RNN 언어 모델(RNNLM)
이전에 배운 언어 모델들을 정리해보자
n-gram LM: n-1개의 단어를 고려해서 다음 단어의 확률을 예측한다. 장기적 의존성 고려X
NNLM: 은닉층이 존재하고 단어 임베딩으로 문맥 정보를 학습하여 확률을 예측한다. 장기적 의존성 일부 고려O
RNNLM: RNN의 은닉 상태를 매 시점마다 갱신하면서 문맥 정보를 유지하며 확률을 예측한다. 장기적 의존성 고려O
RNNLM의 예측 과정
예문 'what will the fat cat sit on'에 대해, RNNLM이 어떻게 다음 단어를 예측하는지 알아보자
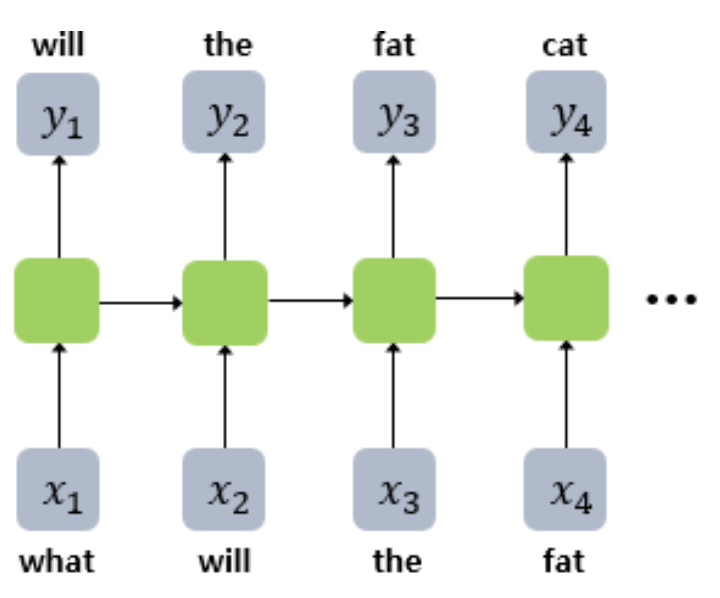
1. 입력 데이터 준비
각 단어를 워드 임베딩으로 변환하고 입력 데이터로 사용할 시퀀스를 형성한다.
2. 은닉 상태 초기화
시퀀스의 첫 번째 단어 'what'을 입력으로 받아 은닉 상태를 초기화한다.
3. 첫 번째 시점에서 다음 단어 예측
'what'과 은닉 상태를 입력으로 받아 다음 단어인 'will'의 확률을 계산한다.
이때, 은닉 상태는 이전 시점의 정보를 유지한다.
ex. P('will'|'what', 은닉 상태) = 0.8,
P('the'|'what', 은닉 상태) = 0.1,
P('fat'|'what', 은닉 상태) = 0.05, ...
4. 첫 번째 시점의 예측 결과
'what' 다음에 'will'이 올 확률이 가장 높다고 판단한다.
5. 두 번째 시점에서 다음 단어 예측
'will'과 업데이트된 은닉 상태를 입력으로 받아 다음 단어 'the'의 확률을 계산한다.
6. 두 번째 시점의 예측 결과
'will' 다음에 'the'가 올 확률이 가장 높다고 판단한다.
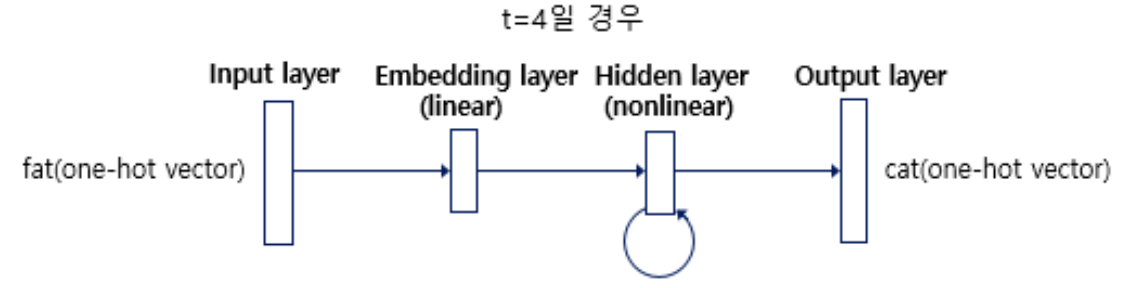
7. 나머지 시점에서 다음 단어 예측
위의 과정을 시퀀스의 마지막 단어까지 반복해서 확률을 계산한다.
8. 최종 예측 결과
시퀀스의 마지막 단어인 'on'까지 모든 시점의 다음 단어 확률을 계산하고 종합해서 최종 예측 결과를 얻는다.
사실 위의 과정은 훈련이 끝난 모델의 **테스트 과정**이라서 저렇게 했지만!!
모델을 훈련할 때는
이전 시점의 예측 결과를 다음 시점의 입력으로 넣으면서 예측하는 게 아니라,
t 시점의 출력을 t+1 시점의 입력으로 사용하지 않고
t 시점의 레이블을 t+1 시점의 입력으로 사용한다.
이를 교사 강요라고 한다.
교사 강요
그럼 왜 훈련할 때 교사 강요를 쓸까?
간단히 말하자면 정답을 알게해서 오류 누적없이 정확히 예측을 하기 위함이다.
훈련 과정에서도 t 시점의 출력을 t+1 시점의 입력으로 사용할 수 있지만
한 번 잘못 예측하면 뒤에서의 예측까지 영향을 미쳐서 훈련 시간이 느려지므로
정확한 레이블을 알고 있음으로써 RNN을 빠르고 효과적으로 훈련시키기 위함이다.
ex. 실제로는 "I love to eat"이었어야 할 다음 단어 "ice" 대신에 "cream"이라는 오류가 발생했다.
이런 식으로 누적된 오류로 인해 모델이 정확한 문장을 생성하지 못하는 문제가 발생할 수 있다.

감사합니다. 이런 정보를 나눠주셔서 좋아요.