
Abstract
large-scale NLP 모델은 signs of saturation없이 language 작업의 성능을 현저하게 향상시켰고 few-shot capabilities의 인간의 성능을 보인다. 이 논문은 CV에서 large-scale models을 탐구하는 것을 목표로 한다.
large-scale vision model을 학습하는데 3가지 문제점이 생긴다.
1. 학습 불안전성
2. pretraining과 finetuning 간의 resolution gap
3. hunger on labelled data
3가지 문제점에 대한 주요 기술은 다음과 같다.
1. a residual-post-norm method combined with cosine attention
2. A log-spaced continuous position bias
3. A self-supervised pretraining method, SimMIM
위 방법으로 3B개의 parameter을 가진 Swin Transformer V2 model을 성공적으로 훈련함
최대 1,536×1,536 resolution을 가짐.
4가지 task에서 SOTA를 기록함.
Introduction
언어모델의 확장은 성공적이었다. large-scale BERT는 놀라운 성능을 보여줬고 few-shot capabilities를 보유하고 있다.
반면 vision model의 scale up은 뒤쳐져 있다. 큰 vision model 이 일반적으로 더 나은 성능을 보이는 사실은 알려져 왔지만 최근에야 10~20B 크기의 모델이 생겼다. 심지어 이런 vision model은 image classification 작업만 가능하다.
large-scale vision model을 성공적으로 훈련하려면 몇가지 주요 문제를 해결해야한다.
large-scale vision model의 훈련 실험에서 instability issue
layer 사이에 discrepancy of activation amplitudes가 상당히 커지는 것을 발견했다.
-> the output of the residual unit이 the main branch에 직접 다시 추가되기 때문에 발생.
해결법
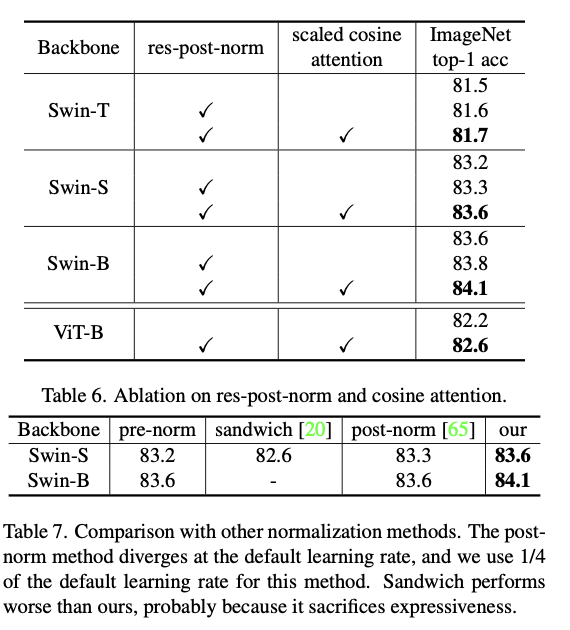
1. res-post-norm: residual unit시작부분에서 backend로 LN layer을 이동하는 새로운 정규화 구성. -> 전반적으로 훨씬 milder activation values를 생성
2. scaled cosine attention:
이전 dot product attention을 대체 -> 입력의 amplitude와 무관하게 이루어지므로 값이 극단으로 치우칠 가능성 적음.
-> 훈련 프로세스를 안정적으로 만들고 정확도를 향상.
require high resolution input images or large attention windows
many downstream vision tasks such as object detection and semantic segmentation에는 high resolution input image나 large attention windows가 요구된다.
low-resolution pre-training 과 high-resolution fine-tuning 간의 window 크기 차이는 상당히 클 수 있다.
임시 방법으로 위치 bias map의 bi-cubic interpolation가 존재하지만 임시방편이며 최적이 아님.
해결법
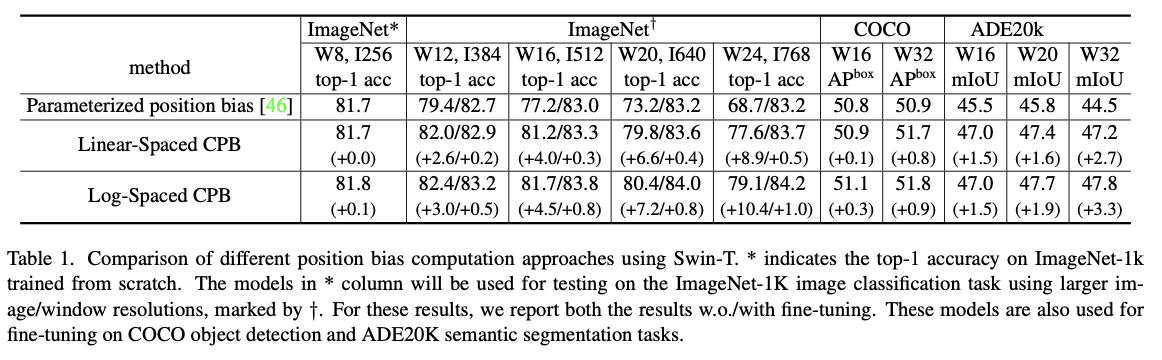
log-spaced continuous position bias (Log-CPB)을 도입.
log 간격 좌표 입력에 작은 meta network를 적용하여 임의의 좌표 범위에 대한 bias값을 생성. -> pre-trained 모델은 meta network의 weight를 공유하여 window 크기 간에 자유롭게 전송 가능.
그 외에도 GPU가 많이 드는 문제를 zero-optimizer, activation check pointing 과 a novel implementation of sequential self-attention computation을 합쳐 기술통합.
다양한 bechmark 에서 좋은 정확도를 얻음.
Related Works
Language networks and scaling up
언어모델의 증가: BERT-340M -> Megatron-Turing-530B
zero-shot or few-show 등에서 성능향상
Vision networks and scaling up
CNN의 여러 모델들이 vision 에서 사용.
kinetics-400 에서 transformer가 제안되며 그뒤 transforemr의 확장 연구가 진행됨.
Transferring across window / kernel resolution
CNN의 경우 kernel 크기를 고정했다. global ViT는 이미지 resolution 증가에 선형적으로 비례하는 동등한 크기의 attention 연산을 한다. swin같은 local ViT는 finetuning 작업에서 window를 고정하거나 변경할 수 있다. 가변 window size를 허용하면 가변적인 feature map으로 나눌 수 있고 더 나은 수용 필드를 조정할 수 있어서 사용하기 편리하다. 그리고 위 논문은 bi-cubic interpolation이란 일반적인 관행 대신 Log-CPB를 제안한다.
Study on bias terms
NLP에서 relative position bias가 absolute position embedding보다 더 효과적임이 밝혀졌다.
Swin Transformer V2
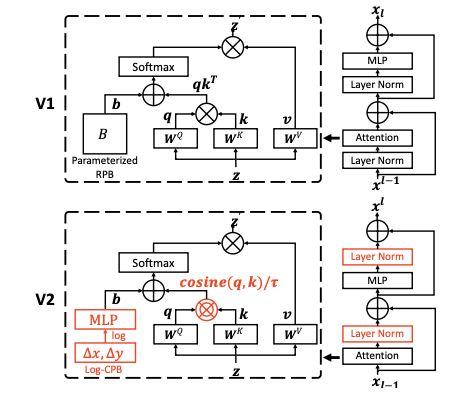
Relative position bias
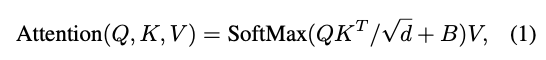
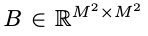
B는 각 head의 relative position bias term 이다. M^2은 window의 patch 개수이다.
Issues in scaling up model capacity and window resolution
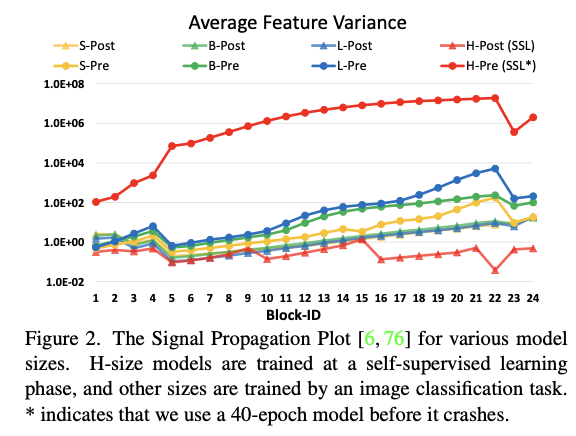
scaling up model capacity를 할 때 instability issue 가 발생.
original SwinT는 작은 크기에서 큰 크기로 확장하면 더 깊은 층의 activation 값이 급격히 증가. 가장 높은 amplitude를 가진 layer와 가장 낮은 amplitude를 가진 layer간의 instability는 10^4이라는 극단적인 값에 도달.
window resolution 간에 모델을 전송할 때 성능저하를 figure 1으로 확인가능. pretrained된 imagenet-1k 모델(256 size, 8 windows)의 정확도를 더 큰 image resolution 및 window 크기에서 직접 테스트 하면 정확도 크게 감소.
Scaling Up Model Capacity
Post normalization
LN의 위치를 바꾸는 post normailization 으로 문제 완화.
layer가 깊어져도 amplitude가 누적되지 않음. pre보다 훨씬 완만.
Scaled cosine attention
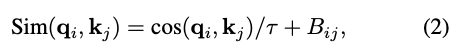
단순 matmul 대신 res-post-norm을 구성하고 scaled cosine function을 제안함.
Bij는 픽셀 i 와 j 사이의 relative positon bias이고 τ는 학습 가능한 scalar이다. 0.01보다 크게 설정된다.
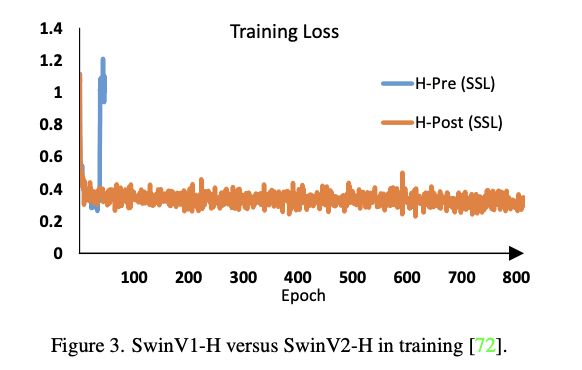
Scaling Up Window Resolution
Continuous relative position bias
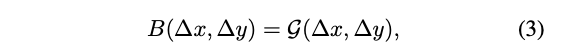
directly optimizing the parameterized biases대신 continuous position bias approach는 a small meta network를 채택한다.
G가 small network이다.(ReLU가 포함된 2계층 MLP)
meta network는 임의의 relative 좌표에 대한 bias 값을 생성하므로 window 크기를 변경하는 finetuing 작업으로 자연스럽게 이전할 수 있다.
Log-spaced coordinates
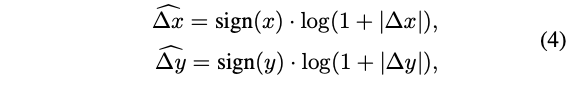
다양한 window 크기로 전송하기 위한 부분중 linear 한 것 대신 log-spaced coordinates를 쓴다.
Implementation to Save GPU Memory
zero optimizer: model parameter와 해당 optimization 상태가 분할되어 GPU에 분산되므로 메모리 소비를 획기적으로 줄인다.
Activation check-pointing: transformer layer의 feature map도 많은 gpu memory를 소비하며 이미지와 window resolution이 큰 경우 bottle-neck 현상이 발생할 수 있다. Activation check-pointing를 사용하면 메모리를 크게 줄이는 대신 학습 속도가 최대 30% 느려진다.
Sequential self-attention computation: 위의 두 방법으로 여전히 저렴하지 않기 때문에 self attention module이 bottle-neck 현상을 일으킴을 발견하고 이 문제를 완화하기 위해 self-attention 을 sequentially하게 구현했다.
Experiment
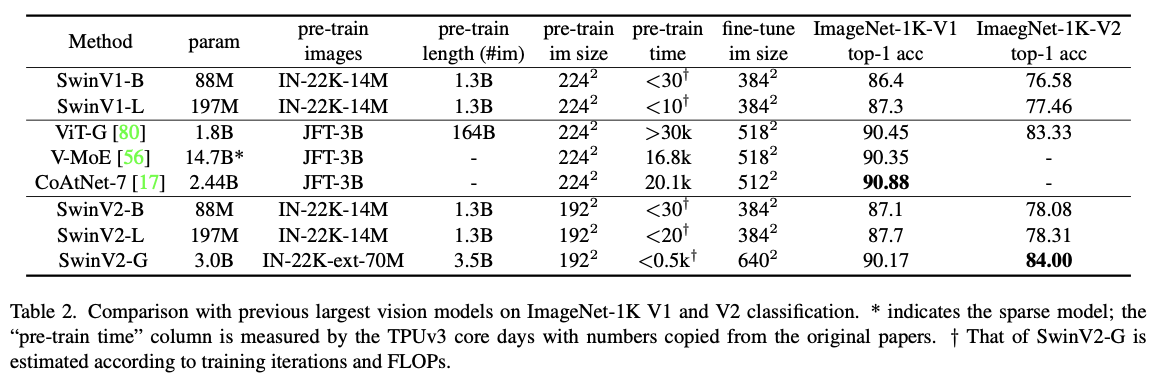
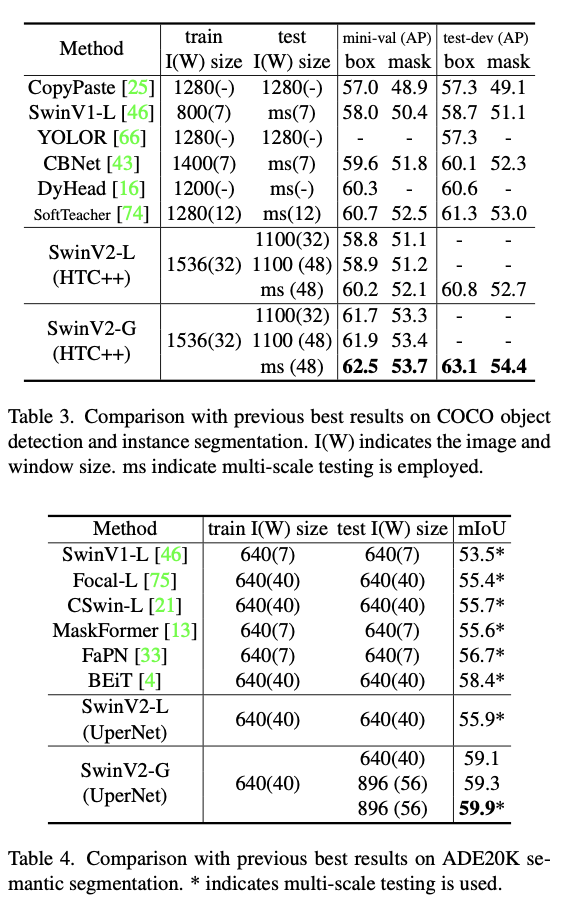
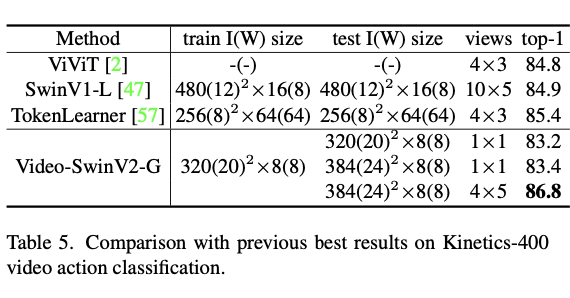
Conclusion
large scale vision model을 개발. 선행 되어진 3가지 문제점을 해결. image classification 영역에 국한되지 않고 OD나 Seg의 backbone 영역에서 좋은 성능 보임.
