Efficient Estimation of Word Representations in Vector Space 논문에 대한 리뷰를 작성하기 이전에 해당 내용에 대해 먼저 숙지를 한 이후 작성하는 것이 좋을 것 같아 TIL 주제로 선정했습니다. Word2Vec을 기존에 정말 단순하게 배웠으나 상당히 중요 개념이기 때문에 이번 기회에 보다 집중해보았습니다.

💡 Word2Vec 무슨 뜻이야?
Word2Vec은 word embedding 방법론 중 한 방식입니다. 워드 임베딩(Word Embedding)은 단어를 벡터로 표현하는 방법으로, 단어를 벡터 그중에서도 밀집 표현으로 변환합니다.
1. 희소표현
희소표현은 one-hot encoding과 동일합니다. 모든 단어를 포괄하는 Vector의 차원에서 index 역할을 하는 하나의 숫자만 1이며 나머지는 모두 0입니다. 해당 표현은 공간적 낭비를 불러 일으키기 때문에 특별한 상황이 아닌 이상 word embedding으로 사용되지는 않습니다.
2. 밀집표현
밀집 표현은 희소표현과 달리 단어를 사용자가 설정한 값으로 벡터 표현의 차원을 맞추어 표현하는 방식입니다. 벡터 내의 숫자는 실수를 가지며 index 역할을 하는 것이 아니라 단어를 표현하는 일련의 숫자들이 들어갑니다.
3. Word Embedding
단어를 밀집 벡터(dense vector)의 형태로 표현하는 방법을 워드 임베딩(word embedding)이라고 합니다. 그리고 이 밀집 벡터를 워드 임베딩 과정을 통해 나온 결과라고 하여 임베딩 벡터(embedding vector)라고도 합니다.
워드 임베딩 방법론은 매우 다양하며 LSA, Word2Vec, FastText, Glove 등이 있습니다. 케라스에서 제공하는 함수인 Embedding()는 앞서 언급한 방법들이 아니라 단어를 랜덤한 값을 가지는 밀집 벡터로 변환한 뒤에, 인공 신경망의 가중치를 학습하는 것과 같은 방식으로 단어 벡터를 학습하는 방법입니다.
이러한 방식으로 만들어진 word vector 중에 Word2Vec 방식은 CBOW(Continuous Bag of Words)와 Skip-gram 방식으로 나뉩니다.
CBOW 모델은 맥락으로부터 타깃 word를 예측하는 모델 구조입니다. ('타깃'은 중앙 단어이고, '맥락'은 선행 후행하는 일정 범위의 주변 단어들입니다.) Skip-gram은 반대로 타깃으로부터 맥락을 예측하는 용도의 신경망입니다.
여기서 맥락에 해당하는 주변의 단어들은 Window라고 얘기합니다. Window size가 2라는 것은 선행, 후행 단어 두 개를
💡 CBOW
window 설정 후 문장을 따라 중심단어를 뒤로 이동시키면서 타깃 word와 주변 word를 뽑아 데이터셋으로 만들어 줍니다. 이 방식을 슬라이딩 윈도우(Sliding window)라고 합니다.
이때, Word2Vec 학습을 위한 입력, 출력은 모두 원-핫 인코딩을 선행해야 합니다. 그리고 이를 통해 CBOW 신경망을 학습시킵니다.
CBOW 신경망을 학습시켜 나온 최적의 가중치가 바로 word embedding vector입니다. CBOW 모델은 맥락 단어로부터 타깃 단어를 예측하는 모델이므로 CBOW input은 맥락 word들의 one-hot 벡터이고, output은 타깃 word의 one-hot 벡터입니다.(그래야 word로 변환시킬 수 있으므로)
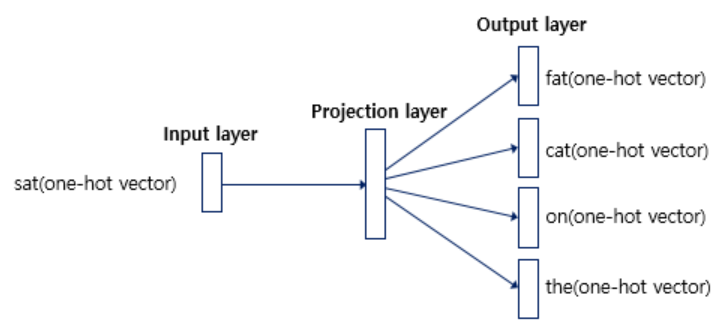
아래는 학습의 흐름도 이며 windwo size를 2로 했을 때입니다.

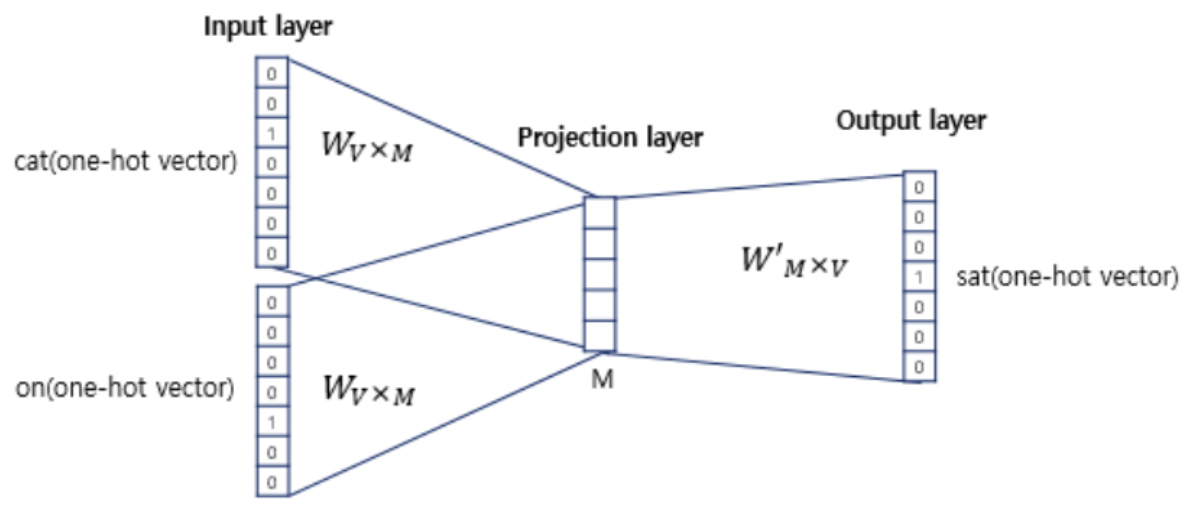
입출력 데이터가 모두 원-핫 벡터임을 알 수 있습니다. 여기서 투사층(projection layer)의 크기는 M인데 이는 워드 임베딩 결과의 차원입니다. 단어는 1 x V vector이며(V는 단어들의 크기) 이것이 을 만나 1 x M vector로 변환됩니다. 이때, 기존의 input vector는 한 숫자만 1이기 때문에 1이 있는 index만 곱해진 결과가 나타나게 됩니다. 즉, 가중치 행렬 W에서 '입력 벡터에서 1이 포함된 인덱스'에 해당하는 행을 추출하는 작업일 뿐입니다. 다시 말해, input one-hot 벡터 에서 1의 값을 가지고 있는 인덱스를 i라 할 때, 가중치 행렬 W의 i번째 행을 가져오는 작업입니다.
즉, Word2Vec의 은닉층을 계산하는 작업은 사실상 가중치행렬 𝑊에서 해당 단어에 해당하는 행벡터를 참조(lookup)해 오는 방식입니다.
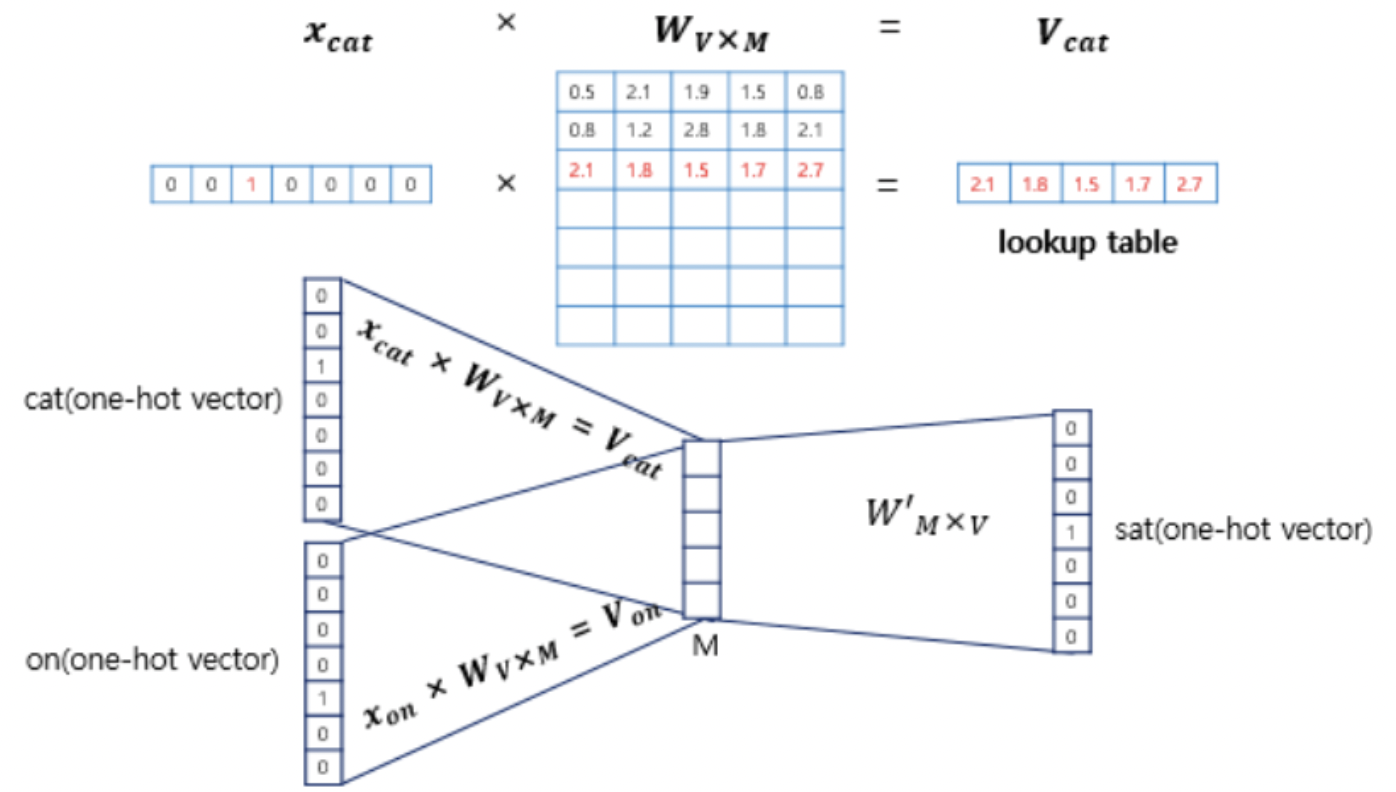
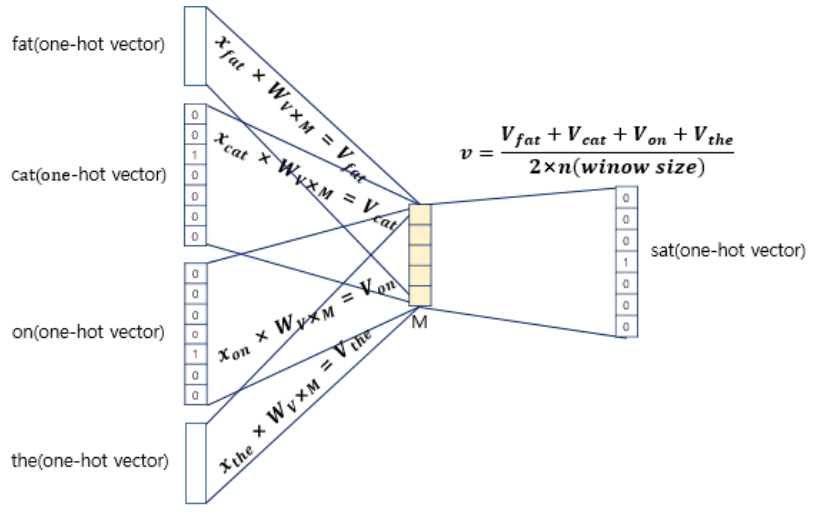
입력인 맥락 단어가 총 4개이므로 각 입력 원-핫 벡터와 가중치 행렬 W를 곱한 벡터 v가 4개 도출될 것입니다. 이제 이 벡터들의 평균 벡터를 구해야 합니다. 구해진 모든 v벡터 (v_fat, v_eat, v_on, v_the)를 더한 뒤 4로 나누어주면 됩니다. 이때 4는 window size * 2 결국 선행, 후행 단어 개수의 총합입니다. 결과적으로 projection layer는 모든 단어들이 공유하게 됩니다.
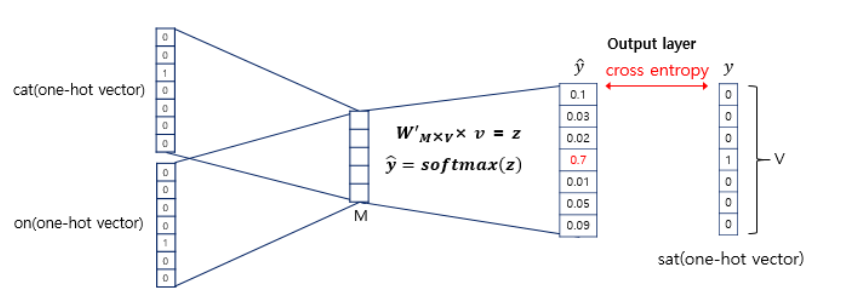
그후, 이것들을 통해 만들어진 1 x M vector는 를 만나 다시 1 x V vector로 나타나게 됩니다. 이렇게 나타난 결과에 softmax를 취하면 확률값을 지니는 변환됩니다. 그리고 이것과 실제 값과의 cross-entropy를 통해 나타난 것을 loss로 사용합니다.
손실 함수로 cross-entropy를 사용하며 CBOW 신경망을 통해 최종적으로 도출한 벡터가 타깃 벡터와 최대한 유사하게 만들어주는 것이 목표입니다. 학습을 반복하며 가중치 행렬 W와 W'를 갱신하는데 신기하게도 학습이 잘 되면 W와 W'의 값은 거의 비슷하기 때문에 어떤 것을 워드 임베딩 행렬로 사용해도 됩니다. 때로는 W와 W'의 평균값을 사용하기 합니다.
💡 Skip-gram
Word2Vec에서 가장 성능이 높은 방식이며 타깃 word로부터 맥락 단어를 예측하는 모델구조를 지니고 있습니다.
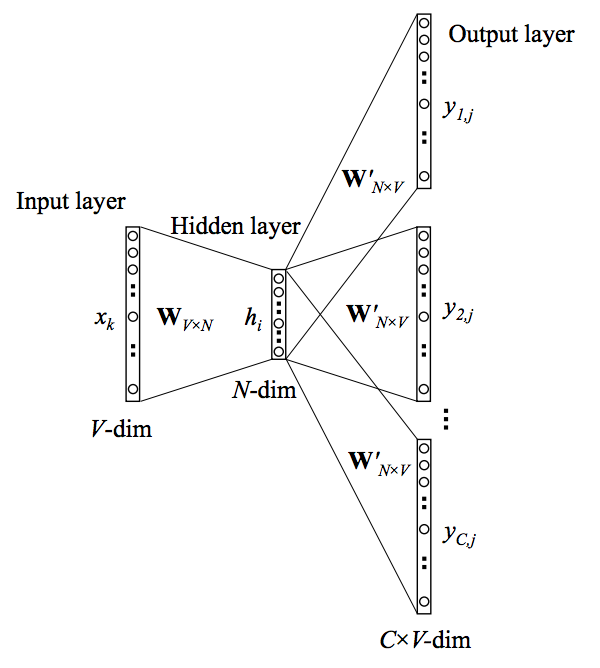
𝑉 는 임베딩하려는 단어의 수, 𝑁은 은닉층의 노드 개수(사용자 지정)입니다. Word2Vec은 최초 입력으로 CBOW와 동일하게 one-hot-vector를 받습니다. 1×𝑉 크기의 one-hot-vector의 각 요소와 은닉층의 𝑁개 각 노드는 1대1 대응이 이뤄져야 하므로 가중치행렬 𝑊의 크기는 𝑉×𝑁이 됩니다.
input으로 단 하나의 one-hot vector만 들어오기 때문에 hidden layer를 사용하지 않습니다. 가중치 W행렬을 곱해서 i번째 행을 추출한 후에 Projection layer를 통해 단어들을 예측하는 방식입니다. 즉 CBOW와 마찬가지로, 𝑊가 one-hot-encoding된 입력벡터와 은닉층을 이어주는 가중치행렬임과 동시에 Word2Vec의 최종 결과물인 임베딩 단어벡터의 모음이라는 것입니다.
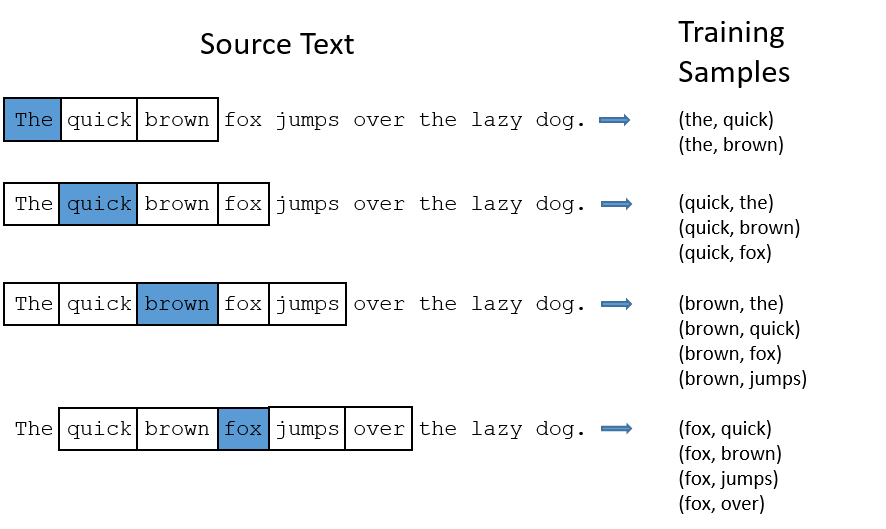
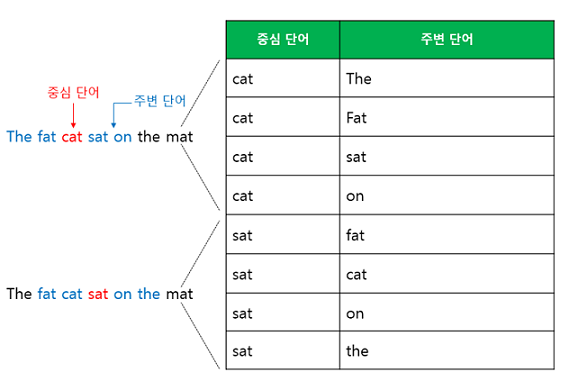
해당 방식은 중심 word와 target word에 해당하는 주변부 단어들을 set으로 제공해 예측하도록 학습시킵니다. 이때 주의할 것은 학습할 때 ‘quick’과 ‘brown’을 따로 떼어서 각각 학습한다는 점입니다. 중심단어에 ‘The’를 넣고 ‘quick’을 주변단어 정답으로 두어서 한번 학습하고, 또 다시 ‘The’를 중심단어로 하고 ‘brown’을 주변단어로 해서 한번 더 학습한다는 얘기입니다.
이렇게 첫번째 스텝이 종료되면 문장을 따라 중심단어를 옮겨 ‘quick’을 중심단어로 하고, ‘The’, ‘brown’, ‘fox’를 각각 주변단어 정답으로 두는 두번째 스텝을 진행하합니다. 이런 식으로 말뭉치 내에 존재하는 모든 단어를 윈도우 크기로 슬라이딩해가며 학습을 하면 iteration 1회가 마무리됩니다.
여기서 CBOW보다 Skip-gram이 높은 성능을 보이는 이유가 나타닙니다. 언뜻 생각하기에는 주변의 네 개 단어(윈도우=2인 경우)를 가지고 중심단어를 맞추는 것이 성능이 좋아보일 수 있습니다. 그러나 CBOW의 경우 중심단어(벡터)는 단 한번의 업데이트 기회만 갖습니다.
반면 윈도우 크기가 2인 Skip-gram의 경우 중심단어는 업데이트 기회를 4번이나 확보할 수 있습니다. 말뭉치 크기가 동일하더라도 학습량이 네 배 차이난다는 이야기이죠. 이 때문에 요즘은 Word2Vec을 수행할 때 Skip-gram으로 대동단결하는 분위기입니다.
개념 자체를 논문에서 봤을 때는 조금 어려웠지만 공부하다보니 쉬운 내용이었다.
틀린 부분 지적은 언제나 환영입니다 :)
출처 : https://wikidocs.net/33520
https://bkshin.tistory.com/entry/NLP-11-Word2Vec
https://ratsgo.github.io/from%20frequency%20to%20semantics/2017/03/30/word2vec/
사진 출처 : 딥러닝을 이용한 자연어처리

안녕하세요, 좋은 설명 잘 봤습니다.
한 가지 궁금한 점이 생겨 댓글 남깁니다. Skip-gram 모델은 hidden layer에서 얻은 벡터 값과 가중치 W'n*v 로 곱할 때 2m만큼의 주변 단어들의 one-hot vector가 나옵니다. 이때 혹시 가중치 값이 다 다른가요? 만약 가중치 값이 똑같으면 one-hot vector도 다 같아져서 모든 주변 단어들의 벡터가 동일하게 나오는걸로 예상됩니다. 이 점에 대해서 설명 주시면 정말 감사하겠습니다.