
🙄 Seaborn 이란?
👉 다양한 그래프를 제공하는 라이브러리
🙄 KDE Plot
➡ KDE Plot이란?
👉 Kernel Density Estimation
: 갖고 있는 데이터 기반으로 추정치를 이용해 확률밀도 함수 출력
: 히스토그램이 절대량(count)을 표현한다면 kdeplot은 상대량(비율) 표현
👉
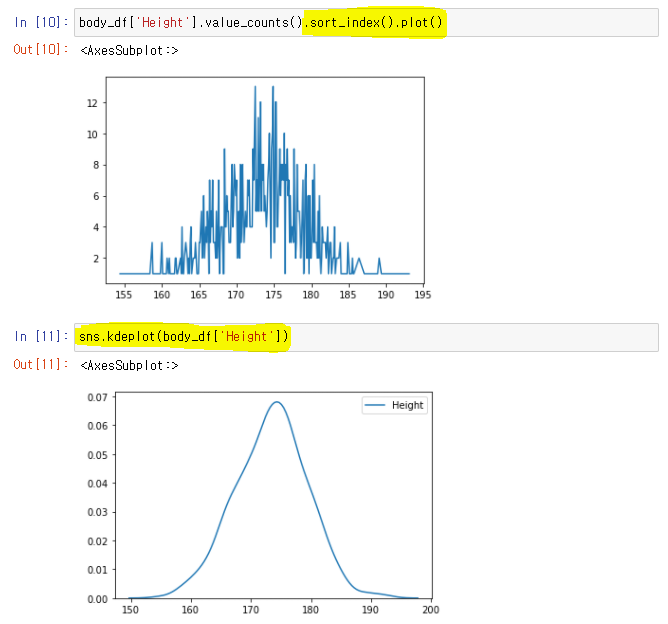
df['Column'].value_counts().sort_index().plot()
: Data 값들 정렬 후 그래프
👉sns.kdeplot(Series): 확률밀도함수
👉
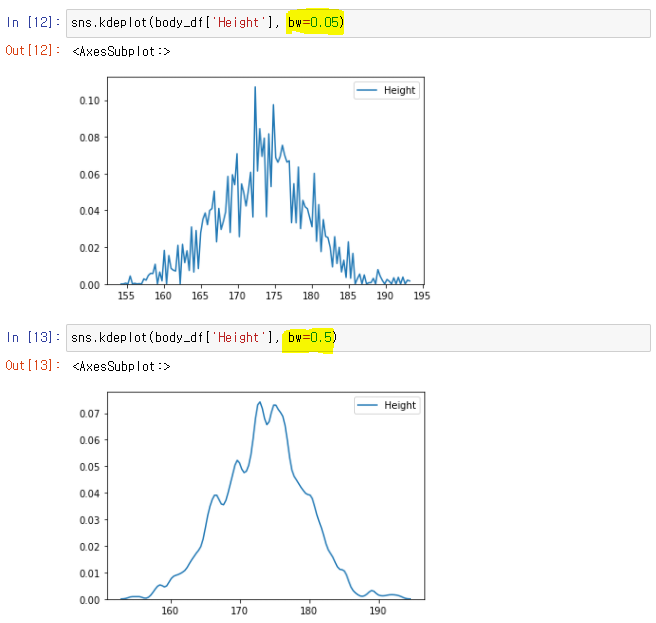
bw를 통해 추정 정도를 결정할 수 있다.
👉 값이 클 수록 더 부드러운 곡선
👉 실제 값과 오차가 존재해 적정한 수치를 설정해줘야함. 히스토그램 bins 같은 역할
➡ KDE Plot 활용 예시

👉
sns.distplot(Series, bins=)를 이용해 히스토그램과 같이 볼 수 있다.
👉sns.violinplot(y= )를 이용해 바이올린 그래프 출력, x 값을 지정하면 가로대칭

👉
sns.kdeplot(Series, Series)두 가지 입력하여 상관관계 파악 가능
👉 위 등고선 그래프를 각각 x축, y축과 평행하게 자르면 단면이 확률밀도함수와 같다
🙄 LM Plot
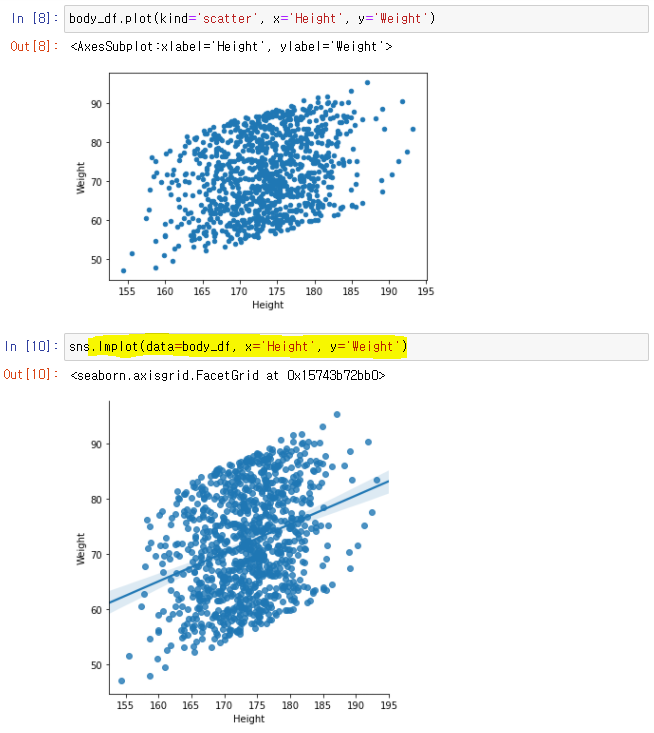
👉
sns.lmplot(data=df, x='Series', y='Series')
👉회귀선: 흩어져 있는 점들을 하나의 선으로 표현하기 위해 최선을 다한 직선
👉 회귀선을 통해 예측가능,상관관계가 강할 수록 직선에 가까워 더 정확한 예측 가능
🙄 카테고리별 시각화
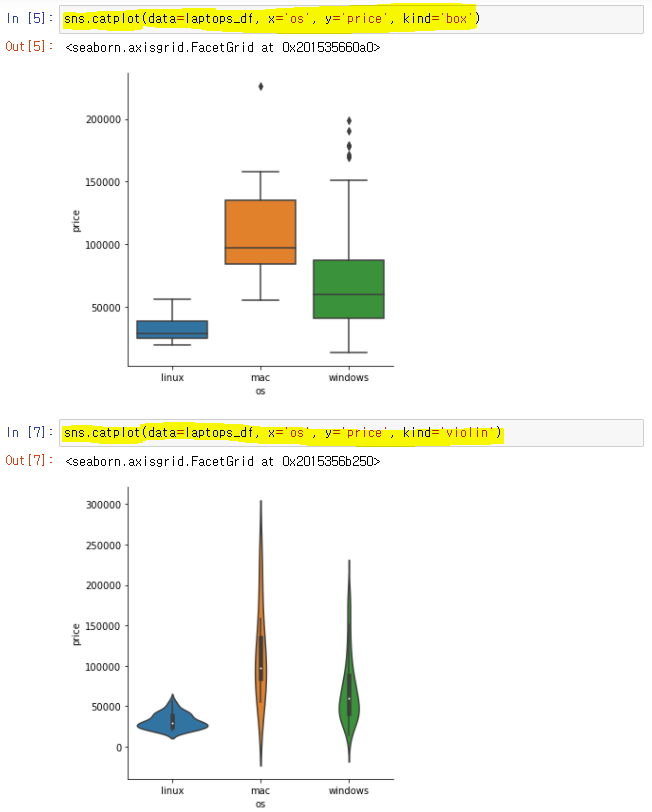
👉
sns.catplot(data=df, x='Series', y='Series', kind=' ')
👉 kind에 따라 다른 그래프로 카테고리별 비교 가능
👉 Data 분포를 알 수 있지만 개수를 알 수 없다는 단점
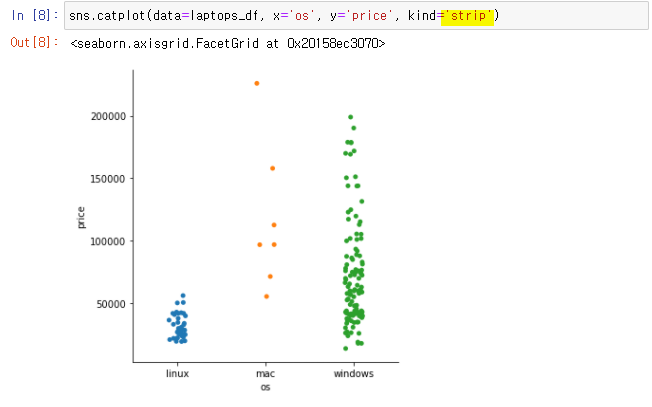
👉
kind = 'strip'으로 Data 분포와 개수 파악 가능
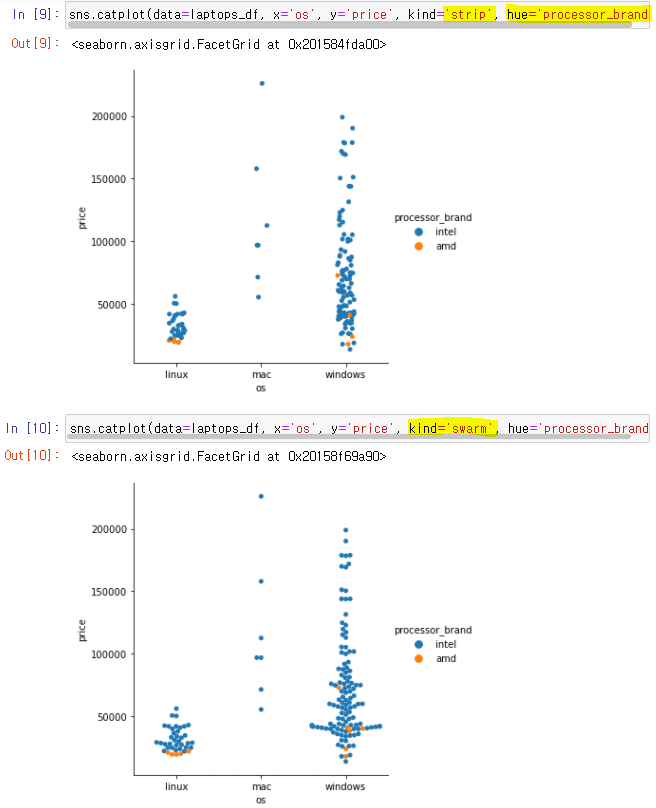
👉
hue='Series': hue는 색을 의미 'processor_brand' 에 따라 색을 다르게 출력
👉kind='swarm': 점들이 겹치지 않게 옆으로 출력
.png)