
Paper : Mitigating Gender Bias in Natural Language Processing: Literature Review (Sun et al., ACL 2019)
Abstract
자연어 처리(NLP)와 기계 학습(ML) 도구가 인기를 끌면서, 이들이 사회적 편견과 고정 관념을 형성하는 데 어떤 역할을 하는지 인식하는 것이 점점 더 중요해지고 있다. NLP 모델은 다양한 으용 프로그램을 모델링하는 데 성공했지만, 텍스트 코퍼스에서 발견된 성별 편견을 전파하거나 심지어 증폭시킬 수 있다. 인공지능의 편향에 대한 연구는 새로운 것은 아니지만, NLP에서 성별 편향을 완화하는 방법은 아직 초기 단계에 있다. 본 논문에서는 NLP에서 성별 편향을 인식하고 완화하는 현대적인 연구를 검토한다. 우리는 네 가지 표현 편향 형태에 기반한 성별 편향을 논의하고, 성별 편향을 인식하는 방법을 분석한다. 또한 기존의 성별 편향 완화 방법의 장단점을 논의한다. 마지막으로, NLP에서 성별 편향을 인식하고 완화하기 위한 향후 연구에 대해 논의한다.
이 논문은 NLP에서의 성별 편향에 대한 인식과 완화를 다루고 있다. NLP 모델은 성별 편견을 텍스트 데이터에서 전파하고 증폭시킬 수 있으며, 이에 대한 인식과 완화를 위한 연구가 중요하다. 논문에서는 네 가지 표현 편향 형태에 기반한 성별 편향을 논의하고, 성별 편향을 인식하는 방법을 분석한다. 또한 기존의 성별 편향 완화 방법의 장단점을 검토하며, 앞으로의 연구 방향에 대해 논의한다. 이를 통해 NLP에서 성별 편향을 인식하고 오나화하기 위한 현대적인 연구 동향을 제시한다.
Introduction

이 논문은 NLP 시스템에서의 성별 편향에 대해 다루고 있다. 성별 편견은 NLP 시스템의 다양한 부분에서 나타날 수 있으며, 이는 훈련 데이터, 리소스, 미리 훈련된 모델 및 알고리즘 등에 영향을 미칠 수 있다. 이러한 성별 편향은 NLP 시스템이 편향적인 예측을 생성하거나 훈련 데이터의 편향을 심화시킬 수 있다.
성별 편향은 NLP 알고리즘에서 발생할 경우 하류 어플리케이션에서 편견을 강화하고 손상을 입힐 수 있다. 이는 실제적인 영향을 가지며, 예를 들어 자동 이력서 필터링 시스템이 성별을 기준으로 지원자를 선택하는 경우에는 남성 지원자를 우선시하는 편향성이 우려된다.
편향을 분류하는 방법 중 하나는 할당 편향과 표현 편향으로 구분하는 것이다. 할당 편향은 시스템이 자원을 불공정하게 할당하는 경제적인 문제로 해석될 수 있으며, 표현 편향은 시스템이 특정 그룹의 사회적 정체성과 표현을 퇴색시키는 경우에 발생한다. NLP에서의 성별 편향은 이러한 할당 표현과 표현 편향의 형태로 나타날 수 있다.
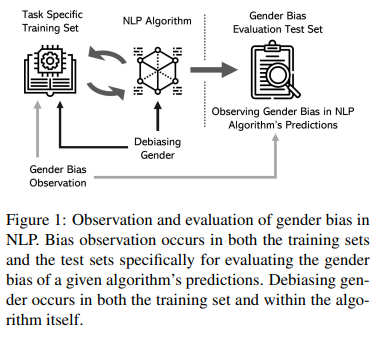
논문은 NLP에서 성별 편향을 인식하고 완화하기 위한 최근 연구 동향을 종합적으로 검토하고 있다. 또한 기존의 편향 해소 방법에 대한 문제점을 비판적으로 논의하고 최적화, 지식 결여 및 향후 연구 방향에 대해 논의한다. 이를 통해 NLP 시스템에서의 성별 편향을 인식하고 완화하기 위한 종합적인 프레임워크를 제시하고 있다.
Observing Gender Bias
NLP에서 성별 편향을 분석하는 최근 연구는 다양한 방법을 사용하여 편향을 양적으로 측정하고자 한다. 이를 위해 심리학적 실험, 성능 차이를 통한 분석, 그리고 벡터 공간에서의 분석 등 다양한 접근법을 사용한다.
Adopting Psychological Tests
심리학적 실험은 인간의 잠재적 성별 편향을 측정하는 데 사용되는 암묵적 연관 테스트(Implicit Association Test, IAT) 를 활용한다. 이 실험은 두 개념이 서로 다른지 유사한지를 인식하는 데 걸리는 시간과 정확성의 차이를 측정하여 성별 편향을 양적으로 파악한다. 이러한 실험을 단어 임베딩에 적용한 Word Embedding Association Test (WEAT) 도 있다.
Analyzing Gender Sub-space in Embeddings
임베딩에서의 성별 하위 공간 분석은 성별 중립 단어를 나타내는 단어 임베딩의 성별 하위 공간에 대한 투영 크기와 편향 평가 사이의 상관 관계를 통해 성별 편향을 정의한다. 이 방법은 단어 임베딩의 특정 차원에서 성별 편향을 측정하는 데 사용된다.
Measuring Performance Differences Across Genders
성별 스왑에 따른 성능 차이 측정은 성별에 해당하는 단어를 서로 교환하여 모델의 성능 차이를 측정한다. 예를 들어, 성별 스왑된 입력에 대해 모델의 거짓 양성 및 거짓 음성 비율을 비교하여 성별 편향을 분석한다.
Gender-swapped GBETs
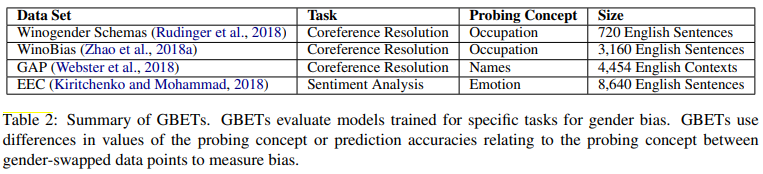
또한, 성별 편향을 분석하기 위해 Gender Bias Evaluation Testsets (GBETs) 라고 불리는 특수한 데이터셋을 사용한다. 이 데이터셋은 NLP 시스템이 성별 편향을 어떻게 처리하는지 확인하기 위해 설계된 평가 데이터셋이다. GBET를 통해 모델의 성능 차이와 성별 편향을 측정하고, 편향된 예측에 대한 개선과 데이터셋의 불균형 문제를 해결할 수 있다.
이러한 다양한 방법을 통해 NLP에서의 성별 편향을 분석하고 이를 인식하는 데 기여하는 연구들이 진행되고 있다. 이를 통해 성별 편향의 유형과 정도를 이해하고 개선하기 위한 방법을 모색할 수 있다.
Debiasing Methods Using Data Manipulation
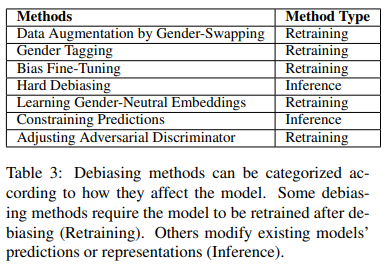
NLP에서 성별 편향을 보정하기 위해 다양한 접근 방법이 제안되었다. 이는 주로 두 가지 측면에서 진행된다: (1) 텍스트 코퍼스와 그 표현 방식, (2) 예측 알고리즘. 이 섹션에서는 텍스트 코퍼스와 단어 임베딩을 보정하기 위한 기법에 대해 설명한다. 예측 알고리즘에서 성별 편향을 완화하기 위한 기법은 섹션 4에서 다룬다.
Debiasing Training Corpora
Data Augmentation
불균형한 성별 참조를 보정하기 위해 데이터 증강이 사용될 수 있다. 원본 데이터셋과 동일하지만 반대 성별에 편향된 증강 데이터셋을 생성하고, 원본 데이터셋과 데이터 스왑된 데이터셋의 합집합으로 훈련하는 방법이 제안되었다. 데이터 증강은 성별 스왑과 이름 익명화를 적용하여 생성된 데이터를 활용한다. 데이터 증강은 성별 편향을 완화하고 모델이 덜 편향적인 예측을 할 수 있도록 도와줄 수 있다.
Gender Tagging
일부 작업에서는 데이터 포인트의 출처 성별을 혼동시키면 예측에 부정확성이 발생할 수 있다. 성별 태깅은 데이터 포인트의 출처 성별을 나타내는 태그를 추가하여 이를 완화하는 방법이다. 이를 통해 모델은 출처의 성별을 고려하여 더 정확한 예측을 할 수 있다. 성별 태깅은 출처 성별 정보를 알아야 하기 때무네 메타 정보를 활용해야 하며, 추가 비용이 발생할 수 있다.
Bias Fine-Tuning
편향되지 않은 데이터셋을 활용하여 전이 학습을 수행한 후, 보다 편향된 데이터셋을 사용하여 대상 작업을 직접 훈련시키는 방법이다. Bias Fine-Tuning은 전이 학습을 통해 모델이 편향을 최소화하도록 보장한 후, 대상 작업을 훈련시켜 모델이 편향 없이 작업을 수행할 수 있도록 도와준다. 이 방법은 비교적 효과적이며, 유사한 데이터셋의 경우 더욱 효과적일 수 있다.
Debiasing Gender in Word Embeddings
Removing Gender Subspace in Word Embeddings
성별 부분 공간과의 유사성을 제거하여 단어 임베딩에서 성별 편향을 보정하는 방법이 있다. 이를 위해 코사인 유사도와 직교 벡터를 활용하여 성별 부분 공간을 조정한다. 그러나 이 방법은 단어의 의미적 정의와 성별 구성 요소 간의 관계를 고려해야 하는 문제가 있을 수 있다.
Learning Gender-Neutral Word Embeddings
성별 특정 단어의 성분을 제거하고 성별 중립 정보를 유지하는 방식으로 단어 임베딩을 훈련시키는 방법이 있다. 이 방법은 성별 차원과 성별 중립 차원 간의 차이를 조정하여 임베딩 공간을 수정한다. 이 방법은 더 큰 유연성을 제공하며, 다양한 언어에서 확장될 수 있다.
이러한 방법들은 단어 임베딩과 훈련 데이터에 대한 다양한 접근 방식을 제시하고 있으며, 성별 편향 보정을 위한 다양한 전략을 사용할 수 있다.
Debiasing by Adjusting Algorithms
NLP에서의 성별 편향을 완화하기 위해 알고리즘 조정 방법이 제안되었다. 이 섹션에서는 두 가지 접근 방식에 대해 설명한다.
Constraining Predictions
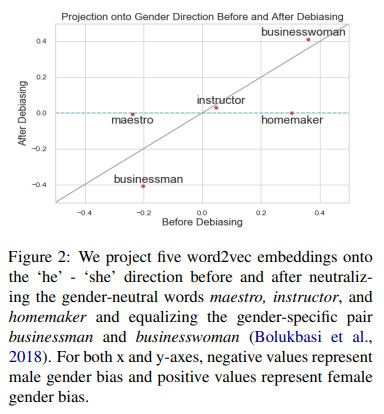
NLP 모델이 훈련 데이터의 편향을 증폭시킬 수 있는 예측을 통해 편향을 악화시킬 수 있다는 점을 고려하여, 제약 조건이 있는 조건부 모델인 Reducing Bias Amplification (RBA) 를 제안되었다. RBA는 최적화 함수를 제한하여 예측이 정의된 조건에 맞도록 보장한다. 이를 통해 모델이 예측을 통해 편향을 증폭시키는 것을 방지할 수 있다. RBA는 Lagrangian relaxation을 사용하여 효과적으로 근사적 추론을 수행할 수 있다.
Adversarial Learning: Adjusting the Discriminator
생성 적대적 네트워크의 변형을 활용하여 성별 속성을 고려한 적대적 학습이 제안되었다. 생성자는 판별기가 주어진 작업(예: 유추 완성)에서 성별을 식별하는 것을 방지하기 위해 학습된다. 이 방법은 모델을 편향 보정하는 데 사용될 수 있으며, 일반화 가능성을 가지고 있다. 기울기 기반 학습을 사용하는 모델에 적용할 수 있다.
이러한 알고리즘 조정 방법은 모델이 편향을 증폭시키는 예측을 제한하거나 적대적 학습을 통해 편향을 완화하는 데 도움을 줄 수 있다. 이러한 접근 방식은 NLP 모델의 예측 결과에 직접적인 영향을 미치므로 효과적일 수 있다.
Conclusion and Future Directions
논문은 NLP에서의 성 평등 편향을 인식하고 완화하는 최근 연구를 요약했다. 그러나 법, 심리학, 미디어 연구 등 다른 학문 분야에서의 성 편견 연구에 대해서는 다루지 않았다. 또한, 인공지능, 기계 학습, 데이터 마이닝 등 다른 응용 분야에서도 알고리즘적 편향 문제에 대해 광범위하게 논의되었다. 더욱이, 모델/데이터 투명성과 개인 정보 보호와 같은 중요한 측면도 다루지 못했다. 이에 대해서는 다른 연구를 참고할 수 있다.
현재 NLP에서의 성 평등 편향 연구는 상대적으로 초기 단계이며, 표준화된 평가 지표와 벤치마크의 부족이 있다. 관련 분야의 연구자들은 NLP 응용 프로그램에서 성 평등 편향을 철저히 측정하기 위해 협력해야 한다. 그러나 다른 응용 분야마다 다른 지표가 필요할 수 있고, 편향의 다른 개념 사이에는 트레이드오프가 존재하기 때문에 이는 쉬운 과제가 아니다.
향후 연구 방향으로는 다음을 제시할 수 있다.
Mitigating Gender Bias in Languages Beyond English
현재 연구는 주로 영어 언어에 초점을 맞추고 있다. 하지만 다른 언어에서의 성평등 편향 완화에 대한 연구가 필요하다. 다른 언어에서의 성별 전환은 어려운 작업일 수 있으며, 각 언어의 특성을 고려한 새로운 기법이 개발되어야 한다.
Non-Binary Gender Bias
현재 연구는 이진적인 성별에 초점을 맞추고 있다. 비이진적인 성별 및 인종적 편향에 대한 연구도 필요하다.
Interdisciplinary Collaboration
성 편향은 NLP에만 존재하는 문제가 아니다. 다른 컴퓨터 과학 분야에서의 연구 결과를 활용하여 기계 학습 데이터와 모델에서 발생하는 잠재적인 성 편향에 대한 이해를 향상시킬 수 있다. 또한, 컴퓨터 과학자와 사회학자 간의 협력을 통해 기계 학습 시스템의 성 편향에 대한 이해를 향상시킬 수 있다.
종합적으로, NLP에서의 성 평등 편향에 대한 인식과 완화에 대한 연구는 여전히 초기 단계이며, 더 많은 연구가 필요하다. 더 나은 방법과 접근법을 개발하기 위해 다양한 측면과 응용 분야에서의 노력이 필요하다.

2개의 댓글

안녕하세요! 이화여자대학 커뮤니케이션 미디어학부 전공 수업 중 하나인 미디어 글쓰기와 스피치를 수강 중인 학생들 입니다. 저희 조는 기획기사 프로젝트 일환으로 딥페이크라는 주제를 정해 기사를 작성하고자 합니다. 마침 조사를 하던 중 '딥트'라는 프로젝트를 알게되어 댓글 남깁니다. 이와 관련하여 여쭤보고 싶은 사항이 있는데, 혹시 따로 연락할 수 있는 소통창구가 있을까요? 감사합니다:)
유익한 내용 요약 감사해요~