
통계학 기초
통계적 모델링 : 적절한 가정 위에서 데이터를 표현하는 확률분포를 추정하는 것이 목표
데이터만으로 모집단의 분포를 정확하게 알아내는 것은 힘들기 때문에, 근사적으로 확률분포를 추정한다. (추정 방법의 불확실성을 고려해 위험을 최소화)
모수
모집단의 특성을 나타내는 값
모집단 : 통계적 관찰이 되는 집단
- 모수적 방법론(parametic) : 데이터가 특정 확률분포를 따른다고 선험적으로 가정하고, 분포를 결정한느 모수(parameter)를 추정하는 방법
- 비모수적 방법론(nonparametic) : 특정 확률분포를 가정하지 않고, 데이터에 따라 모델의 구조와 모수의 개수가 바뀌는 방법.
(모수가 없는 것이 아닌, 모수가 무한히 많거나 모수의 수가 바뀌는 경우)
그렇다면 모수적 방법론에서 확률분포를 어떻게 가정하기 위해서는, 우선 히스토그램을 통해 모양을 관찰한다.
-
데이터가 2개의 값만 가지는 경우(0 또는 1) : 베르누이 분포
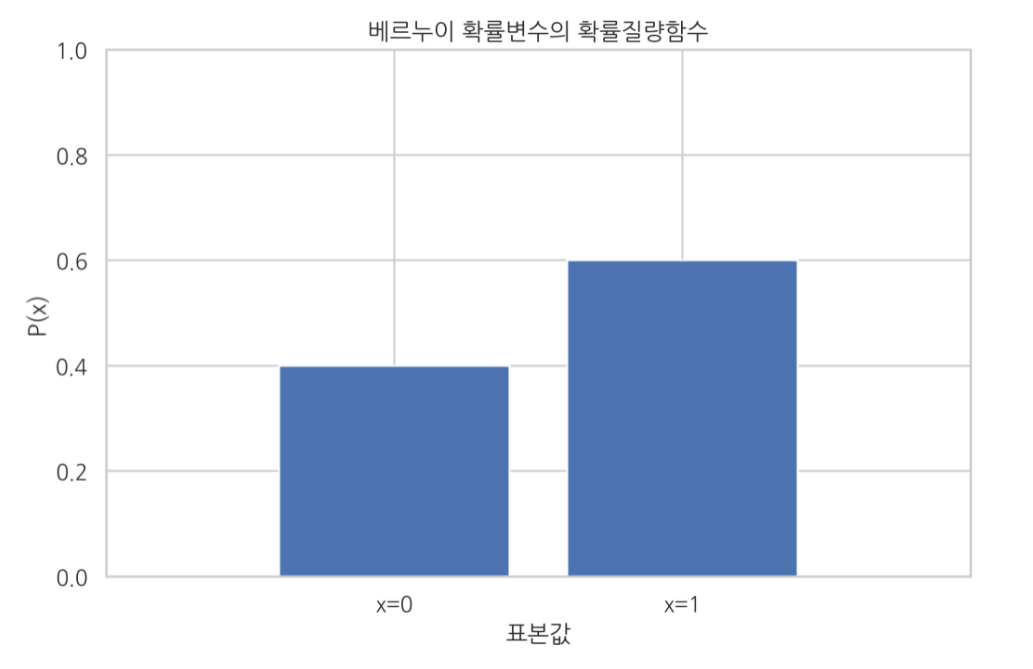
-
데이터가 n개의 이산적 값을 가지는 경우 : 카테고리 분포
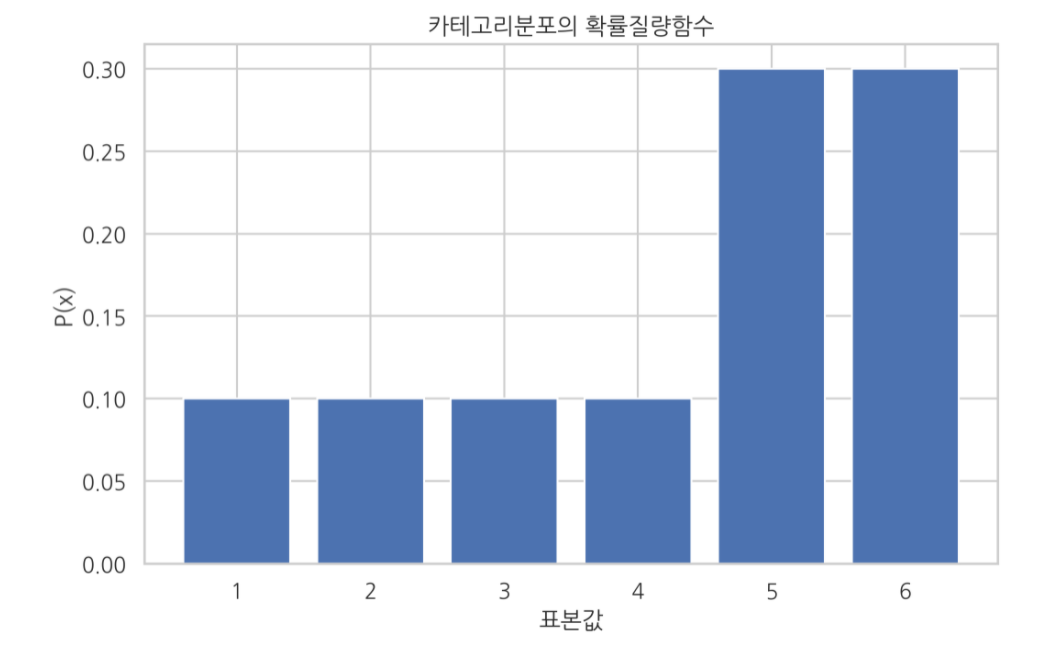
-
데이터가 [0, 1] 사이에서 값을 가지는 경우 : 베타분포
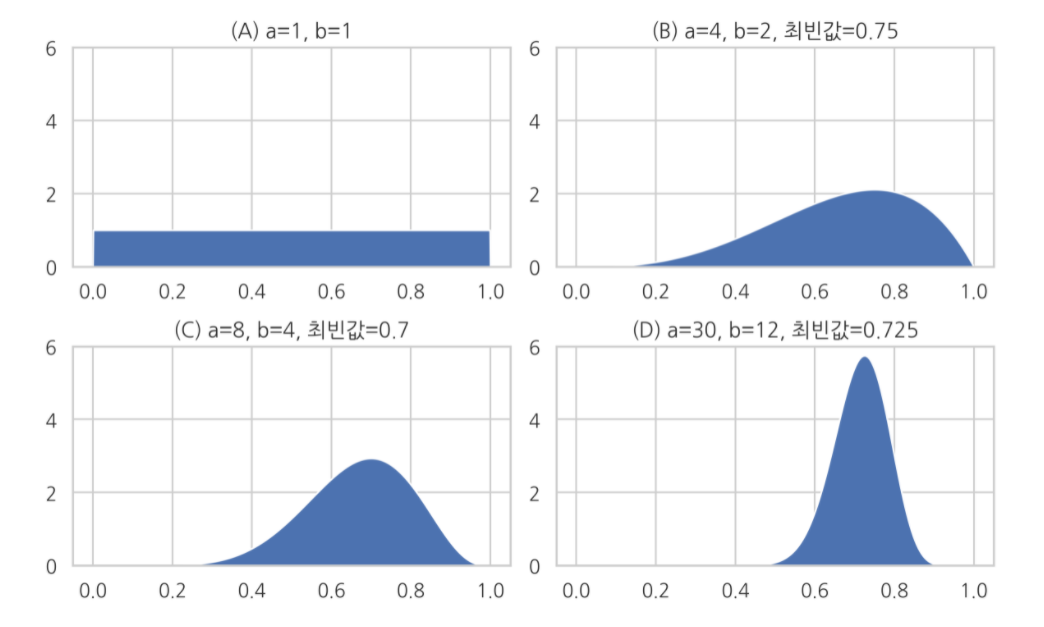

하지만 기계적으로 확률분포를 가정해서는 안되고, 데이터를 생성하는 원리를 먼저 고려해야 한다. 모수를 추정하고 + 통계적 검증으로 적절히 예측하는지 확인하자
모수적 방법론으로 모수 추정하기 : 정규분포
데이터의 확률분포를 정규분포라 가정하고, 모수를 추정해 보자. 정규분포의 모수는 평균 과 분산 이다.
평균과 분산을 추정하는 통계량(statistic)은
이 때 N이 아니라 N-1로 나누는 이유는 불편(unbiased) 추정량을 구하기 위해서이다. 기대값을 취했을 때, 원래 모집단에 대표되는 통계치와 일치시키는 방향으로 유도한다.
표집분포(sampling distribution) : 표본들의 분포가 아닌, 통계량(표본평균, 표본분산)의 확률분포.
표집분포는 N이 커질수록 정규분포 를 따른다. (중심극한정리(central limit theorem))
표본분포(sample distribution)의 경우는 모집단의 분포를 따르지만,
표집분포(sampling distribution)는 모집단의 분포를 따르지 않을 수 있다.
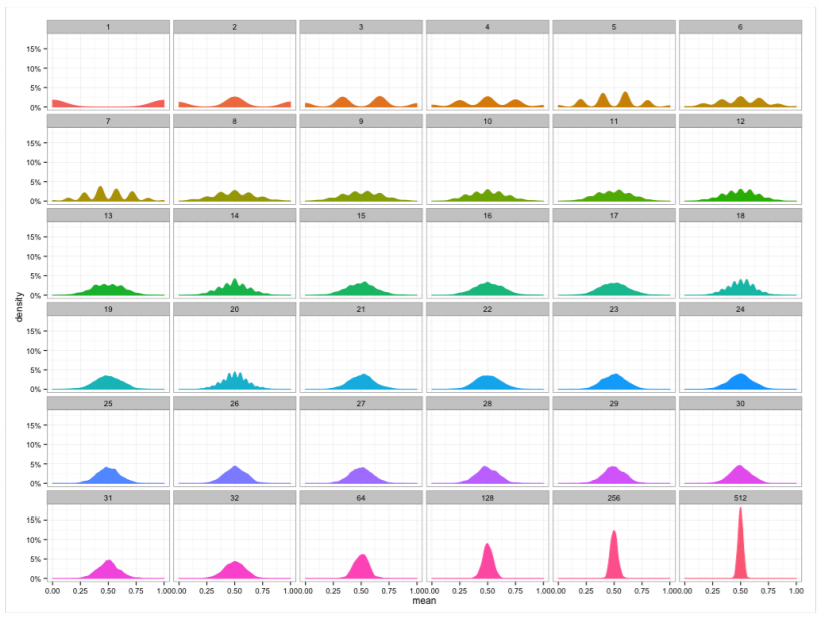
예를 들어, 이항분포의 표본분포는 정규분포를 따르지 않지만, 표본분포의 확률분포인 표집분포는 정규분포를 따른다.
비모수적 방법론으로 모수 추정하기 : MLE (maximum likelihood estimation)
확률분포마다 사용하는 모수가 다르기 때문에, 표본평균이나 표본분산 이외의 모수가 필요할 때가 있다.
가정과 상관없이, 이론적으로 가장 가능성이 높은 모수(parameter)를 추정하는 방법 중 하나는 최대가능도 추정법(maximum likelihood estimation, MLE) 이다
MLE는 데이터가 주어져 있을 때, 를 변형시킴에 따라 값이 바뀌는 함수이다. 가능도함수와 확률밀도(질량)함수는 같은 공식을 사용하지만,
가능도함수는 주어진 데이터 x에 대해 변수인 모수 에 따라 값이 바뀌는 함수이고, 확률밀도(질량)함수는 모수 가 주어져 있을 때 x에 대한 함수이다.
가능도함수는 모수 를 따르는 분포가 x를 관찰할 가능성을 뜻하지만, 확률이 아닌 대소비교가 가능한 함수로 해석해야 한다.
(가 1이 아니다)
데이터 집합 X가(각 행벡터) 독립적으로 추출되었을 경우, 확률밀도(질량)함수의 곱으로 나타낼 수 있고, 로그를 씌워 로그가능도를 최적화한다 (곱셈 -> 덧셈)
로그가능도를 최적화하는 모수, 가능도함수를 최적화하는 모수 모두 MLE이다.
데이터의 숫자가 수억 단위가 된다면, 가능도를 계산하는 것은 매우 어려워지고,
특히 데이터가 독립일 경우 로그 함수를 사용하면 가능도의 곱셈을 덧셈 연산으로 바꿀 수 있다. 경사하강법으로 가능도를 최적화 할 때, gradient 연산을 사용하게 되는데, 이 때 연산량을 에서 으로 줄여준다. (선형적으로 변환되기 때문).
경사하강법을 사용하는 손실함수의 경우, 목적식을 최소화하는 것이 목적이기 때문에 음의 로그가능도(negative log-likelihood)를 최적화하게 된다.
(경사하강법 : 목적함수를 최소화 / 로그가능도 : 최대화)
피어세션
Q1. AI Math 6강 확률론 퀴즈 중에서 기댓값에 대해서 궁금하다.
- 주사위: 균일한 확률이라고 가정하면 각 사건의 확률은 1/6이다.
- 정사면체: 균일한 확률이라고 가정하면 각 사건의 확률은 1/4이다. 그러므로 문제에서 사건을 등장하는 주사위 숫자값이라고 하면, 확률 x 주사위 값의 평균을 구해주면 된다 (참고자료)
- 팀 캠퍼님이, Joseph Blitzstein Introduction to Probability 책 과 해당 교수님의 Stats 110를 추천해 주셨다.
현재 부스트코스 AI Tech 수업과 같은,edwith에서 자막과 함께 공개가 되어 있어서, 확률과 통계를 공부하는 데 도움이 될 것 같아 수강신청을 했다 ! 👍👍
Q2. AI Math 9강 CNN 퀴즈에서 행렬 곱셈이 왜 등장하는지 모르겠다.
- 이 질문에, 팀 캠퍼분이 정말 멋지게 설명을 해 주셨다 🤩

- 주어진 Matrix X를 이미지 하나라고 생각해봐라
- Kernel, filter, window는 모두 같은 개념
제일 쉬운 예제인 Y(1,1)을 생각을 해보면, 같은 위치의 원소를 곱해준다는 다음 합한다는 것을 알 수 있다.
위와 같이 생각해 보면, 계산값은 의 (문제 상 인덱스는 1부터 시작)부터 시작하는 원소들과, 의 성분곲 값이 된다.
- 해당 답변을 해 주신 캠퍼님이, 저번
Moore-penrose inverse질문에도 우선 선형모델로 구현을 하고, 동일한 값이 나오는 것을 보여주셨는데,
이번 경우도 생각할 수 있는 가장 간단한 예제로 단순화하고 + 문제의 핵심을 이해한 후 + 그 기반으로 복잡한 계산을 해결해 나가는 부분이 정말 배울 점이라고 생각했다!
1주차 회고
- 부스트캠프 첫 주차가 끝났다. 사전에 들었던 강의임에도 물리적 시간이 부족하다고 느껴졌고, 체력 관리를 잘 해야겠다는 생각이 든다.
- 개인적인 이번주 목표는 두 가지였는데 첫째는 주어진 강의과 과제 끝내기, 둘째는 1주 공부시간 40시간 채우기 였는데 둘 다 목표는 달성했다.
- 목표를 달성한 것은 뿌듯하지만 시간대비 효율이 떨어졌다는 점, 공부하며 모르는 부분과 해결한 부분이 여러 가지 있었는데 그때그때 정리하지 않아 강의와 필기를 다시 보며 학습정리를 작성하는데 시간을 많이 썼다는 점! 그래서 놓친 부분이 너무 많다는 점... 😂 아쉬운 부분이 많다!
- 다음 주는 임교수님 세션과 팀 캠퍼분에게 배운 것을 잘 써먹어서 개념과 example위주로 공부하고, 필수 과제 뿐 아니라 선택 과제도 모두 끝낼 수 있도록 열심히 공부해야겠다~ 🥳🥳
