

이번 글에서는 kears.datasets안에 있는 reuters 데이터에 대해 분류해 보겠다.
Packages
from tensorflow.keras.datasets import reuters
%matplotlib inline
import matplotlib.pyplot as plt
import numpy as np
import seaborn as snsShape of Data
불러온 데이터셋을 트레이닝 세트와 테스트 세트로 나눠주자.
(X_train, y_train), (X_test, y_test) = reuters.load_data(num_words=None, test_split=0.2)모양을 확인해보자.
print('훈련용 뉴스 기사 : {}'.format(len(X_train)))
print('테스트용 뉴스 기사 : {}'.format(len(X_test)))
num_classes = max(y_train) + 1
print('카테고리 : {}'.format(num_classes))
8982개의 훈련용 뉴스 기사,
2246개의 테스트용 뉴스 기사,
46개의 카테고리를 확인할 수 있다.
Keras에서 불러온 데이터의 신기한 점은, 아래 코드를 돌려보면 알 수 있다.
print(X_train[0])
print(y_train[0])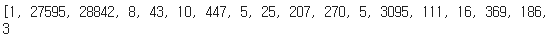
문장으로 출력되지 않고 숫자로 출력된다!
이 데이터는 안에서 해당 단어가 몇 번이나 나타나는지 세어 빈도에 따라 번호를 붙였다.
각 기사의 최대 길이와 평균 길이를 같이 확인해보자.
print('뉴스 기사의 최대 길이 :{}'.format(max(len(l) for l in X_train)))
print('뉴스 기사의 평균 길이 :{}'.format(sum(map(len, X_train))/len(X_train)))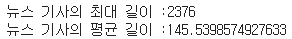
그림으로 나타내보자.
print('뉴스 기사의 최대 길이 :{}'.format(max(len(l) for l in X_train)))
print('뉴스 기사의 평균 길이 :{}'.format(sum(map(len, X_train))/len(X_train)))
plt.hist([len(s) for s in X_train], bins=50)
plt.xlabel('length of samples')
plt.ylabel('number of samples')
plt.show()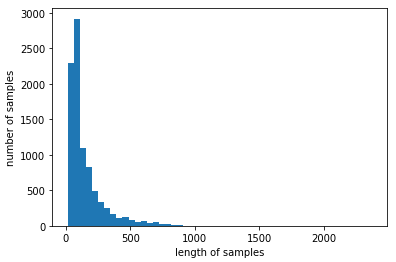
샘플의 길이가 1000자가 넘어가는 건 거의 없고 거의 200자 이내인 것 같다.
이번엔 각 주제의 분포도를 확인해보자.
fig, axe = plt.subplots(ncols=1) #그래프 틀 그리기
fig.set_size_inches(12,5) #그래프 크기 정하기
sns.countplot(y_train)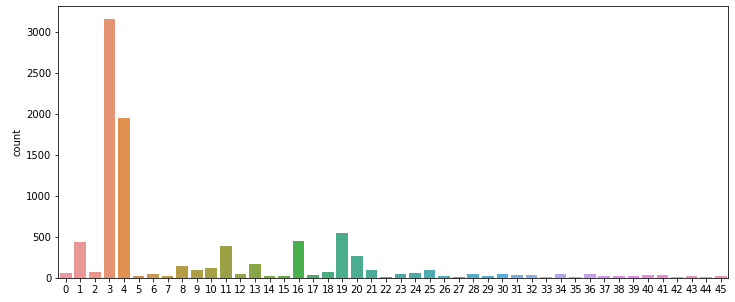
3번 레이블에 대한 기사가 제일 많다.
몇개일지 확인하고 싶으면 아래 코드를 실행해보면 된다.
unique_elements, counts_elements = np.unique(y_train, return_counts=True)
print("각 레이블에 대한 빈도수:")
print(np.asarray((unique_elements, counts_elements)))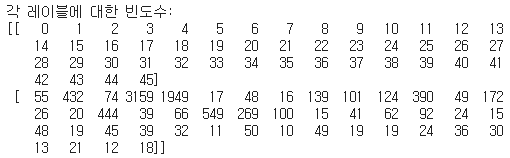
아래와 같은 방법으로도 확인할 수 있다.
label_cnt=dict(zip(unique_elements, counts_elements))
print(label_cnt)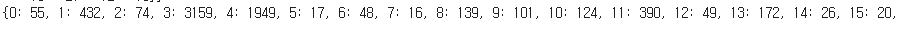
이번엔 내용으로 넘어가서 내용에 있는 글자들이 무엇인지 확인해보자.
인덱스 된 단어들이 각각 어떤 단어였는지 확인해보자.
word_to_index = reuters.get_word_index()
print(word_to_index){'mdbl': 10996, 'fawc': 16260, 'degussa': 12089, 'woods': 8803, 'hanging': 13796, 'localized': 20672, 'sation': 20673, 'chanthaburi': 20675, 'refunding': 10997, 'hermann': 8804, 'passsengers': 20676, 'stipulate': 20677, 'heublein': 8352, 'screaming': 20713, 'tcby': 16261, 'four': 185,
라면서 출력이 마구마구 나온다.
이렇게 보면 정리도 안되어있고 찾고싶은 단어도 찾기 힘들다. 인덱스를 부여할 수 있게 차원으로 만들어주자.
index_to_word={}
for key, value in word_to_index.items():
index_to_word[value] = key이제 value값에 숫자를 입력하면 그 단어가 나오게 된다.
첫번째, 두번째로 자주 쓰이는 단어가 무엇인지 확인해보자.

# <pad>: padding, 길이를 맞출때 사용하는 비어있는(사용x) 토큰
# <sos>: start of sentence, 문장의 시작을 알리는 토큰
# <unk>: unknown, 모델이 인식할 수 없는 토큰
for index, token in enumerate(("<pad>", "<sos>", "<unk>")):
index_to_word[index] = token
print(' '.join([index_to_word[index] for index in X_train[0]]))<sos> wattie nondiscriminatory mln loss for plc said at only ended said commonwealth could 1 traders now april 0 a after said from 1985 and from foreign 000 april 0 prices its account year a but in this mln home an states earlier and rise and revs vs 000 its 16 vs 000 a but 3 psbr oils several and shareholders and dividend vs 000 its all 4 vs 000 1 mln agreed largely april 0 are 2 states will billion total and against 000 pct dlrs
정수 인코딩을 실행하기 전에도 이미 전처리가 된 상태의 데이터를 가져온 거라서 제대로 분장이 복원되지는 않는다.
이제 모델을 설계해보자.
Build Model
Packages
from tensorflow.keras.datasets import reuters
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, LSTM, Embedding
from tensorflow.keras.preprocessing.sequence import pad_sequences
from tensorflow.keras.utils import to_categorical
from tensorflow.keras.callbacks import EarlyStopping, ModelCheckpoint
from tensorflow.keras.models import load_model맨 처음으로 우리가 해 줘야 할 것은 패딩이다.
각 기사의 단어 수가 다르므로 모두 같게 해주기 위해 모자라는 부분에 0을 채워주거나 max_len길이가 넘어가면 잘라준다.
max_len = 100
X_train = pad_sequences(X_train, maxlen=max_len) # 훈련용 뉴스 기사 패딩
X_test = pad_sequences(X_test, maxlen=max_len) # 테스트용 뉴스 기사 패딩0을 채워주거나 자른 후,
각 단어에 대해서 원-핫 인코딩을 해준다.
y_train = to_categorical(y_train) # 훈련용 뉴스 기사 레이블의 원-핫 인코딩
y_test = to_categorical(y_test) # 테스트용 뉴스 기사 레이블의 원-핫 인코딩이제 딥러닝의 구조를 만들어주자.
우선 전처리 한 데이터를 다음 층이 알아들을 수 있게 임베딩 레이어를 만들어줘야 한다.
Embedding(단어 집합의 크기, 임베딩 벡터의 차원)으로 만들 수 있다.
그리고 그 샘플들을 가중치를 제어하는 LSTM에 넣는다. LSTM(hidden_size)로 만들어준다.
마지막에 46개의 카테코리로 분류하기 위해서 소프트맥스 함수를 사용해 출력한다.
model = Sequential()
model.add(Embedding(1000, 120))
model.add(LSTM(120))
model.add(Dense(46, activation='softmax'))Compile
컴파일, 실행, 정확도를 측정해보자. 여러 경우의 수에 대해서 실험해 보았다.
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
history = model.fit(X_train, y_train, batch_size=128, epochs=20, validation_data=(X_test, y_test))
print("\n Test Accuracy: %.4f" % (model.evaluate(x_test, y_test)[1]))embedding(1000,120), batch_size=128, epochs=20일 때
acc = 0.7164
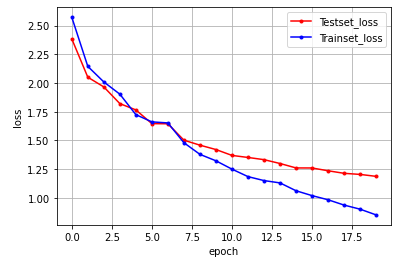
embedding(1000,120), batch_size=100, epochs=20일 때
acc = 0.7053
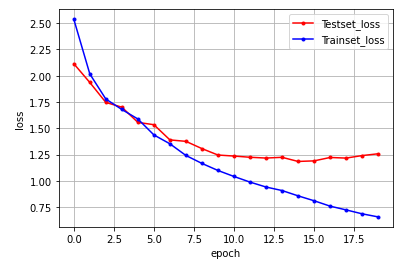
embedding(1000,100), batch_size=100, epochs=20일 때
- 속도가 위에 둘 보다 빠르다.
acc = 0.7119
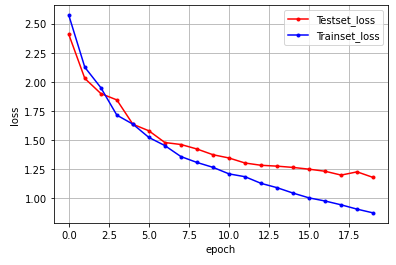
embedding(1000,120), batch_size=256, epochs=20일 때
acc = 0.6763
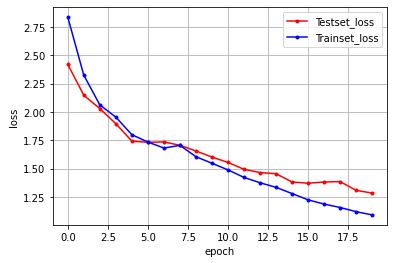
임베딩 벡터 차원을 줄였는데 acc가 높아지는 이유?
배치 사이즈가 크면 acc가 줄어든다고 배웠는데 위에서는 120 성능이 더 좋은 이유?
데이터가 작아서 그런가?
메일 보내기
