목표
자바의 멀티쓰레드 프로그래밍에 대해 학습하세요.
학습할 것
- Thread 클래스와 Runnable 인터페이스
- 쓰레드의 상태
- 쓰레드의 우선순위
- Main 쓰레드
- 동기화
- 데드락
Thread 클래스와 Runnable 인터페이스
들어가기에 앞서 쓰레드란 무엇인지 알아봅시다.
많은 면접 질문에서 프로세스와 쓰레드의 차이를 물어보고, OS에서 굉장히 기초적인 면접 질문으로 손꼽힙니다.
우선 프로세스를 알아보자 어떤 프로그램을 실행하면 OS로부터 자원을 할당받아 OS의 제어를 받는 상태가 되는데 이런 실행중인 프로그램을 프로세스라고 한다.
쓰레드는 프로세스의 자원을 이용해 실제 작업을 수행하는 것을 말한다. 따라서 모든 프로세스에는 최소 하나 이상의 쓰레드가 존재하고, 둘 이상을 가진 프로세스를 멀티쓰레드 프로세스라고 말한다.
Java에서 쓰레드를 생성하는 방법은 2가지가 존재한다.
-
Thread 클래스를 상속받고
run() 오버라이딩
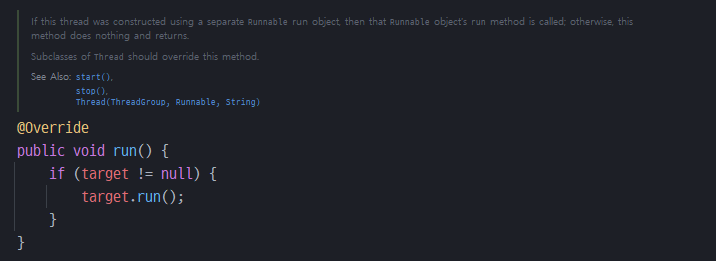
-
Runnable 인터페이스를 구현하고,
run() 오버라이딩
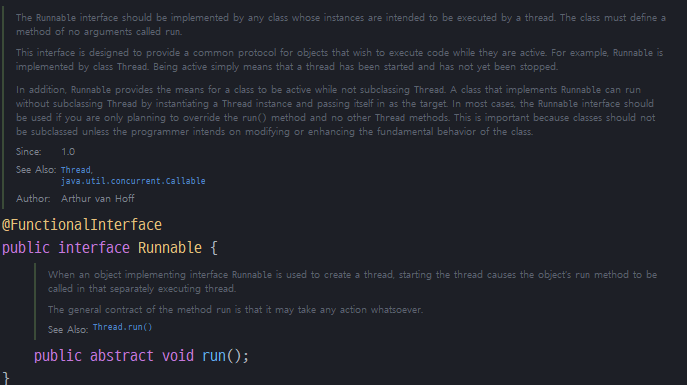
Runnable 인터페이스를 사용하는 방식이 재사용성이 높고 좀 더 객체지향적
결국 위의 방식을 이용해 상속 또는 구현을 하게되면 사용자는 run() 메소드를 오버라이딩 해야한다. run() 메소드는 프로그램을 실행했을때 쓰레드가 동작하는 작업 내용을 만들어주는 것이다.
두 가지 방법으로 Thread 구현
public class ThreadDemo extends Thread{
public void run() {
for (int i = 0; i < 5; i++) {
for(long l = 0; l < 2500000000L; l++);
System.out.println(1);
}
}
}
class ThreadDemo2 implements Runnable {
@Override
public void run() {
for (int i = 0; i < 5; i++) {
for(long l = 0; l < 2500000000L; l++);
System.out.println(2);
}
}
}
class ThreadMain {
public static void main(String[] args) {
Thread t1 = new ThreadDemo();
Runnable r = new ThreadDemo2();
Thread t2 = new Thread(r);
t1.start();
t2.start();
System.out.println("All thread is ended");
}
}
[실행결과]
All thread is ended
1
2
1
2
1
2
1
2
1
2 두 방식 모두 정상적으로 쓰레드를 생성한다.
또한 실행결과를 보면 쓰레드는 어떤 한 작업이 끝나고 다른 작업을 하는 것이 아니다.
서로 다른 쓰레드가 일정 시간동안의 자신의 작업을 처리하고, 다른 쓰레드가 다시 작업을 처리한다.
예를들어 2개의 쓰레드가 각자의 작업을 처리한다면, 짧은 시간동안 2개의 쓰레드가 번갈아가면서 자신의 작업을 수행해서 마치 동시에 두 작업이 처리되는 것과 같이 느끼게한다.
아래 그림을 보면 서로다른 쓰레드 2개가 자신의 작업을 처리하는 방식을 나타낸다. 이를 멀티쓰레드라 말한다.

반면에 하나의 쓰레드가 두 개의 작업을 처리하는 경우는 다음과 같다. 이를 싱글쓰레드라 말한다.
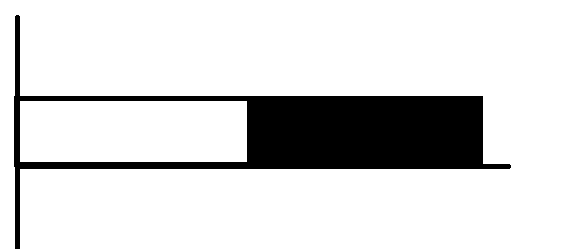
싱글쓰레드와 두 개의 쓰레드(멀티쓰레드)로 수행한 시간은 거의 동일하지만, 실제로는 두 개의 쓰레드로 작업하는 시간이 좀 더 길다. 그 이유는 Context Switching 비용으로 인해 나타난다.
Context Switching
쓰레드간의 작업 전환시 현재 진행중인 작업의 상태(Program Counter 등) 등의 정보를 저장하고 읽어 오는 시간이 소요된다. 여기서 들어가는 시간의 지연을 Context Switching이라 말한다.
위와 같이 1개와 2개를 비교하게 되면 1개의 쓰레드가 유리할 수 있지만, 수많은 작업들을 싱글쓰레드로 처리하는것과 멀티쓰레드를 이용하는것은 Context Switching 비용을 이겨낼만큼 효율성이 있기에 멀티쓰레드가 주로 사용된다.
또한 서로 다른 자원을 사용하는 작업의 경욷에도 싱글쓰레드보다 멀티쓰레드가 더 효율적이다.
start(), run()
Thread를 상속 받아 쓰레드를 생성하거나, Runnable을 구현하면 둘 다 run() 메소드를 재정의 한다.
main() 메서드에서 run()을 호출하게 되면 생성된 쓰레드의 실행이 아니라 run()이라는 단순 메서드를 실행시키게 되는것이다.
반면에 start()는 새로운 쓰레드가 작업 실행시 필요한 호출 스택을 생성하고 해당 스택 내부에 run()을 호출한다. 따라서 생성한 쓰레드의 개수마다 서로다른 호출 스택을 만들게 되어 쓰레드는 서로 독립적인 호출 스택에 run()이라는 메소드를 실행하게 된다.
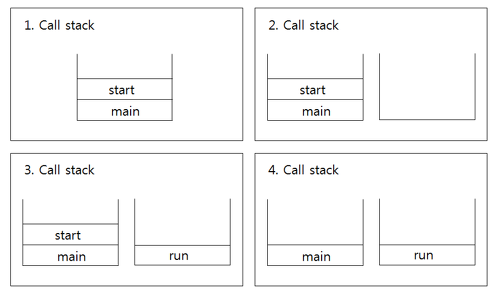
사진 출처: https://javafactory.tistory.com/1528
- main 메서드에서 쓰레드의 start()를 호출
- start()는 새로운 쓰레드를 생성하고, 쓰레드가 작업하는데 사용될 호출 스택을 생성
- 새로 생성된 호출스택에 run()이 호출됨, 쓰레드가 독립적인 공간에서 작업 수행
- 호출스택이 2개이므로 스케줄러가 정한 순서에 의해 번걸아 가면서 실행
Main 쓰레드
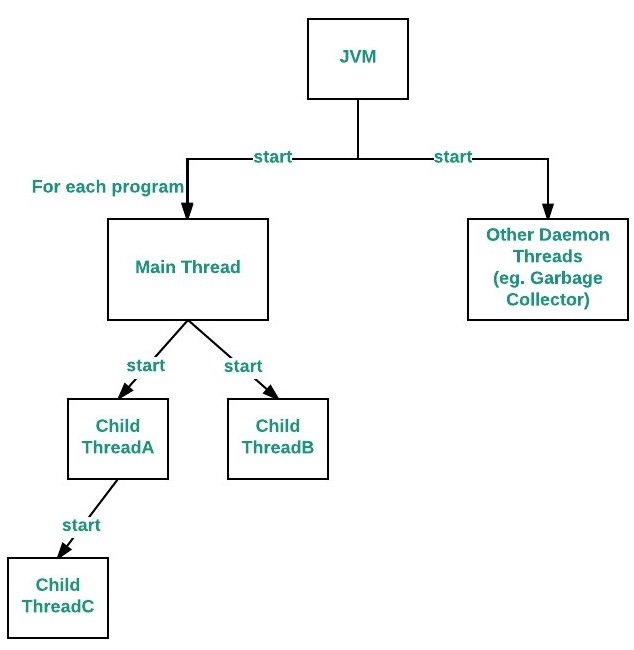
위의 호출스택에서 main() 메서드 또한 호출스택에서 실행됨을 알 수 있다. 즉, main() 메서드의 작업을 수행하는 것도 쓰레드 이며 이를 Main 쓰레드라고 말한다.
위의 그림을 보면 알 수 있듯 모든 쓰레드는 Main 쓰레드의 자식 쓰레드가 된다.
프로그램이 실행되기 위해서는 작업을 수행하는 최소 하나의 쓰레드가 필요하다. 따라서 기본적으로 프로그램을 실행하면 쓰레드를 생성하고 main메서드를 호출해 작업을 수행한다.
main 메서드의 수행을 마치면 프로그램이 종료되었으나 main() 메서드를 가지고있는 호출스택에서 main 메서드가 완료되어도 다른 호출스택에 아직 완료되지 않은 쓰레드(run() 메서드)가 존재한다면 프로그램이 종료되지 않는다. 즉, 프로그램은 실행중인 사용자 쓰레드가 하나도 없을 때 프로그램은 종료된다.
위와 같은 이유로 main 쓰레드가 종료되면 다른 쓰레드도 종료시킬 수 있는 방법이 존재하는데, 쓰레드를 Daemon Thread로 만들면 이와 같은 작업이 가능하다. 반대로 데몬 쓰레드가 아닌 쓰레드를 일반 쓰레드라고 한다.
Daemon Thread
데몬 쓰레드는 다른 일반 쓰레드의 작업을 돕는 보조적인 역할을 하는 쓰레드이다. 일반 쓰레드가 모두 종료되면 데몬 쓰레드는 강제적으로 자동 종료된다.
이 점을 제외하고 일반 쓰레드와 다르지 않음
데몬 쓰레드의 예로 Garbage Collector, 워드 프로세서 자동저장, 화면 자동 갱신 등이 존재한다.
데몬 쓰레드는 일반 쓰레드와 작성 및 실행 방법이 동일하며 다만 쓰레드를 생성하고 실행 전에 setDaemon(true)를 해주어야 하고, 이미 쓰레드가 실행된 이후(start()) 해당 쓰레드를 데몬 쓰레드로 등록할 수 없다.
또한 데몬 쓰레드가 생성한 쓰레드는 자동적으로 데몬 쓰레드가 된다.
boolean isDaemon(): 쓰레드가 데몬 쓰레드인지 확인
void setDaemon(boolean on): 쓰레드를 데몬 쓰레드로 또는 사용자 쓰레드로 변경한다.(true == 데몬쓰레드)DamonThread 예시
class DaemonThread extends Thread {
public void run() {
while (true) {
for (long l = 0; l < 2500000000L; l++);
System.out.println("Run Daemon Thread!!");
}
}
static class DaemonThreadRun {
static long currentTime;
public static void main(String[] args) {
Thread th1 = new DaemonThread();
th1.setDaemon(true);
currentTime = System.currentTimeMillis(); // 현재 시간
th1.start();
try {
Thread.sleep(5 * 1000); // 5 초간 대기
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("실행 종료 시간 : " + (System.currentTimeMillis() - currentTime));
}
}
}위의 코드는 Main 쓰레드 및 데몬 쓰레드(th1) 2개의 쓰레드를 이용한 예제이다.
DaemonThread 클래스의 run() 메소드는 일정의 시간 지연을 두고 "Run Daemon Thread!!!" 라는 메시지를 무한으로 출력하게 된다.
하지만, th1.setDaemon(true)로 두었으므로 Main 쓰레드가 5초의 지연(Thread.sleep()) 이후 종료되면 데몬 쓰레드도 같이 종료됨을 알 수 있다.
쓰레드 그룹
쓰레드 그룹은 서로 관련된 쓰레드를 그룹으로 다루기 위한 것으로, 폴더를 생성하고 파일들을 폴더단위로 관리하는 것처럼 쓰레드 그룹(폴더)을 생성해 그룹 단위로 관리할 수 있다.
더하여 폴더 안에 폴더처럼 쓰레드 그룹안에 또다른 하위 그룹을 생성해 조금 더 세밀하게 다룰수도 있다.
모든 쓰레드는 반드시 쓰레드 그룹에 포함되어 있어야 하며, 쓰레드 그룹을 따로 지정하지 않은 쓰레드는 기본적으로 자신을 생성한 쓰레드와 같은 쓰레드 그룹에 속하게 된다.
JVM은 프로그램이 시작하면 main, system이라는 쓰레드 그룹을 만든다.
class TestThreadGroup extends Thread {
@Override
public void run() {
for (long i = 0; i < 2500000000L; i++) {
}
}
}
public class ThreadGroupDemo {
public static void main(String[] args) {
TestThreadGroup th1 = new TestThreadGroup();
th1.setName("TestThreadGroup");
th1.setDaemon(true);
th1.start();
Map<Thread, StackTraceElement[]> map = Thread.getAllStackTraces();
Set<Thread> threads = map.keySet();
for (Thread thread : threads) {
System.out.println("Name : " + thread.getName() + (thread.isDaemon() ? "[Daemon]" : "[Main]"));
System.out.println("\t" + "Group : " + thread.getThreadGroup().getName());
System.out.println();
}
}
}
결과
Name : Finalizer[Daemon]
Group : system
Name : main[Main]
Group : main
Name : Reference Handler[Daemon]
Group : system
Name : Common-Cleaner[Daemon]
Group : InnocuousThreadGroup
Name : Signal Dispatcher[Daemon]
Group : system
Name : Monitor Ctrl-Break[Daemon]
Group : main
Name : TestThreadGroup[Daemon]
Group : main
Name : Attach Listener[Daemon]
Group : system결과를 확인해보면 알겠지만, system 쓰레드 그룹은 JVM 운영에 필요한 쓰레드를 생성해 해당 그룹에 포함시키고, main 쓰레드는 우리가 생성하는 모든 쓰레드의 상위 그룹이다. 따라서 그룹을 지정하지 않고 생성하는 쓰레드는 모두 main 쓰레드 그룹에 속하게 된다.
쓰레드의 상태
쓰레드의 상태는 Thread 클래스에 enum 타입으로 정의되어 있고 다음과 같은 종류가 존재한다.
- NEW: 아직 시작되지 않은 쓰레드의 상태, 쓰레드가 생성되고 start()가 호출되기 전
- RUNNALBE: 실행 중, 혹은 실행 가능한 상태
- BLOCKED: 동기화 블럭에 의해 일시정지된 상태(lock이 풀릴 때까지 기다리는 상태)
- WAITING: 쓰레드의 작업이 종료되지는 않았지만, 실행가능하지 않은 일시정지 상태
- TIMED_WATING: WAITING과 동일하지만, 일시정지 시간이 지정된 경우를 의미한다.
- TERMINATED: 쓰레드의 작업이 종료된 상태
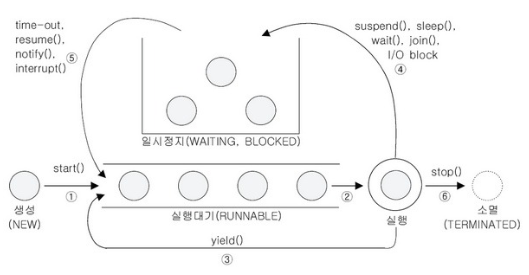
- 쓰레드를 생성하고 start()를 호출하면 바로 실행되는 것이 아니라 실행대기열에 저장되어 자신의 차례가 될 때까지 기다림, Queue의 구조
- 실행대기 상태에 있다가 자신의 차례가 되면 실행상태가 됨
- 주어진 실행시간 다 되거나,
yield()호출시 다시 실행대기상태가 된다. suspend(),sleep(),wait(),join(),I/O block(입출력작업에서 발생)에 의해 일시정지상태가 될 수 있음- 지정된 일시정지시간이 다되거나(time-out),
notify(),resume(),interrupt()가 호출되면 일시정지상태를 벗어나 다시 실행대기열에 저장됨 - 실행을 모두 마치거나
stop()이 호출되면 쓰레드는 소멸됨
쓰레드의 우선순위
쓰레드는 우선순위라는 속성(멤버변수)를 가지고 있다.
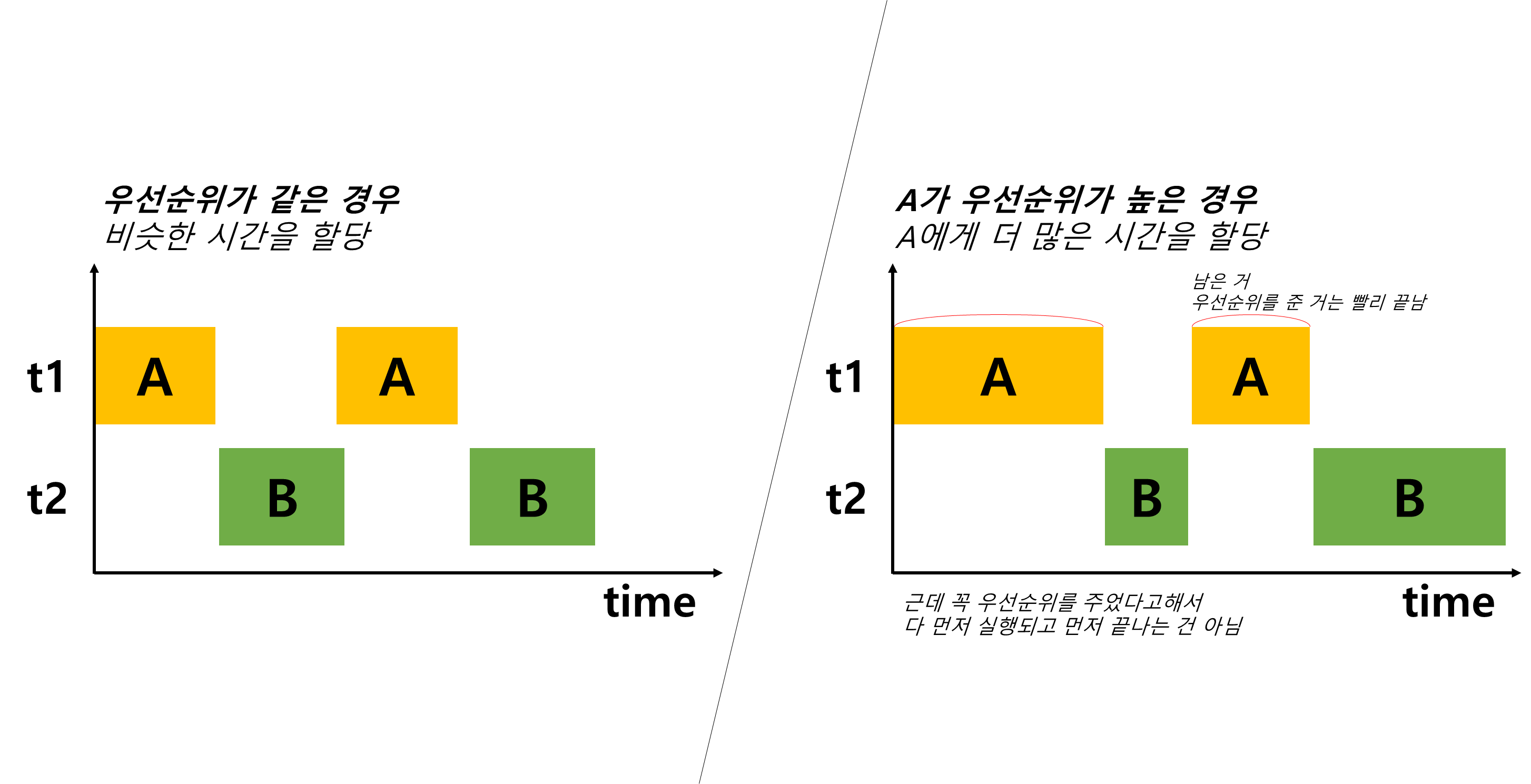
이 우선순위의 값에 따라 쓰레드가 얻는 실행시간이 달라진다. 쓰레드가 수행하는 작업의 중요도에 따라 쓰레드의 우선순위를 서로 다르게 지정하여 특정 쓰레드의 작업시간을 늘릴 수 있다.
쓰레드가 가질 수 있는 우선순위는 1 ~ 10이며 숫자가 높을수록 높은 우선순위를 가진다. 또한 쓰레드의 우선순위는 쓰레드를 생성한 쓰레드로부터 상속받는다. main 메서드를 수행하는 쓰레드의 경우 default 우선순위가 5이므로 main 메서드 내에서 생성하는 쓰레드의 우선순위는 자동적으로 5가된다.
쓰레드의 우선순위 지정하기
void setPriority(int newPriority) // 쓰레드의 우선순위를 지정한 값으로 변경한다.
int getPriority() // 쓰레드의 우선순위를 반환한다.다음 예시를 살펴보면 두 쓰레드의 우선순위를 다르게 하면 우선순위가 높은 쓰레드의 실행시간이 좀 더 늘어나는것을 알 수 있다.
class ThreadEx8_1 extends Thread {
public void run() {
for (int i = 0; i < 300; i++) {
System.out.print("-");
for (int j = 0; j < 10000000; j++) {
}
}
}
}
class ThreadEx8_2 extends Thread {
public void run() {
for (int i = 0; i < 300; i++) {
System.out.print("|");
for (int j = 0; j < 10000000; j++) {
}
}
}
}
public class ThreadEx8 {
public static void main(String[] args) {
ThreadEx8_1 th1 = new ThreadEx8_1();
ThreadEx8_2 th2 = new ThreadEx8_2();
th2.setPriority(7);
System.out.println("Priority of th1(-) : " + th1.getPriority());
System.out.println("Priority of th2(|) : " + th2.getPriority());
th1.start();
th2.start();
}
}
[결과]
Priority of th1(-) : 5
Priority of th2(|) : 7
-||-|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|||||||||||||||||||||||||||||||||||||||||||||----------------------------------
-------------------------------------------------------------------------------
-------------------------------------------------------------------------------
----------------------------------||||||||||||||||||||||||||||||---------------
---------------------------------------------------------
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||쓰레드의 우선순위가 차이가 난다면 다음과 같이 실행시간의 비중이 적용된다.
동기화
멀티쓰레드 프로세스의 경우 여러 쓰레드가 같은 프로세스 내의 자원을 공유해서 작업하기 때문에 서로의 작업에 영향을 준다.
예를 들어 초기값이 0인 공유자원에 1씩 더하는 과정에서 A쓰레드와 B쓰레드가 각각 작업을 한번씩
마치게 되면 공유자원의 값은 2가 돼야 하지만
만약 A쓰레드는 0일때의 값을 가져와서 덧셈을 하고, B쓰레드 또한 0일때 값을 가져와 더하게 된다면 결과값은 1이 된다.위와 같은 상황을 방지하기 위해 공유 데이터를 사용하는 코드 영역을 임계 영역으로 정하고, 해당 영역은 단 하나의 쓰레드만 lock을 획득할 수 있도록 하여 한 쓰레드가 진행 중인 작업을 다른 쓰레드가 간섭하지 못하도록 막는것을 쓰레드의 동기화라고 한다.
synchronized를 이용한 동기화
synchronized 키워드를 이용해 특정 영역을 임계 영역으로 설정할 수 있는데 두 가지 이용방법이 존재한다.
- 메서드 전체를 임계 영역으로 지정
public synchronized void calcSum() { // 공유자원 이용 코드 } - 특정한 영역을 임계 영역으로 지정
synchronized (객체의 참조 변수) { // 공유자원 이용 코드 }
synchronized를 이용하는것과 이용하지 않는 것의 차이를 알아보자
public class ThreadEx21 {
public static void main(String[] args) {
Calculator calculator = new Calculator();
Thread thread1 = new ThreadEx21_1(calculator);
Thread thread2 = new ThreadEx21_1(calculator);
thread1.start();
thread2.start();
try {
thread1.join();
thread2.join();
} catch (InterruptedException e) {
e.printStackTrace();
}
// 예상대로라면 20000이 출력되어야 한다.
System.out.println(calculator.getCount());
}
}
class Calculator {
private int count;
public synchronized void calcSum() {
count += 1;
}
public int getCount() {
return count;
}
}
class ThreadEx21_1 extends Thread {
private Calculator calculator;
public ThreadEx21_1(Calculator calculator) {
this.calculator = calculator;
}
@Override
public void run() {
for (int i = 0; i < 10000; i++) {
calculator.calcSum();
}
}
}
[synchronized 이용하기 이전의 결과]
17015
[synchronized 이용하고 난 뒤의 결과]
20000Calculator 클래스의 getSum()을 호출할때마다 해당 count 필드에 1씩 더하는 로직이다.
run() 메서드 내에서는 단순히 getSum()을 10000번 반복하여 작업하고 해당 작업을 하는 쓰레드는 2개가 있다.
우리가 예상한 값을 20000이지만 실제로는 20000보다 훨씬 못미치는 값을 가지게 된다. 이것이 공유자원을 두 개의 쓰레드가 무분별하게 사용하게 되면 발생하는 상황이다.
따라서 공유자원인 count를 연산하는 getSum()메서드에 synchronized키워드를 붙이게 되면 우리가 예상한 결과값인 20000이 출력됨을 알 수 있다.
위 예제는 메서드 레벨에서 동기화를 시켰지만 synchronized 블럭을 다음과 같이 이용해도 같은 결과를 얻을 수 있다.
public synchronized void calcSum() {
synchronized (this) {
count += 1;
}
}wait(), notify()
특정 쓰레드를 동기화 시켜 공유 데이터를 보호하는 것은 좋지만, 특정 쓰레드가 객체의 락을 가진 상태를 오래 유지하게 되면 다른 쓰레드들은 해당 락이 풀리기만을 기다리느라 작업이 원할하게 돌아가지 못한다.
이런 점을 개선할 수 있는 방법은 wait()과 notify()다.
- wait() : 실행중이던 쓰레드는 해당 객체의 대기실(waiting pool)에서 통지를 기다림
- notify() : 해당 객체의 대기실에 있던 모든 쓰레드 중에서 임의의 쓰레드만 통지를 받는다.
public class ThreadWaitEx3 {
public static void main(String[] args) throws InterruptedException {
Table table = new Table();
new Thread(new Cook(table), "COOK1").start();
new Thread(new Customer(table, "donut"), "CUST1").start();
new Thread(new Customer(table, "burger"), "CUST2").start();
Thread.sleep(2000);
System.exit(0);
}
}
class Customer implements Runnable {
private Table table;
private String food;
Customer(Table table, String food) {
this.table = table;
this.food = food;
}
@Override
public void run() {
while (true) {
try {
Thread.sleep(100);
} catch (InterruptedException e) {
}
String name = Thread.currentThread().getName();
table.remove(food);
System.out.println(name + " ate a " + food);
}
}
}
class Cook implements Runnable {
private Table table;
public Cook(Table table) {
this.table = table;
}
@Override
public void run() {
while (true) {
// 임의의 요리를 하나 선택해서 table에 추가
int idx = (int) (Math.random() * table.dishNum());
table.add(table.dishNames[idx]);
try {
Thread.sleep(10);
} catch (InterruptedException e) {
}
}
}
}
class Table {
String[] dishNames = {"donut", "donut", "burger"};
final int MAX_FOOD = 6;
private ArrayList<String> dishes = new ArrayList<>();
public synchronized void add(String dish) {
if (dishes.size() >= MAX_FOOD) {
String name = Thread.currentThread().getName();
System.out.println(name + " is waiting.");
try {
wait();
Thread.sleep(500);
} catch (InterruptedException e) {
}
}
dishes.add(dish);
notify();
System.out.println("Dished:" + dishes.toString());
}
public void remove(String dishName) {
synchronized (this) {
String name = Thread.currentThread().getName();
while (dishes.size() == 0) {
System.out.println(name + " is waiting.");
try {
wait();
Thread.sleep(500);
} catch (InterruptedException e) {
}
}
while (true) {
for (int i = 0; i < dishes.size(); i++) {
if (dishName.equals(dishes.get(i))) {
dishes.remove(i);
notify();
return;
}
}
try {
System.out.println(name + " is waiting.");
wait();
Thread.sleep(500);
} catch (InterruptedException e) {
}
}
}
}
public int dishNum() {
return dishNames.length;
}
}
[실행결과]
Dished:[burger]
Dished:[burger, donut]
Dished:[burger, donut, donut]
Dished:[burger, donut, donut, burger]
Dished:[burger, donut, donut, burger, burger]
Dished:[burger, donut, donut, burger, burger, donut]
COOK1 is waiting.
CUST1 ate a donut
CUST2 ate a burger
Dished:[donut, burger, burger, donut, donut]
CUST1 ate a donut
CUST2 ate a burger
Dished:[burger, donut, donut, donut]
Dished:[burger, donut, donut, donut, donut]
Dished:[burger, donut, donut, donut, donut, donut]
COOK1 is waiting.
CUST2 ate a burger
CUST1 ate a donut
Dished:[donut, donut, donut, donut, donut]
CUST1 ate a donut
CUST2 is waiting.
Dished:[donut, donut, donut, donut, donut]
CUST2 is waiting.
Dished:[donut, donut, donut, donut, donut]
CUST1 ate a donut
위의 코드는 하나의 공유자원 Table을 가지고 Cook 클래스는 음식을 추가하고(최대 6개) Customer 클래스는 음식을 소비한다.
여기서 Table.add()로 인해 음식이 6개를 꽉 채워서 만들게 되면 wait()을 호출해 COOK1 쓰레드를 waiting pool에서 기다리게 하고, notify()를 호출해 기다리고 있던 CUST 쓰레드를 깨운다.
반대로 음식을 전부 소비하게 되면 CUST 쓰레드는 wait()을 호출해 waiting pool에서 기다리게 되고 기다리고 있던 COOK1을 깨우기 위해 notify()를 호출한다.
이렇게 wait()과 notify()를 이용해면 좀 더 효율적인 동기화 관리를 할 수 있다.
문제점: 기아 현상과 경쟁 상태
위의 예시에서 하나 문제점이 존재한다. Table 객체의 waiting pool에 요리사 쓰레드와 손님 쓰레드가 같이 기다리는 상황이 발생한다는 점이다. notify()는 임의의 쓰레드에게 통지하기 때문에 두 쓰레드 중 누가 통지를 받을지 모른다.
정말 운이없다면 요리사 쓰레드는 계속 통지 받지 못하는 상황이 발생할 수 있다. 이런 현상을 기아 현상이라고 한다.
이런 기아 현상이 발생되는것의 단순한 해결책은 notifyAll()을 이용해 모든 waiting pool에 존재하는 쓰레드에게 통지를 보낸다. 하지만 요리사 쓰레드만 락을 시도하는 것이 아닌 다른 손님 쓰레드와 lock을 경쟁하게 된다. 이런 상태를 경쟁 상태라고 한다.
우리가 필요한 것은 요리사 쓰레드와 손님 쓰레드를 구별하여 통지하는 것이 필요하다.
Java1.5에서 추가된 Lock 혹은 Condition을 이용한다.
Lock과 Condition을 이용한 동기화
synchronized 블럭 외에도 java.util.concurrent.locks 패키지가 제공하는 Lock 클래스들을 사용하여 동기화를 사용할 수 있음
ReentrantLock: 재진입이 가능한 lock, 가장 일반적인 배타 lock- 가장 일반적인 lock, 특정 조건에서 lock을 풀고 나중에 다시 lock을 얻고 임계영역으로 들어와 이후의 작업을 수행할 수 있다.
void lock(): lock을 잠근다.void unlock(): lock을 해지한다.boolean isLocked(): lock이 잠겼는지 확인한다.
ReentantReadWriteLock: 읽기에는 공유적이고, 쓰기에는 배타적인 lock- 배타적인 lock이므로 무조건 lock이 걸려있어야 임계 영역의 코드를 수행할 수 있다. 또한 읽기 lock이 걸려있다면 여러 쓰레드가 읽기 lock을 중복해서 걸고 읽기를 수행할 수 있다. 하지만, 읽기 lock과 쓰기 lock을 동시에 걸 수 없다.
StampedLock: ReentrantReadWriteLock에 낙관적인 lock의 기능을 추가- lock을 걸거나 해지할때 스탬프(long 타입의 정수값)를 사용하며, 익기와 쓰기를 위한 lock외에
낙관적 읽기 lock이 추가됐다. 이는 읽기 lock이 걸려있으면, 쓰기 lock을 얻기 위해서 lock이 풀리길 기다리지 않고 쓰기 lock에 의해 바로 풀린다.
- lock을 걸거나 해지할때 스탬프(long 타입의 정수값)를 사용하며, 익기와 쓰기를 위한 lock외에
// StampedLock을 이용한 낙관적 읽기의 예
int getBalance() {
long stamp = lock.tryOptimisticRead(); // 낙관적 읽기 lock을 건다.
int curBalance = this.balance; // 공유 데이터인 balance를 읽어온다.
if (!lock.validate(stamp)) { // 쓰기 lock에 의해 낙관적 읽기 lock이 풀렸는지 확인
stamp = lock.readLock(); // lock이 풀렸으면, 읽기 lock을 얻으려고 기다린다.
try {
curBalance = this.balance; // 공유 데이터를 다시 읽어온다.
} finally {
lock.unlockRead(stamp); // 읽기 lock을 푼다.
}
}
return curBalance // 낙관적 읽기 lock이 풀리지 않았으면 곧바로 읽어온 값을 반환
}ReentrantLock와 Condition
또한 Condition을 이용하면 쓰레드의 종류를 구분하지 않고, 공유 객체의 waiting pool에 같이 몰아넣는 wait(), notify() 대신, 손님과 요리사 쓰레드를 위한 Condition을 각각 만들어서 각각의 waiting pool에서 따로 기다리도록 하여 문제를 해결할 수 있다.
Condition은 이미 생성된 lock으로부터 newCondition()을 호출해서 생성한다.
private ReentrantLock lock = new ReentrantLock(); // lock을 생성
// lock으로 condition을 생성
private Condition forCook = lock.newCondition();
private Condition forCust = lock.newCondition();두 개의 Condition은 각각 요리사와 손님 쓰레드를 위한 것이다. 이후 wait(), notify()가 아닌 await(), signal()을 사용하면 된다.
기존의 Table 클래스의 add() 메소드를 Condition을 이용한 코드로 변경해보자
// 기존 코드
public synchronized void add(String dish) {
if (dishes.size() >= MAX_FOOD) {
String name = Thread.currentThread().getName();
System.out.println(name + " is waiting.");
try {
wait();
Thread.sleep(500);
} catch (InterruptedException e) {
}
}
dishes.add(dish);
notify();
System.out.println("Dished:" + dishes.toString());
}
// 변경 후
public void add(String dish) {
lock.lock();
try {
while (dishes.size() >= MAX_FOOD) {
String name = Thread.currentThread().getName();
System.out.println(name + " is waiting.");
try {
forCook.await(); // COOK 쓰레드를 기다리게 함
} catch(InterruptedException e) {}
}
dishes.add(dish);
forCust.signal(); // 기다리고 있는 CUST를 꺠우기 위함.
System.out.println("Dishes:" + dishes.toString());
} finally {
lock.unlock();
}
}기존의 wait() -> await()으로 notify() -> signal()을 이용함으로써 대기와 통지의 대상이 명확히 구분된다.
데드락
Deadlock(교착 상태)는 두 개 이상의 쓰레드가 서로가 쥐고 있는 자원을 할당받기 원할때 발생하게 된다. 따라서 영원히 차단되어 서로를 기다린다.
다음 예를 살펴보자
public class Deadlock {
static class Friend {
private final String name;
public Friend(String name) {
this.name = name;
}
public String getName() {
return this.name;
}
public synchronized void bow(Friend bower) {
System.out.format("%s: %s"
+ " has bowed to me!%n",
this.name, bower.getName());
bower.bowBack(this);
}
public synchronized void bowBack(Friend bower) {
System.out.format("%s: %s"
+ " has bowed back to me!%n",
this.name, bower.getName());
}
}
public static void main(String[] args) {
final Friend alphonse = new Friend("Alphonse");
final Friend gaston = new Friend("Gaston");
new Thread(new Runnable() {
public void run() {
alphonse.bow(gaston);
}
}).start();
new Thread(new Runnable() {
public void run() {
gaston.bow(alphonse);
}
}).start();
}
}[실행결과]
Alphonse: Gaston has bowed to me!
Gaston: Alphonse has bowed to me!위의 코드를 살펴보면 Alphonse와 Gaston은 서로 상대에게 인사를 해준다. (bow()) 이후 매개인자로 넘겨준 인사를 한 객체를 향해 다시 인사를 해줘야 한다.(bowBack()) 하지만 Alphonse와 Gaston 객체는 스스로를 동기화로 쥐고 있는 상황에서 상대방의 자원을 달라고 요구하는 꼴이 된다. 이를 Deadlock(교착 상태)라고 한다.
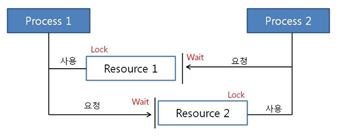
다음과 같은 그림도 데드락이 어떤 상황인지 알 수 있다.
데드락의 발생조건
교착 상태는 한 시스템내에서 4가지의 조건을 동시에 만족할 때 발생하게 된다.
상호 배제(Mutual exclusion)- 자원은 한 번에 하나의 프로세스만 해당 자원을 사용할 수 있어야 한다.
점유 대기(Hold and wait)- 자원을 최소한 하나 정도는 보유하고, 다른 프로세스에 할당된 자원을 얻으려고 기다리는 프로세스가 있어야 한다.
비선점(No preemption)- 자원은 선점할 수 없다. 즉 자원은 강제로 빼앗을 수 없고, 자원을 점유하고 있는 프로세스가 끝나야 해제된다.
순환(환형) 대기(Circular wait)- 프로세스의 집합 {P0, P1, ... Pn}에서 P0은 P1이 점유한 자원을 대기하고, P1은 P2와 같이 순차적으로 이전 자원이 다음 자원을 요구하고, Pn은 다시 P0을 요구해야 한다.
References
- 자바의 정석
- 그림으로 배우는 구조와 원리 운영체제
- Oracle Docs
- https://wisdom-and-record.tistory.com/48
- https://sujl95.tistory.com/63
