Leave No Context Behind: Efficient Infinite Context Transformers with Infini-attention
Paper Review
구글에서 발표한 무한대 context를 다룰 수 있는 Infini-attention.
Transformer의 특징인 어텐션 구조를 새롭게 어찌저찌 해서 long context에서 효율적인 추론을 가능하게 했다.
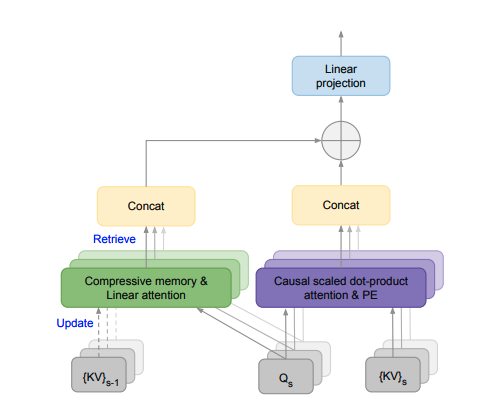
기존에는 attention 때문에 메모리가 제한적이엇음 근데 어케 무한?
Infini-attention 을 쓰면 됨 이거는 기존 어텐션에다가 Compressive memory를 넣고 하나의 transformer에서 masked-local attention + Long-term linear attention을 구축한다.
쿼리를 전달해주고 이전 값들이 업데이트 되면서 합쳐지며, 기존의 dot-product-attention이랑도 합쳐지는 형태같다. compressive memory랑 linear attention으로 정보를 보존하고, 메모리 효율적으로 처리하는게 특징
Method
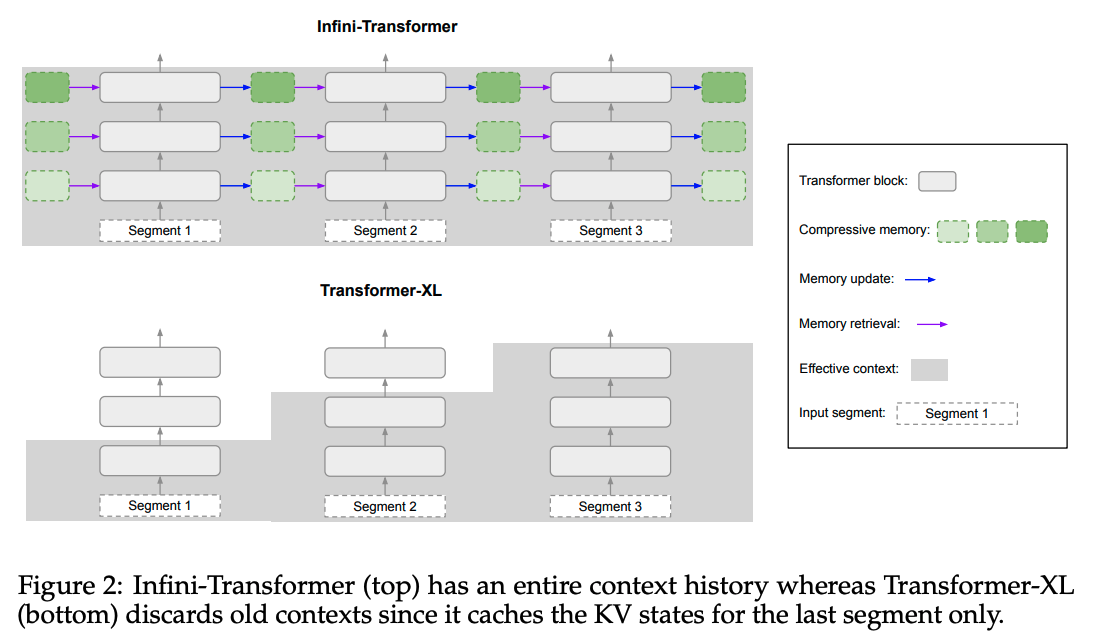
여기서는 Infini-transformer랑 Transformer-XL을 비교한다.
비슷하게 여러개의 시퀀스에서 작동하고...
원래 로컬 어텐션에서는 이전 세그먼트의 어텐션 상태를 다음 세그먼트 처리할 때 폐기하는데, Infini-transformer에서는 예전의 KV값의 어텐션 상태를 제외시키는 대신에 압축 메모리를 사용하여 전체 맥락을 유지하기 위해 얘네들을 재사용한다.
따라서 여기에서는 글로벌 compressive 상태랑 로컬 상태를 모두 갖고 있다.
결과는 좋음
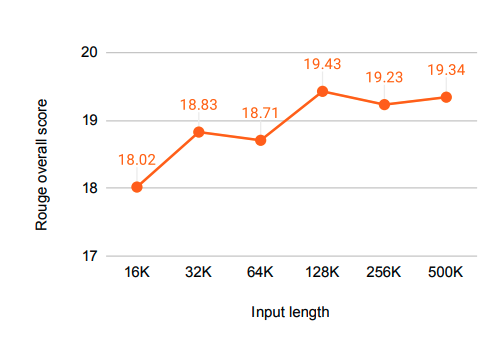
사실 디테일한 부분은 자세히 안들어가봤는데...
이런거 읽으면 읽을수록 클로드를 결제하고 싶어진단 말이지....
