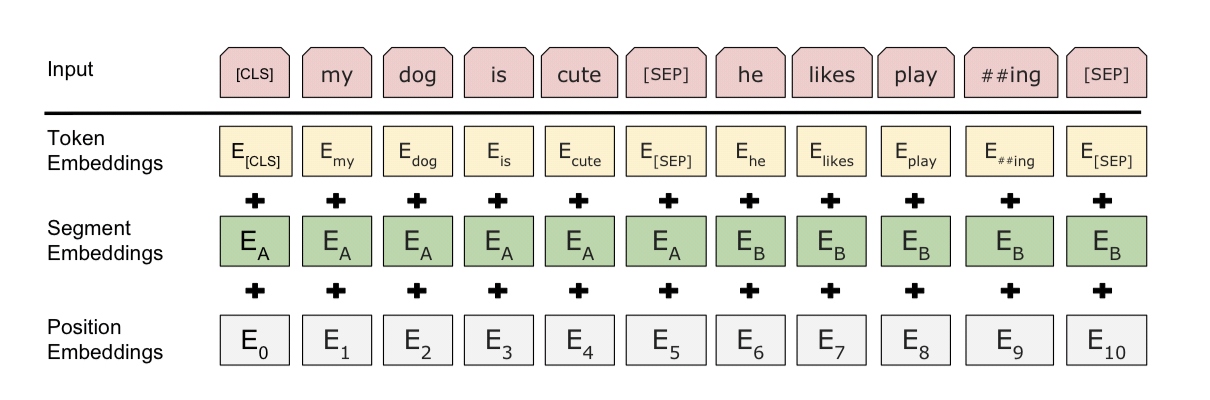
-
3가지 embedding으로 이루어짐
- WordPiece Embedding
- Position Embedding
- Segment
-
작동 방식
- CLS token으로 문장 시작
- classifier을 붙이면 단일 문장, 연속된 문장의 classification을 쉽게 할 수 있음
(classification이 아닐 시 token 무시) - sentence pair은 합쳐져서 single sequence로 입력
- 문장 구분을 위해서는 SEP 토큰을 사용하고, Segment embedding을 사용하여 앞 문장에는 sentence A emvedding, 뒤 문장에는 sentence B embedding을 더해줌
- 문장이 하나일 겨우, sentence A embedding만 사용.

배움의 개발자