하루 데이터가 68928건이라 한줄 한줄 넣으니까 너무 오래 걸려서 bulk방식(?)으로 넣어보았다.
pandas 이용
딕셔너리에 모든 데이터를 담고 데이터프레임으로 만들어서 쿼리를 날렸다.
for j in json_ar1:
stationName = j.get('stationName')
if stationName[0].isdigit():
stationName = stationName[5:].lstrip().rstrip()
dic['Date'].append(f'{yesterday.strftime("%Y-%m-%d")}" "{h}')
dic['stationId'].append(j.get('stationId'))
dic['stationName'].append(stationName)
dic['parkingBike'].append(j.get('parkingBikeTotCnt'))
dic['shared'].append(j.get('shared'))
dic['rackTotCnt'].append(j.get('rackTotCnt'))
dic['stationLatitude'].append(j.get('stationLatitude'))
dic['stationLongitude'].append(j.get('stationLongitude'))
df = pd.DataFrame(dic)
df.to_sql(name='bike', con=engine, if_exists='append', index=False)시간 비교
-
bulk 미사용
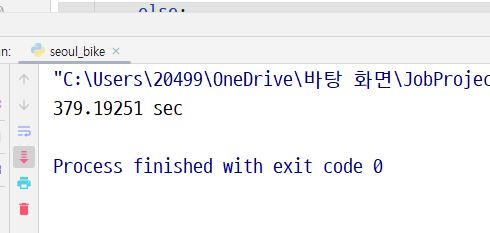
-
bulk 사용

시간 차이가 엄청나게 많이 났다.
전체 코드
# import time
import json
import requests
import pandas as pd
import pymysql
from sqlalchemy import create_engine
from datetime import date, timedelta
from collections import defaultdict
# start = time.time()
engine = create_engine('mysql+pymysql://bike:dbgusals1@localhost:3306/use_bike')
for h in range(24):
for i in range(1, 2002, 1000):
dic = defaultdict(list)
today = date.today()
yesterday = date.today() - timedelta(1)
if i == 2001:
url = f'http://openapi.seoul.go.kr:8088/707950714679377934386e64746352/json/bikeListHist/{2001}/{2872}/{yesterday.strftime("%Y%m%d")}{h}'
else:
url = f'http://openapi.seoul.go.kr:8088/707950714679377934386e64746352/json/bikeListHist/{i}/{i + 999}/{yesterday.strftime("%Y%m%d")}{h}'
response = requests.get(url)
json_ob = json.loads(response.content)
json_ar = json_ob.get('getStationListHist')
json_ar1 = json_ar.get('row')
for j in json_ar1:
stationName = j.get('stationName')
if stationName[0].isdigit():
stationName = stationName[5:].lstrip().rstrip()
dic['Date'].append(f'{yesterday.strftime("%Y-%m-%d")}" "{h}')
dic['stationId'].append(j.get('stationId'))
dic['stationName'].append(stationName)
dic['parkingBike'].append(j.get('parkingBikeTotCnt'))
dic['shared'].append(j.get('shared'))
dic['rackTotCnt'].append(j.get('rackTotCnt'))
dic['stationLatitude'].append(j.get('stationLatitude'))
dic['stationLongitude'].append(j.get('stationLongitude'))
df = pd.DataFrame(dic)
df.to_sql(name='bike', con=engine, if_exists='append', index=False)
# end = time.time()
# print(f"{end - start:.5f} sec")

smilegate