[2022 arXiv] What Makes Transfer Learning Work For Medical Images: Feature Reuse & Other Factors
Paper Review

1. Overview
medical imaging에 딥러닝을 적용할때, ImageNet과 같은 큰 사이즈의 오픈 데이터셋으로부터 transfer learning을 시도하는 것은 de-facto approach가 되었다. source domain의 feature들이 재사용된다는 assumption에 대하여 최근에는 의문이 제기되고 있고, 이 연구는 transfer learning과 data size, 모델의 capacity와 inductive bias, source domain과 target domain간의 거리와의 관계를 탐구한다.
feature reuse의 역할, medical domain에서 transferred representations이 효과적일 지 결정하는 factor가 무엇인지 알아보는 연구로 pathology image domain으로의 transfer learning에 대한 직관도 얻을 수 있을 것이라고 기대한다.
2. Method
Dataset
- APTOS2019 (N = 3,662): 당뇨성 망막병증 (diabetic retinopathy images) 이미지
- CBIS-DDSM (N = 10,239): 유방조영술 (mammography) 데이터셋
- ISIC 2019 (N = 25,331): 피부확대경 (dermoscopic) 이미지
- CHEXPERT (N = 224,316): 가슴 X-ray (chest X-rays)
- PATCHCAMELYON (N = 327,860): 림프구 절편에 H&E 염색된 WSI의 패치 이미지
Architectures
두 개의 Transformer Architecture (DeiT, SWIN), 두 개의 CNN architecture (Inception, ResNet)을 사용
DeiT는 pure transformer와 유사하고, SWIN은 locality, translational equivariance, hierarchical scale 등 CNN의 inductive bias를 사용함
inductive bias가 작은 것부터: DeiT, SWIN, Inception, ResNet
Initilization methods
- Weight transfer (WT): ImageNet에 pre-trained weight을 transfer하는 것
- Stats transfer (ST): ImageNet에 pre-trained model에서 각 layer에서 추출한 mean, variance의 normal distribution에서 weight을 sampling
- Random init. (RI): Kaiming intialization
- WT-ST: WT와 ST를 비율적으로 적용하는 것
Representational similarity
네트워크 내부와 전반에서의 feature들간의 similarity를 계산하기 위해 Centered Kernel Alignment (CKA)을 사용함
HSIC의 normalized version으로 NN에서의 feature간의 similarity를 보기 위한 metric으로 사용한다고 함
Resilience of the transfer
investigating how “sticky” the transfer was – how much the weights drifted from their initial transferred values during fine-tuning –
(1) initial weight과 fine-tuning 후 weight간의 l2 distance 계산
(2) layer의 weight을 원래 (initial) 값으로 다시 설정 (reset)한 것의 영향을 측정 - re-initialization robustness
Analyzing transferred representations layer-wise
Which parts of the network produce/reuse low-level vs. high-level features?
How do differences in representation between CNNs and ViTs impact transfer learning?
network에 걸쳐 transfer된 feature들의 representation power를 평가
test 샘플과 training 샘플에서의 embedded representation을 k-NN (k=200)으로 비교
3. Experiments
When is transfer learning to medical domains beneficial, and how important is feature reuse?


transfer learning의 benefit이 증가하는 전반적인 트렌드
(1) data size가 적어짐 (2) source domain과 target domain간의 적은 거리 (FID) (3) inductive bias가 적은 모델
ViT 모델이 inductive bias가 더 적어 feature reuse에서 더 benefit이 있다
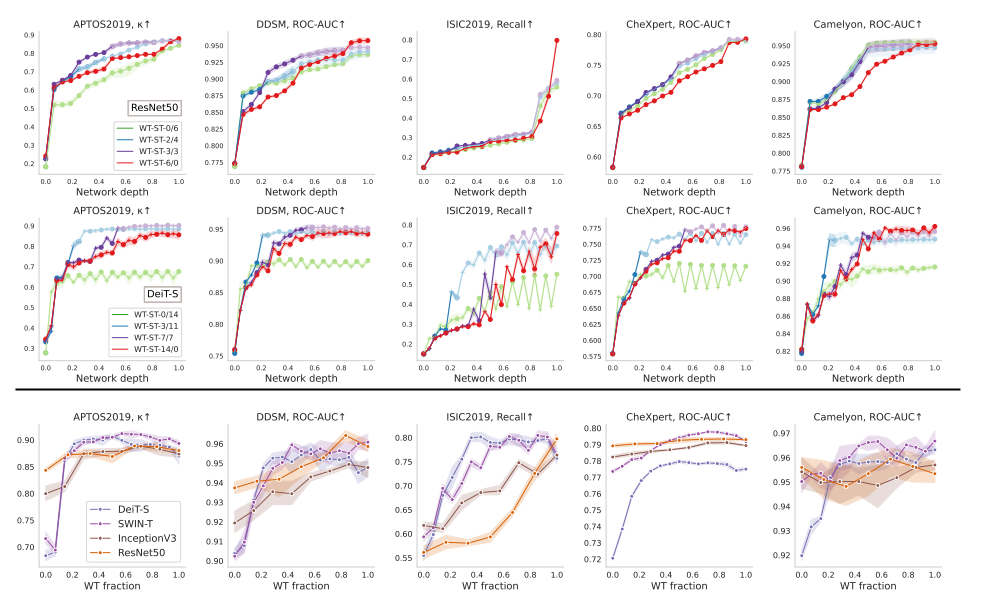
Which layers benefit from feature reuse?
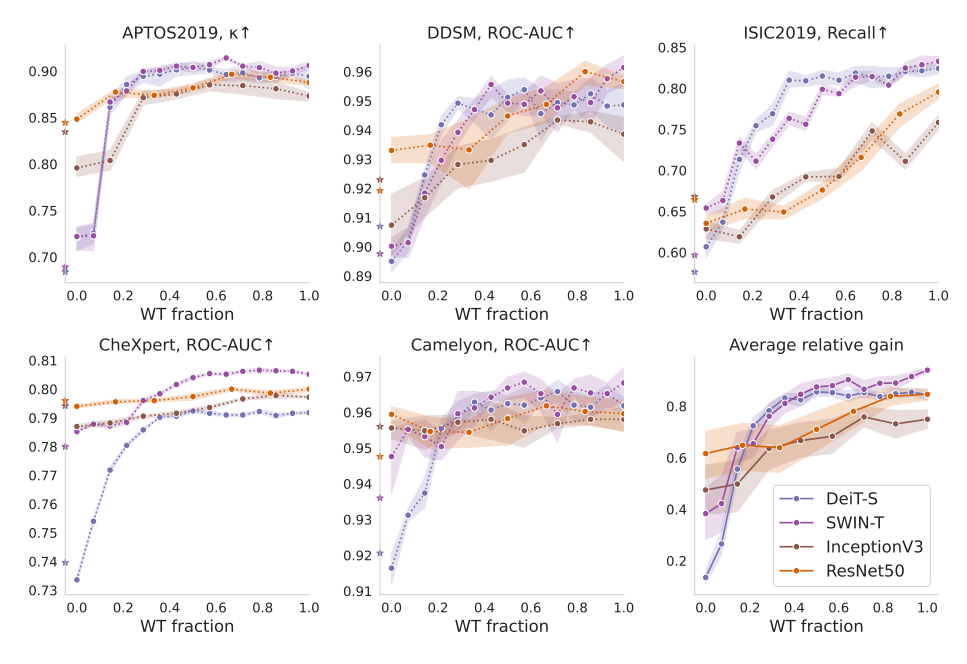
별표는 RI (Random Initialization)를 뜻함
CNN의 경우 큰 데이터셋 (CheXpert, Camelyon) 에서 상대적으로 flat하면서 WT의 이득을 별로 보지 못했는데, ViT, 특히 DeiT는 0.2~0.3이상 WT를 쓸때 굉장히 크게 성능이 향상하면서 이득을 크게 보았다.
더 작은 데이터셋에서 CNN은 조금씩 이득을 봤지만, ViT의 경우는 WT의 비율을 높이면서 early layer에서 크게 이득을 본다는 걸 볼 수 있음. 이 layer들에서 feature reuse가 강한 의존이 발생했음을 나타냄.
SWIN은 DeiT와 CNN의 특성을 모두 가지는데, 작은 데이터셋에서는 DeiT처럼 하고 큰 데이터셋에서는 CNN과 비슷한 양상을 보인다.
더 적은 inductive bias를 ViT 아키텍처는 feature reuse가 성능향상에 도움이 되는데, 특히 early layer들에 집중해야됨.
What properties of transfer learning are revealed via feature similarity?
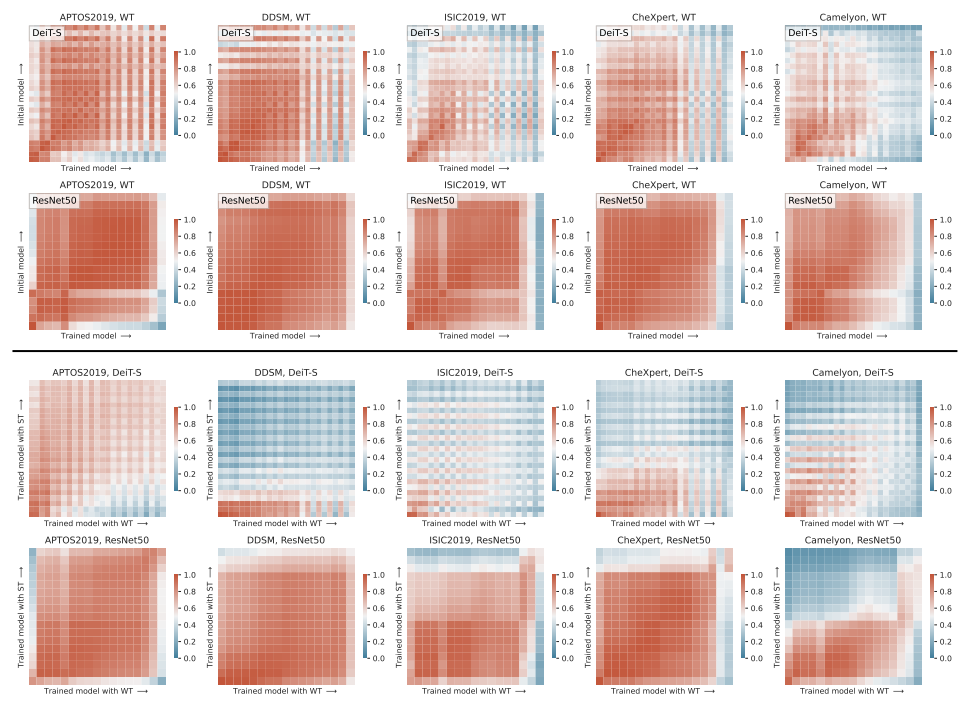
top은 WT로 fine-tuning하기 전과 후, bottom은 WT와 ST로 fine-tuning한 것을 비교
DeiT의 경우, transfer learning 전과 후 (top)에서 early and mid layer에서 강한 similarity를 나타냈는데, later layer에서는 새로운 task에 적응하기 위해 ImageNet feature에서 멀어진 것을 보였음
ResNet의 경우, broad하게 similar했는데 새로운 task에 적응해야하는 마지막 layer를 제외하고 broad하게 similar했는데, 이는 CNN의 compositional nature와 맞다.
둘 다 공통으로 나타나는 건 데이터가 많아질수록 feature reuse의 transition point가 earlier layer로 이동하는데, 이는 ImageNet feature들을 새로운 task에 적응시킬만한 충분한 데이터를 네트워크가 가지고 있기 때문이라고 말하고 있음.
Which transferred weights change?
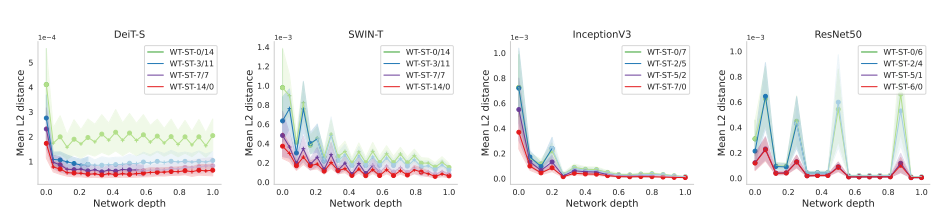
WT를 강하게 했을수록 l2 distance가 적게 나타나는 걸 알 수 있음 (ST가 강하면 덜 stick하다)
early layer들에서는 그거와 상관없이 변화를 겪게 되는데, 이는 data를 처음 만나는 layer들 혹은 scale 변화에 해당하기 때문이다.
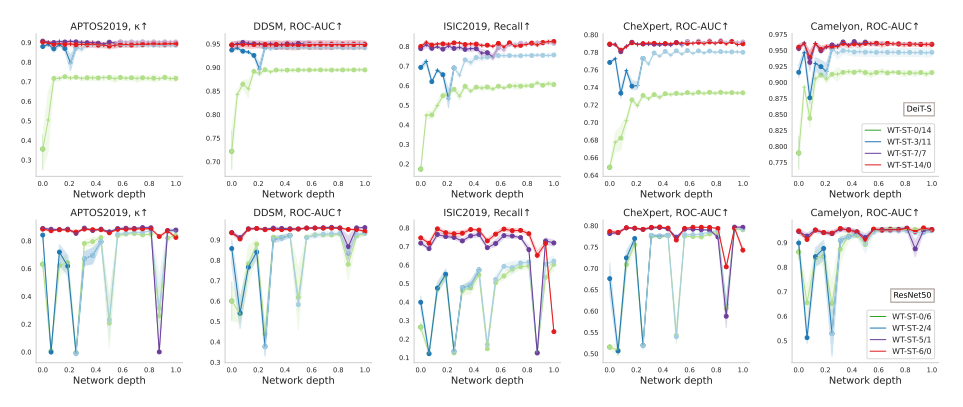
top은 DeiT, bottom은 ResNet
feature reuse를 살펴보는 방법은 layer의 weight을 초기 value로 reset할때의 영향을 알아보는 것 (re-initialization robustness)
robustness가 적은 layer들은 fine-tuning중에 큰 변화를 겪게 된다. WT를 한 network (red line) 는 더 적은 변화를 겪었고, 이는 feature reuse를 나타낸다. transfer learning이 가장 효과가 적을 때, ST와 WT사이의 robustness 격차가 적다 (y축 scale 유의)
흥미로운 건, ViT (DeiT)에서 WT-ST의 transition에서 critical하게 변하는 layer가 나타내는데, transferred weight을 바꾸기보다 network가 빨리 적응했다.
data size가 증가할수록 ViT에서 early change가 더 나타났다.
반면에, CNN은 덜 sticky했다. classification에 responsible한 final layer에서도 poor robustness를 보였다. 그리고 periodically하게 크게 변하는 걸 알 수 있는데, 이는 scale change에서도 나타나는 것이다.
Are reused features low-level or high-level?
k-NN evaluation performance
feature들간의 관련성이 critical layer들과 함께 극적으로 증가하는데, 이는 later layer가 task를 푸는데 더 기여하지 않는 것으로 보인다.
ViT의 경우, early layer에 WT를 넣을수록 ViT feature들의 discriminative power가 급격하게 증가하는데, 특히 DeiT의 경우, 첫 5개의 block에서 transfer learning이 전체 12개의 block에 대한 transfer learning과 비슷하게 성능을 내는 것을 볼 수 있음.
we find that features reused in these critical early layers of ViTs are responsible for the creation of high-level features
WT transfer가 ViT의 early layers에서 local 및 global attention의 mixture를 만들어낸다는 걸 입증함 (Appendix E)
Capacity and convergence
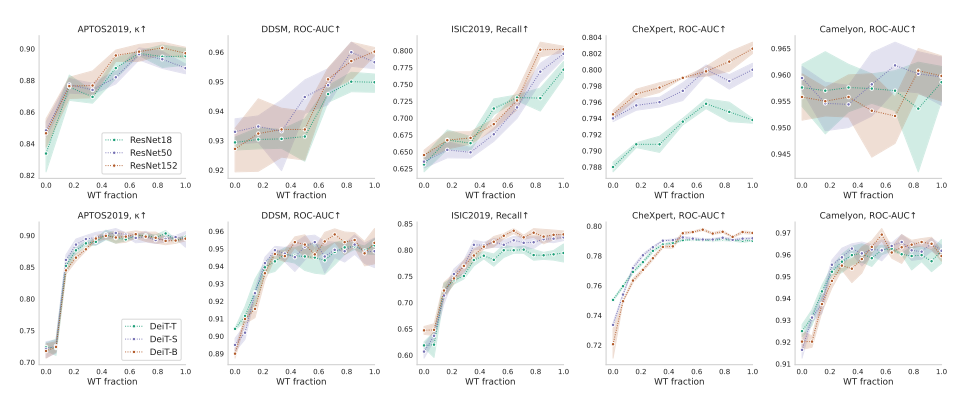
큰 모델일수록 transfer learning의 효과를 더 보는듯하다
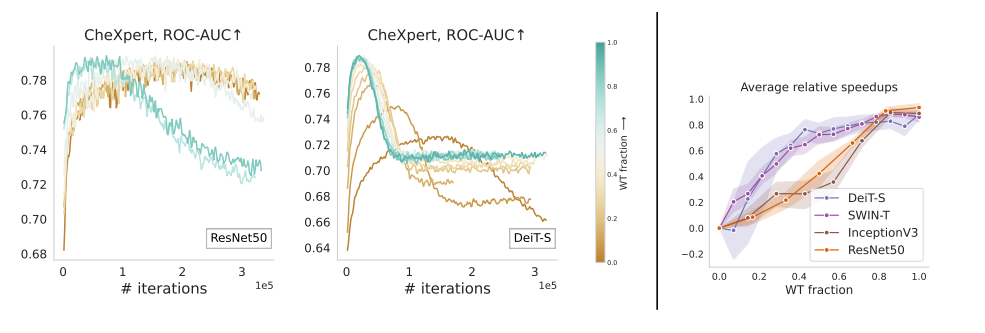
WT의 비율이 클수록 빠르게 convergence에 이르는 것을 알 수 있다. CNN이 rough하게 linear하게 convergence속도가 증가했고, ViT모델들은 network의 first half 부분에서 급격한 속도가 증가했음을 알수 있엇음.
4. Discussion
Related work
transfer learning이 우리의 생각보다 덜 applicable하다. 성능향상을 초래하지 않는다 (심지어 비슷한 task에서도). early feature들이 더 general하고 deeper할수록 task-specific해진다. source와 target domain의 거리가 증가할수록, transfer learning의 효과가 적다. 큰 아키텍처를 이용한 transfer learning과 몇십배 크기의 natural image pre-training dataset은 medical imaging domain에서 큰 성능향상을 달성할 수 있다는 관련연구들이 있었고, 이 연구와 유사하게 transfer learning을 조사한 연구들이 있었는데
이 연구는 feature reuse에 관해 좀 더 comprehensive한 분석을 수행하여 더 작은 데이터셋에서 역시 효과적이라는 걸 보여주누면서 더 넓은 범위의 데이터셋을 탐구함으로써 clarity를 더했다. 그리고 그 전 연구에선 무시했던 inductive bias와 transfer learning이 ViT에 대해 어떻게 작동하는 지에 대한 새로운 관점을 고려했다.
Factors of transferability
이 연구는 transfer learning에서의 benefit이 최소이면서 feature reuse가 덜 중요한 구간 (later layer) 을 보여줬다.
데이터 크기, source와 target domain간의 거리, 모델의 inductive bias가 적을수록 transfer learning의 효과가 커진다
(모델의 capacity는 transfer learning의 영향이 크지 않았다.)
The role of feature reuse
transfer learning이 잘 동작할때, feature reuse에 대한 강한 증거 (strong evidence) 들이 보인다.
early layers are most crucial for ViT performance, which reuse a mixture of local and global features learned on IMAGENET to perform competitively
ViT에서 early feature reuse는 later layer들은 성능에 강하게 영향 주지 않고 discard될 수 있다는 것을 의미한다.
CNN은 각 layer를 더할때마다 complexity를 추가하면서 점진적으로 향상되어 feature reuse가 보다 균일하게 나타난다.
이러한 다른 점은 model의 capacity보단 inductive bias와 관련된 것으로 보인다.
Limitations and potential negative societal impact
셀 수 없는 model과 dataset을 가지고 exhaustive study를 하는 것은 불가능하고, 이 연구는 그 전 연구보다 더 다양한 선택지를 놓고 관련있는 모델과 대표적인 데이터셋을 고르려고 노력했다
data domain간의 거리를 FID로 쟀는데, 이것이 완벽한 측정값을 제공하지 않을 수 있다.
좋은 의도에도 불구하고 medical data에 deep learning을 적용하는 건 예상할 수 없는 부정적인 영향들에 대한 가능성이 열려있다. 적절한 고려 없이 모델은 우리가 원하지 않는 bias를 배운다는 걸 생각해야한다
5. Conclusions
학습한 representation을 reuse의 증가로 transfer learning이 작동할 때, 더 적은 inductive bias를 가진 모델, 더 작은 데이터셋, ImageNet (source)와 가까운 데이터셋에서 더 좋은 gain을 보여준다!
low inductive bias를 가진 모델들이 early layer들에서 구성된 local representation의 reuse에 의존하여 high inductive bias를 가진 model들과 견줄 수 있게 성능을 내는 것을 입증했다.
