
최근 Image classification 문제를 해결해보면서 ViT를 사용해보았다.
ViT의 논문을 읽고 코드 작성법을 익혀서 사용해보며 작은 데이터에 최적인 더 작은 모델을 찾게 되었고 SwinT의 논문을 읽게 되었다.
이 둘을 CIFAR-10 데이터로 2epoch의 batchsize 8의 같은 hyperparameter로 어떤 결과가 생길지 확인해 보았다.
Data
label2id = {"plane":0, "car":1, "bird":2, "cat":3, "deer":4, "dog":5, "frog":6, "horse":7, "ship":8, "truck":9}
id2label = {0:"plane", 1:"car", 2:"bird", 3:"cat", 4:"deer", 5:"dog", 6:"frog", 7:"horse", 8:"ship", 9:"truck"}다음과 같이 id와 label의 관계를 dictionary로 정의해 model에 넣을 수 있다.
feature_extractors는 모델의 이름을 넣어서 사용한다.
# ViT feature extractor
model_name_or_path = 'google/vit-base-patch16-224-in21k'
feature_extractor = ViTFeatureExtractor.from_pretrained(model_name_or_path)
# SwinT feature extractor
model_name_or_path = 'microsoft/swin-tiny-patch4-window7-224'
feature_extractor = AutoImageProcessor.from_pretrained(model_name_or_path)from torchvision.transforms import (
CenterCrop,
Compose,
Normalize,
RandomHorizontalFlip,
RandomResizedCrop,
Resize,
ToTensor,
)
normalize = Normalize(mean=feature_extractor.image_mean, std=feature_extractor.image_std)
train_transforms = Compose(
[
RandomResizedCrop((feature_extractor.size['height'], feature_extractor.size['width'])),
RandomHorizontalFlip(),
ToTensor(),
normalize,
]
)
val_transforms = Compose(
[
Resize((feature_extractor.size['height'], feature_extractor.size['width'])),
CenterCrop((feature_extractor.size['height'], feature_extractor.size['width'])),
ToTensor(),
normalize,
]
)
def preprocess_train(example_batch):
"""Apply train_transforms across a batch."""
example_batch["pixel_values"] = [
train_transforms(image.convert("RGB")) for image in example_batch["img"]
]
return example_batch
def preprocess_val(example_batch):
"""Apply val_transforms across a batch."""
example_batch["pixel_values"] = [val_transforms(image.convert("RGB")) for image in example_batch["img"]]
return example_batchdata는 다음과 같이 transform 시킨다.
feature_extractor에 정의한 대로 image를 crop시킨다.
Training
tarining은 hugging face의 trainer API를 사용했다. 굉장히 편하고 자동 scheduler가 learning rate를 적절하게 조절해주기 때문에 매우 편하다.
model = SwinForImageClassification.from_pretrained(
model_name_or_path,
num_labels=10,
id2label=id2label,
label2id=label2id,
ignore_mismatched_sizes = True)모델은 다음과 같이 정의한다.
ViT: 'google/vit-base-patch16-224-in21k'
SwinT: 'microsoft/swin-tiny-patch4-window7-224'
metric = load_metric("accuracy")
def compute_metrics(eval_pred):
"""Computes accuracy on a batch of predictions"""
predictions = np.argmax(eval_pred.predictions, axis=1)
return metric.compute(predictions=predictions, references=eval_pred.label_ids)
def collate_fn(examples):
pixel_values = torch.stack([example["pixel_values"] for example in examples])
labels = torch.tensor([example["label"] for example in examples])
return {"pixel_values": pixel_values, "labels": labels}metric은 accuracy로 했고 metric 계산 function과 collate function을 정의해준다.
training_args = TrainingArguments(output_dir="./",
remove_unused_columns=False,
evaluation_strategy = "epoch",
save_strategy = "epoch",
learning_rate=5e-5,
per_device_train_batch_size=8,
gradient_accumulation_steps=4,
per_device_eval_batch_size=8,
num_train_epochs=2,
warmup_ratio=0.1,
logging_steps=10,
load_best_model_at_end=True,
metric_for_best_model="accuracy",
)
trainer = Trainer(
model=model.to(torch.device('mps')),
args=training_args,
train_dataset=train_ds,
eval_dataset=val_ds,
tokenizer=feature_extractor,
compute_metrics=compute_metrics,
data_collator=collate_fn,
)2개의 가장 좋은 model을 저장 가능한 argument이다.
기본적으로 epochs랑 batchsize는 위에서 말한 조건대로 두 모델 2,8로 지정해 두었다.
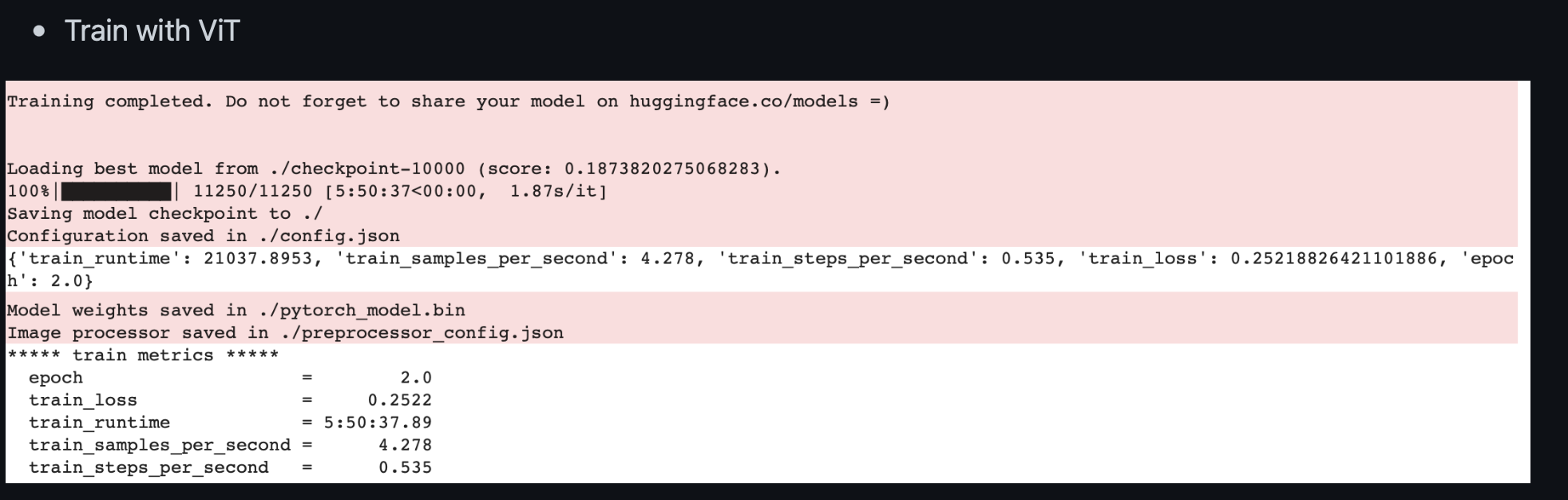
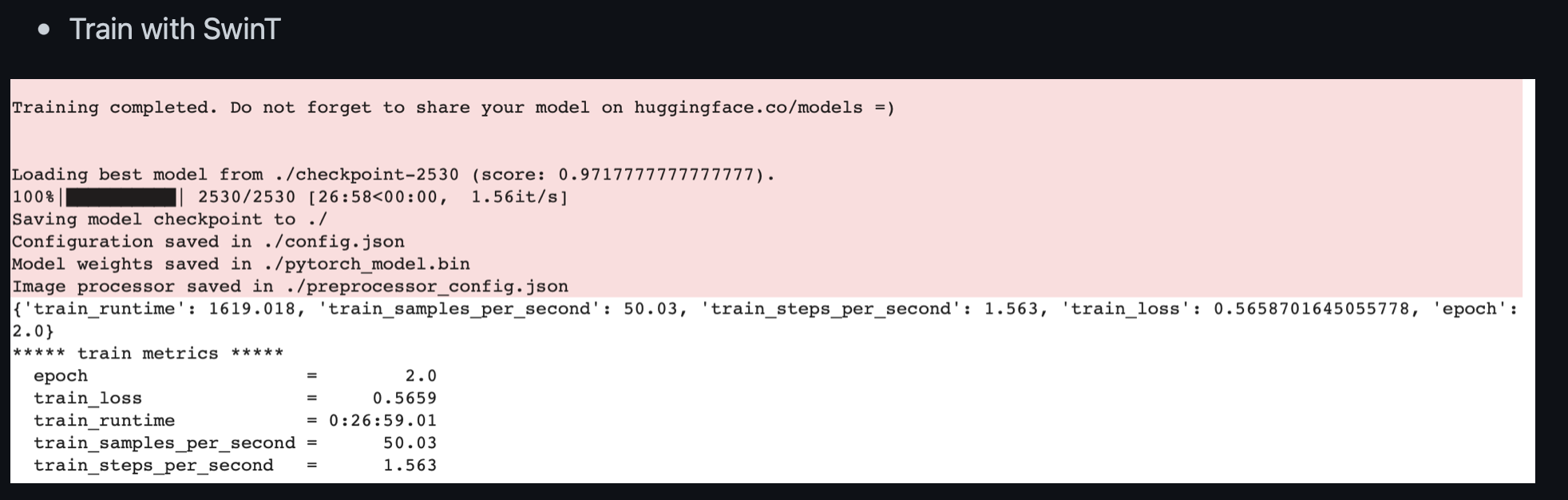
Training 결과는 다음과 같다.
중요하게 살펴볼 부분은 시간이다. ViT는 5시간 50분 걸린 반면 SwinT는 26분이란 짧은 시간이 걸렸다.
실제 SwinT는 shifted window와 cyclic shift는 계산량을 많이 줄여 training 시간을 많이 단축시킨다. 실험 결과 약 93%의 단축 효과가 있었다.
또한 inductive bias를 가져 짧은 학습 후 비교일 수록 더 큰 성능을 나타내는 것 같다.
실제로 SOTA 에는 ViT가 많이 보이는데 inductive bias의 한계 또는 더 넓은 공간속 정보공유를 가지는 full attention mechanism이 많은 데이터와 긴 학습에서는 더 유리한 것 같다.
Testing
# Predictions
y_test_predict = trainer.predict(prepared_ds_test)
# Take a look at the predictions
y_test_predict같은 Traininer의 predict를 사용하면 손쉽게 reference label data를 얻을 수 있다.
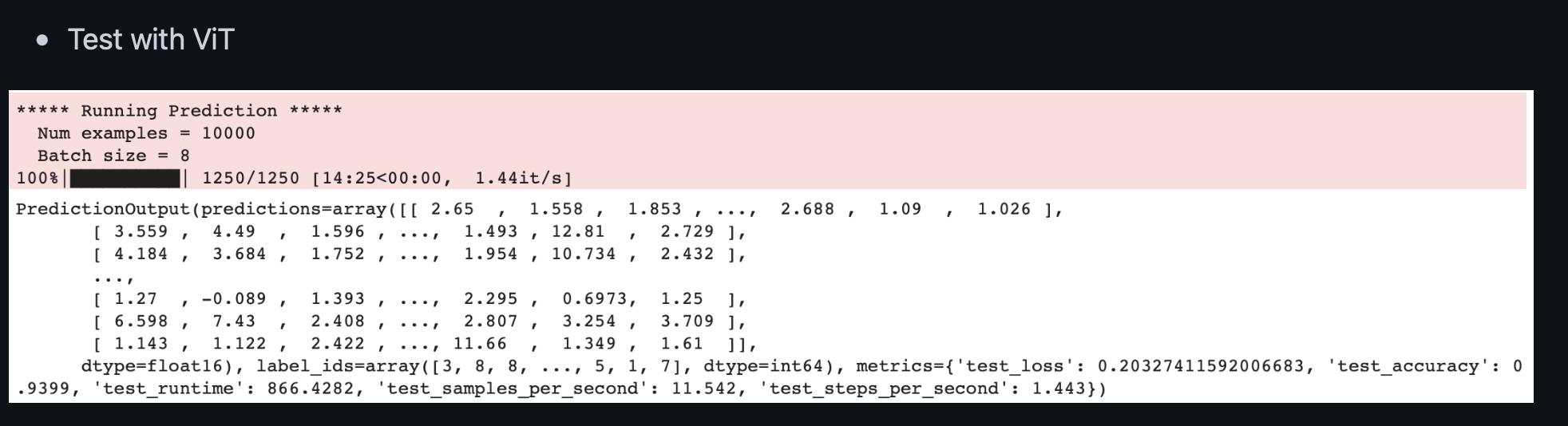
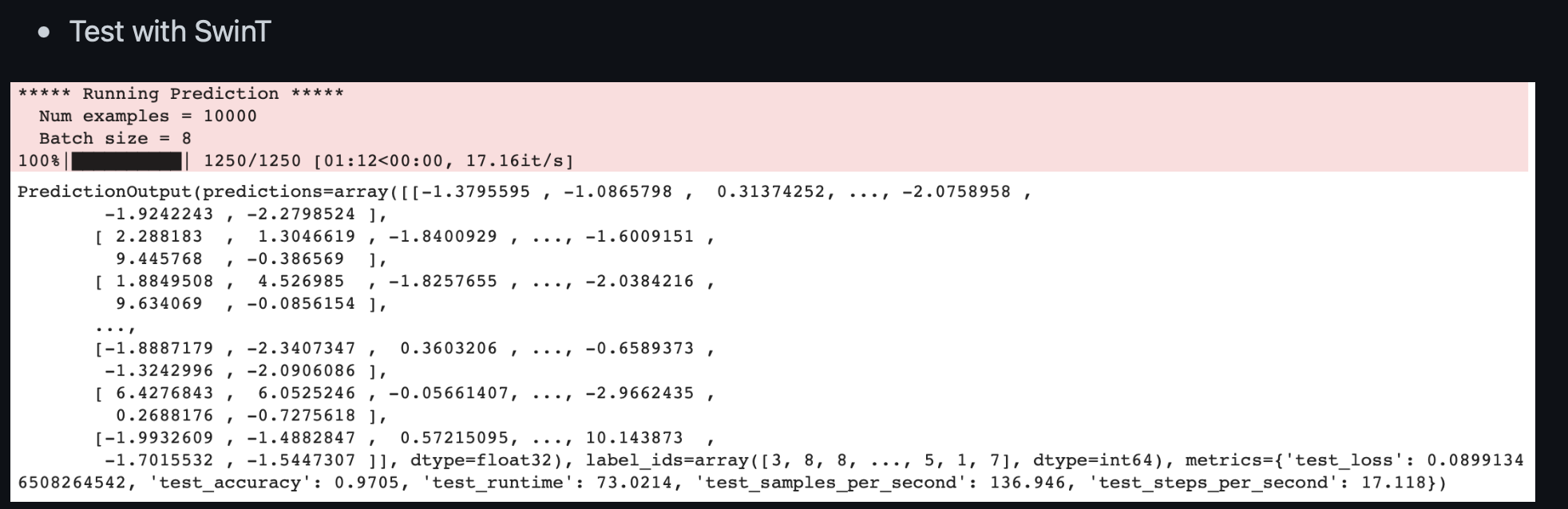
결과는 놀랍게도 SwinT의 4% 더 높은 성능이다.
둘다 2epoch이란 작은 epoch에도 좋은 성능을 보여줬다. 실제 같은 hyperparameter로 ResNet18에서는 이정도 성능은 보이기 어려웠던 것 같다.
이상으로 실험을 마쳤다. 위 코드들은 앞으로 다른 Image classification에서 데이터만 교체해서 잘 사용할 것 같다.
url: https://github.com/SeoungHyuckWon/Comparision_ViT_and_SwinT
