
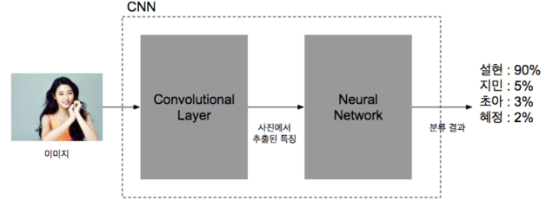
1. CNN
- 기본적인 Neural Network 앞에 여러 계층의 Convolutional Layer을 붙인 형태
- 위의 Convolution Layer 부분이 아래 Feature extraction 부분, 위의 Neural Network 부분이 아래 Classification 부분
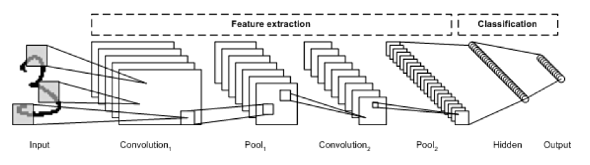
- 이미지의 공간정보를 유지하면서 특징을 효과적으로 인식하고 분류
- 학습 파라미터가 적음(Filter가 공유 파라미터로 사용되기 때문에)
2. Convolution Layer
- 합성곱(Convolution), 채널(Channel), 필터(Filter)&Stride, 패딩(Padding)의 과정을 거쳐 만들어진 Layer를 Convolution Layer라고 부름
- 이런 과정을 거쳐 만들어진 Feature Map에 활성함수(Activation Function)을 적용한 Activation Map이 Convolution Layer의 최종 출력 결과가 됨
2.1 채널(Channel)
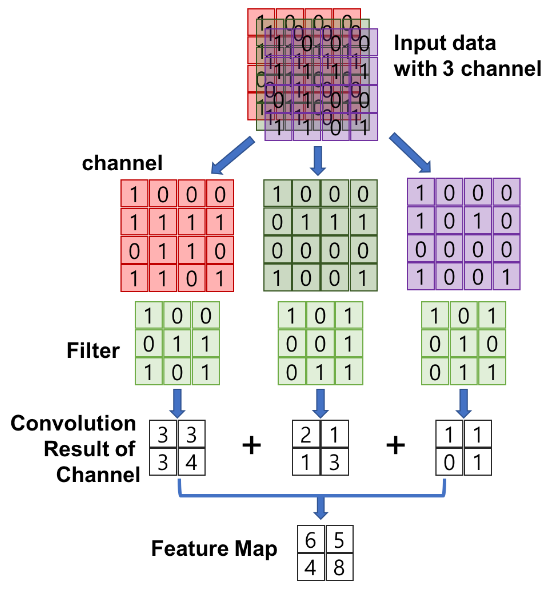
- 하나의 컬러 이미지는 보통 RGB 3가지의 Channel로 이루어진 3차원 데이터
- 흑백 이미지는 1가지의 Channel로 구성된 2차원 데이터
- 예) 높이 39px, 폭 31px의 컬러 이미지의 shape=(39,31,3), 흑백 이미지의 shape=(39,31,1)

2.2 필터(Filter)&Stride
- 이미지의 특징을 추출하기 위한 행렬로 일반적으로 33 or 44의 정사각행렬로 정의
- 데이터에 특징이 있으면 큰 값, 특징이 없다면 0에 가까운 값
- 특징을 잘 찾을 수 있게 어떤 값의 행렬(필터)이 필요한지 찾는 과정이 CNN의 학습과정
2.2.1 Stride
- 필터가 순회하는 간격
- Stride=1이면 한칸씩 이동, Input data와 Filter의 합성곱을 수행하게 되는 식
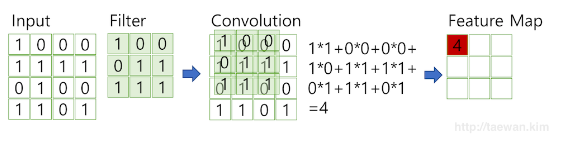
- 위 과정을 아래와 같이 반복
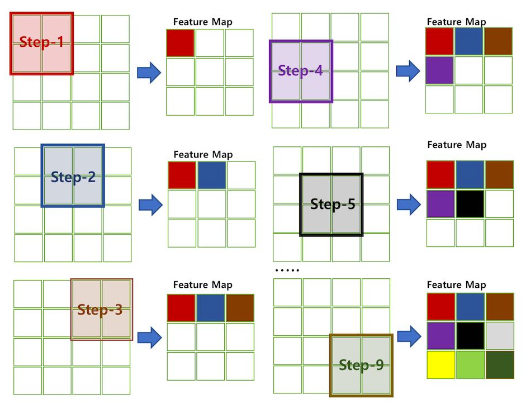
- 3개로 나눠진 채널(흑백의 경우 1개) 별로 합성곱을 진행하여 Feature Map을 만들고 이들을 각 지정된 Stride만큼 이동시키며 반복 수행해 Feature Map 행렬을 만듦
- 최종 Feature Map은 각 채널별로 나온 Feature Map을 합한 것
2.3 패딩(Padding)
- Feature Map의 크기는 원래의 Input data의 크기보다 작음, 이대로 학습을 수행하면 최종 Convolution Layer의 Output은 처음 Input보다 사이즈가 작게 되고, 이를 반복적으로 수행하면 결국 Neural Network를 적용하기 전에 많은 데이터가 유실됨, 충분한 특징값이 추출되기도 전에 결과값이 유실
- 따라서 Convolution Layer의 Output size를 Input data size와 같게 하기 위해 데이터의 외곽에 특정 값(주로 0)으로 채우는 과정을 거침(==패딩)
- 패딩은 사이즈 조절 기능 외에도 원본 데이터에 계속 0이라는 노이즈를 섞음으로써 과적합(Overfitting)을 방지하는 효과가 있음
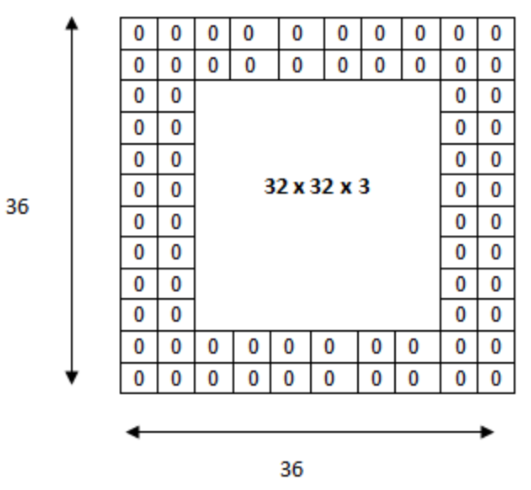
2.4 활성함수(Activation function)
- 패딩까지 거친 데이터는 데이터가 가지고 있는 특징을 매우 큰값으로, 특징이 없는 부분은 0에 가까운 값으로 나타내고 있음
- 값의 크기가 중요한 것이 아니라 특징이 있는지 없는지가 중요하기 때문에 이를 바꿔주는 작업이 필요(-> Activation function이 수행)
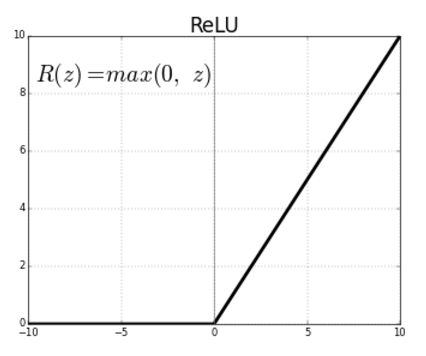
- CNN에선 ReLU를 주로 사용, Sigmoid는 학습 중 Back Propagation 과정에서 값이 희석되는 현상 발생
- Activation function을 적용한 데이터를 Activation map이라 하며 이것이 최종적인 Convolution layer의 Output이 됨
3. 풀링(Pooling) (==Sub Sampling)
- 풀링 레이어는 Convolution Layer의 Output을 Input으로 사용하며, Activation Map의 크기를 줄이거나 특정 부분을 강조하는 용도로 사용
- 어느정도 특징이 추출되었으면 모든 특징을 다 사용하는 게 아니라 특징 중에서도 특출난 것만 사용하겠다는 아이디어에서 시작된 것으로, 주로 사용되는 방법인 Max pooling으로 정사각행렬의 특정 영역 안의 최대값을 그 정사각행렬의 대표값으로 사용
- 여기서 사용되는 정사각행렬은 일반적으로 Stride로 설정했던 크기와 동일
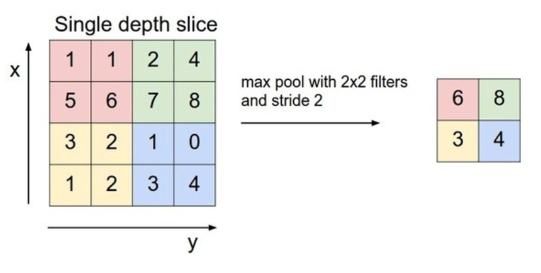
- 풀링은 매번 Activation Map에 적용되는 것이 아니라 데이터의 크기를 줄이고 싶을 때 선택적으로 사용
- 적은 Data size로 효율적인 학습이 가능하고 데이터의 크기를 줄이며 임의적인 소실이 발생하기 때문에 Overfitting을 방지할 수 있음
4. Fully Connected Layer
- 선택적인 풀링을 거쳐 만들어진 최종적인 Convolution Layer를 Neural Network의 Input으로 사용하기 위해 행렬이 아닌 배열로 만들어주는 과정이 필요(-> Flatten Layer가 수행)
- 이 과정까지 거치면 처음 Input에서 특징만 추출한 최종적인 Layer가 완성됨, 이를 Neural Network에 적용해 최종적으로 원하는 분류를 수행하게 됨
