
information bottleneck의 근본 논문 (1999)

저의 최애 figure (이 논문 피겨는 아니지만...) 출처는 여기
bottleneck이라고 하는게 실제 병의 목 부분이 좁아서 내용물의 어떤 흐름을 제한하는 것처럼 정보처리에서도 중요한 정보만을 선택적으로 통과시키고 필요없는건 줄이는 과정임
그래서 복잡한 신호나 데이터에서 중요한 정보를 필터링 한다고 하고 모아서 요약.
학부 신호 수업때 읽은 기억이 아주 미세하게 남아있음 ...
정보를 어떻게 하면 효율적으로 요약하고, 의미 있는 정보만 추출할 수 있는지에 대한 방법
어떤 신호->다른 신호 제공하는 관련 정보를 정의하고 이를 최대화 하는 새로운 이론적 틀
2. Relevant quantization
두 신호 와 간의 관련 정보를 최대한 보존하면서 의 압축 표현인 을 찾는 것.
수학적으로 다음과 같은 최적화 문제로 표현할 수 잇음.

여기서 는 랑 그 압축 표현 사이의 상호 정보량을 나타냄
는 압축 표현이랑 사이의 상호 정보량
는 Largrange multiplier로 이 둘 값 사이의 균형을 조절
이 문제는 아래의 방정식을 통해 구할 수 있다.
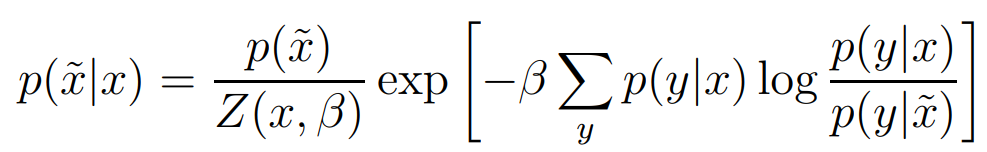
위 방정식은 Blahut-Arimoto 알고리즘을 일반화 한 것으로 반복적으로 넣어서 수렴할때까지.
3. Lossy compression
중요 정보만 보전하는 방법 -> 주어진 압축률에서 기대되는 distortion 수준을 min.
이거는 rate distortion theory를 통해 수식화 할 수 있음.
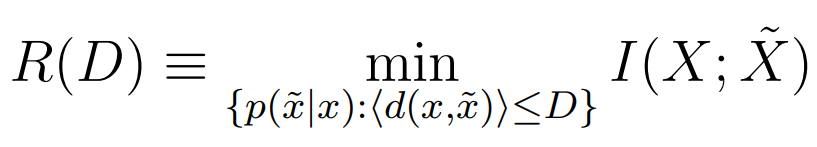
여기서 는 왜곡 함수로 랑 사이의 왜곡을 측정
는 이 왜곡에서 신호를 압축할 때 최소 비트 수를 정의한다.
4. Relevant Quantization
신호를 디지털 형식으로 변환하는 과정을 설명.
이 과정에서 정보 손실을 최소화하면서 신호를 효율적으로 표현할 수 있는지
신호 를 양자화된 로 매핑하는데 아래와 같이 표현

여기서 는 의 발생 확률
이 과정을 좋게하는 주요 요소는 신호를 얼마나 압축할지(양자화의 비율) 이랑 이 비율에 따라 달라지는 정보 손실정도.
5. Relevance through Distortion
중요성을 어떻게 파악하냐 에따라 정보가 다르게 해석될 수 있는데,
중요한 정보를 추출하고 보존하는 방법은 왜곡 함수 를 통해 구현된다.
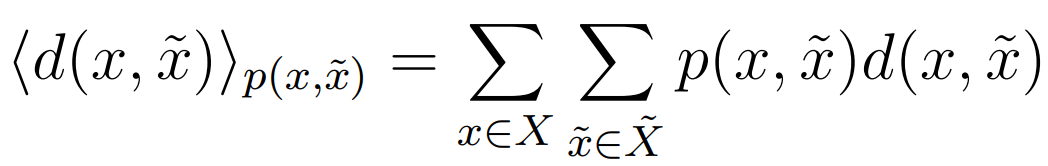
이 값을 최소화하는 것이 목표.
6. Information Bottleneck Iterative Algorithm
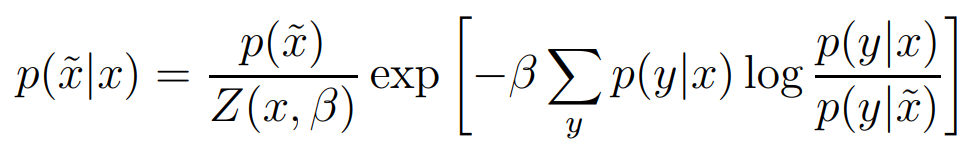
암튼 이거임...
한마디로 input X랑 latent T의 정보량은 최소가 되면서 동시에 latent T랑 target Y의 정보량은 최대가 되어야 하는긋
