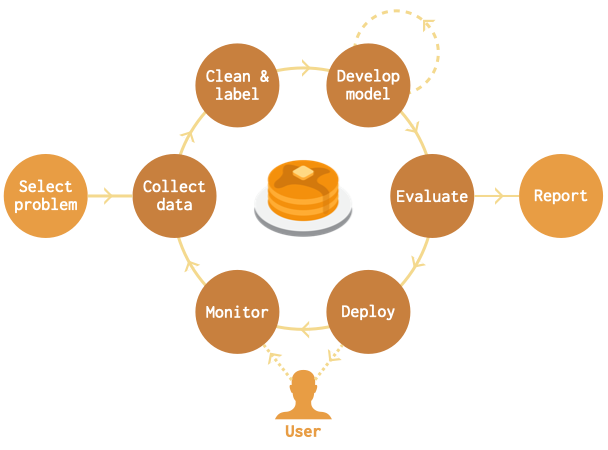
이 글은 Full Stack Deep Learning 강의 자료의 번역본임을 알립니다.
서론
ML 분야에서는 정말로 많은 시간을 데이터를 처리하는 데 보내야 하고, 이 부분은 많은 ML 입문자들이 놓치는 부분입니다. 이는 데이터셋을 구성하고, 데이터를 찾아 모으고, 데이터를 처리하는 일련의 과정을 말합니다.
이 강의의 요점은 다음과 같습니다:
- 여러분이 데이터를 찾고 모으는 데 사용하길 원하는 시간보다 10배 정도의 시간을 더 할애해야 합니다.
- 일반적으로 성능을 향상시키는 가장 좋은 방법은 데이터를 수정, 추가 및 보강(augmenting)하는 것입니다.
- 이 모든 과정을 단순하게 진행할 수 있습니다!
데이터 소스 Data Sources
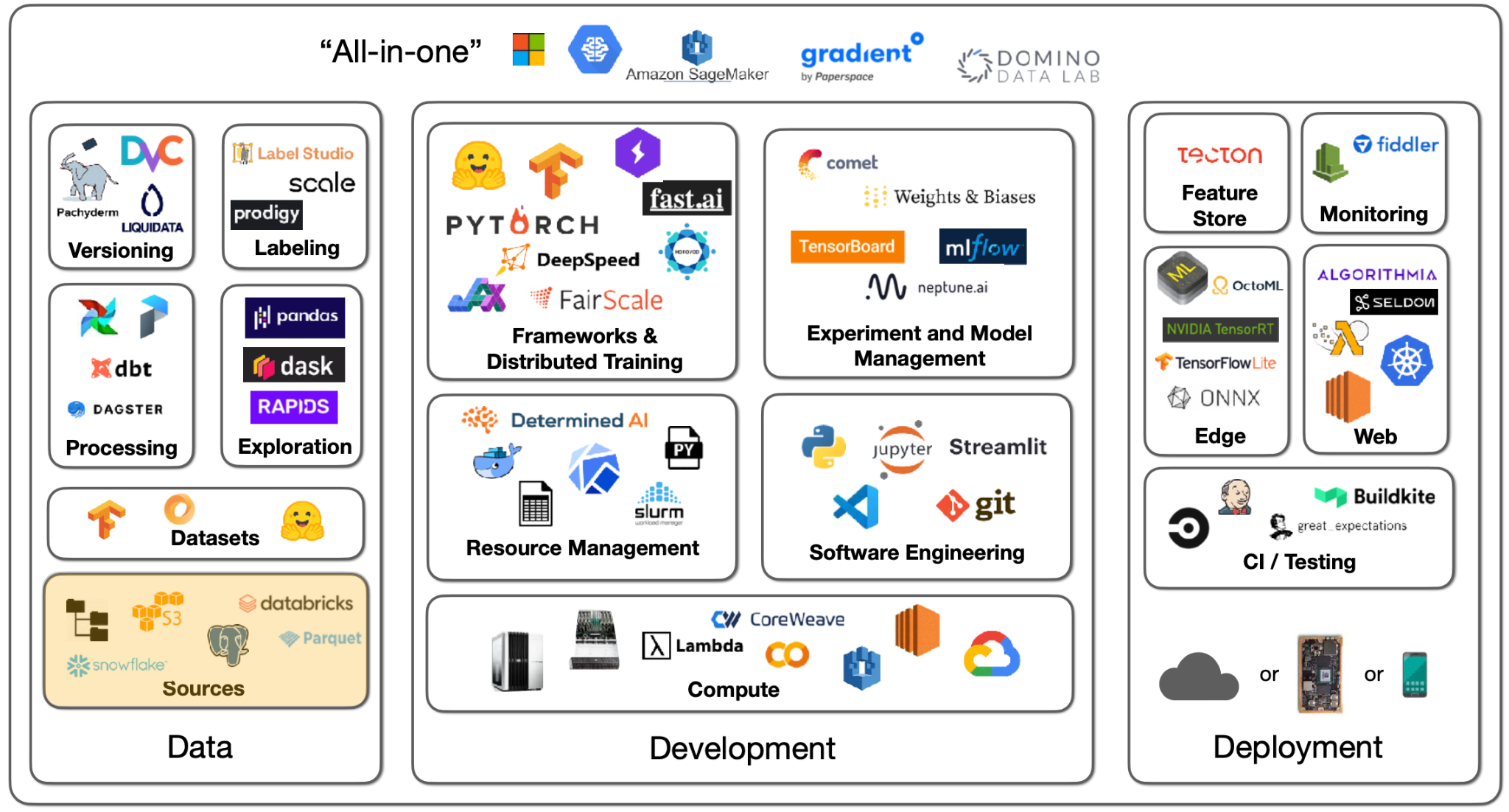
데이터 소스에는 여러 종류가 있을 수 있습니다. 이미지, 텍스트 파일, 로그 또는 데이터베이스 레코드 등의 유형이 있는데요. 딥 러닝에서는 해당 데이터를 GPU 옆의 로컬 파일 시스템 디스크로 가져와야 합니다. Souece에서 훈련 프로세스로 데이터를 보내는 방법은 프로젝트마다 다릅니다.
- 이미지: S3에서 간단히 다운로드할 수 있습니다.
- 텍스트 파일: 분산된 방식으로 파일을 처리하고 데이터를 분석한 다음 하위 집합(subset)을 선택하여 로컬 시스템에 저장해야 합니다.
- 로그 및 데이터베이스 레코드: 데이터 레이크를 사용하여 데이터를 수합하고 처리할 수 있습니다.

기본적으로 살펴보면 모두 파일 시스템, 객체 스토리지, 데이터베이스로 나눌 수 있습니다.
파일 시스템
파일 시스템은 가장 기본적인 추상화입니다. 기본적인 단위는 파일입니다. 파일은 텍스트 또는 이진 파일일 수 있습니다. 파일은 버전이 없으며 쉽게 덮어쓸 수 있습니다. 파일 시스템은 일반적으로 시스템에 연결된 디스크에 있습니다. 이때 디스크는 물리적으로 시스템에 연결되어 있거나(온프레미스) 클라우드에 연결되어 있거나 분산되어 있습니다.
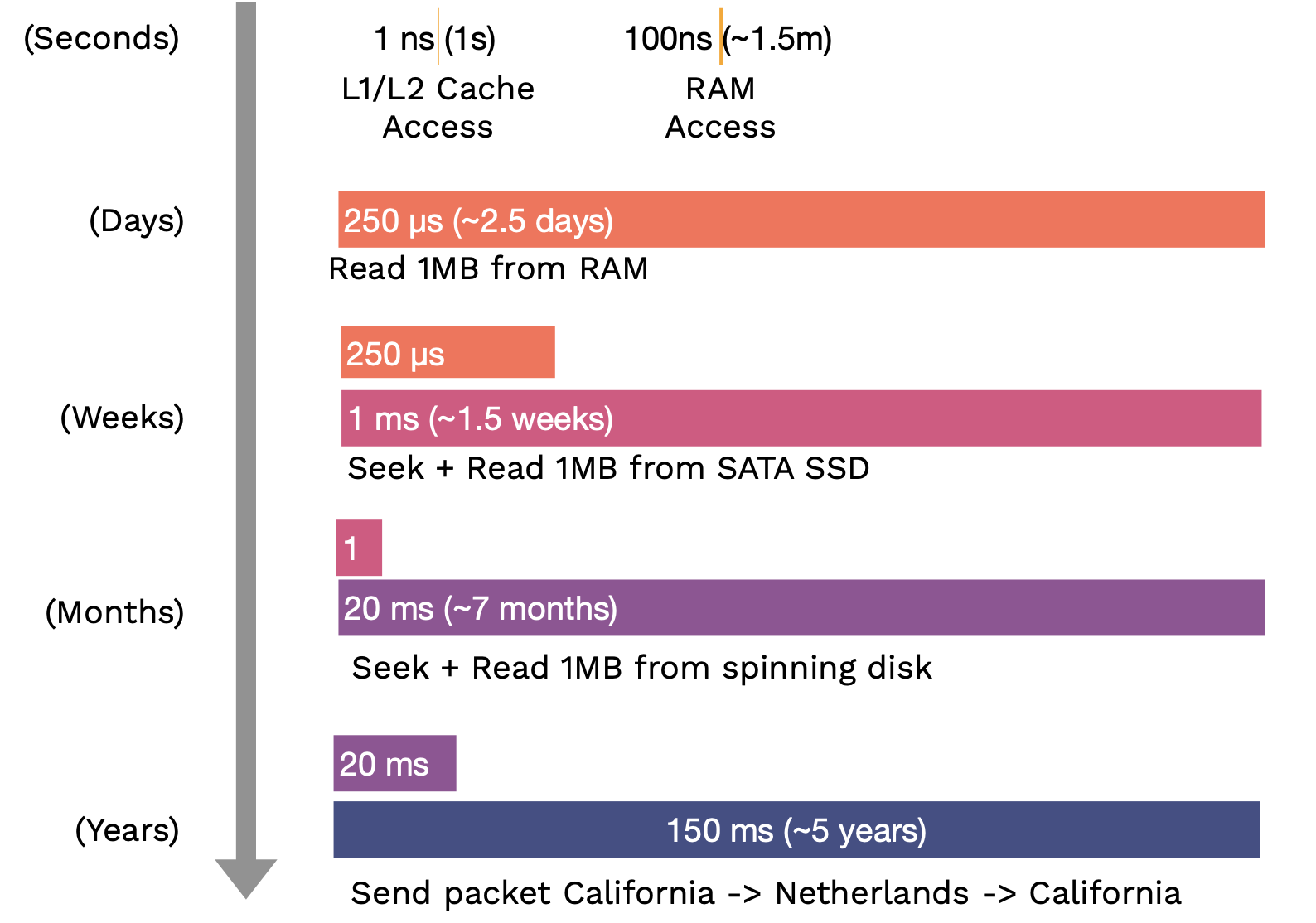
디스크의 속도와 대역폭은 하드 디스크에서 솔리드 스테이트 디스크(SSD)에 이르기까지 다양하다는 것을 아는 것이 무척 중요합니다. 가장 느린(SATA SSD) 디스크와 가장 빠른(NVMe SSD) 디스크 사이에는 100배 이상의 속도 차이가 있습니다.
다음 표는 각 연산 혹은 처리가 얼마나 걸리는지를 비교한 것입니다. 괄호 안은 사람이 체감하기 쉽게 스케일을 늘린 것입니다.
로컬 디스크에 데이터를 저장할 때 어떤 포맷으로 저장해야 할까요?
이미지 및 오디오와 같은 이진 데이터로 작업하는 경우에는 JPEG 또는 MP3와 같은 표준 형식을 사용하면 됩니다.
메타데이터(예: 레이블), 표 형식 데이터 또는 텍스트 데이터로 작업하는 경우 압축된 JSON 또는 텍스트 파일만 있으면 됩니다. 또는 Parquet이라는 빠르고, 작고, 널리 사용되는 테이블 포맷도 사용할 수 있습니다.
Object Storage
Object Storage는 파일 시스템을 통해 설계된 API입니다. 기본 단위는 일반적으로 이진 형식(이미지, 사운드 파일, 텍스트 파일 등)의 Object입니다. 우리는 객체 스토리지 서비스에서 버전을 만들거나 redundancy 를 구축할 수 있습니다. 로컬 파일 시스템만큼 빠르지는 않지만 클라우드 내에서는 충분히 빠릅니다.
데이터베이스
데이터베이스는 구조화된 데이터 시스템의 영구적이고 빠르고 확장 가능한 저장소 및 검색 시스템입니다. 데이터베이스를 대하는 유용한 관점은 다음과 같습니다.
- 데이터베이스가 보유한 모든 데이터는 실제로 컴퓨터의 RAM에 있습니다.
- 데이터베이스 소프트웨어는 컴퓨터의 전원이 꺼질 경우 모든 데이터가 디스크에 안전하게 유지되도록 보장합니다.
- RAM에 너무 많은 데이터가 있는 경우 뛰어난 성능으로 디스크로 스케일아웃됩니다.
이진 데이터를 데이터베이스에 직접 저장해서는 안 되고 Object Storage에 저장한 뒤 그 URL에 저장해야 합니다. 대부분의 경우 Postgres는 올바른 선택입니다. 구조화되지 않은 JSON과 그러한 JSON에 대한 쿼리를 지원하는 오픈 소스 데이터베이스입니다. SQLite는 소규모 프로젝트에도 완벽하게 적합합니다.
대부분의 코딩 프로젝트는 여러 객체를 서로 참조하는 데이터를 사용하고, 결국에는 이리 저리 꼬여서 엉터리 데이터베이스를 구현하게 되기 쉽습니다. 프로젝트 처음부터 데이터베이스를 사용하는 것이 시간을 절약할 수 있는 길입니다. 실제로 대부분의 MLOps의 본질은 데이터베이스입니다. (예: W&B는 실험 데이터베이스, HuggingFace Hub는 모델 데이터베이스, Label Studio는 레이블 데이터베이스)
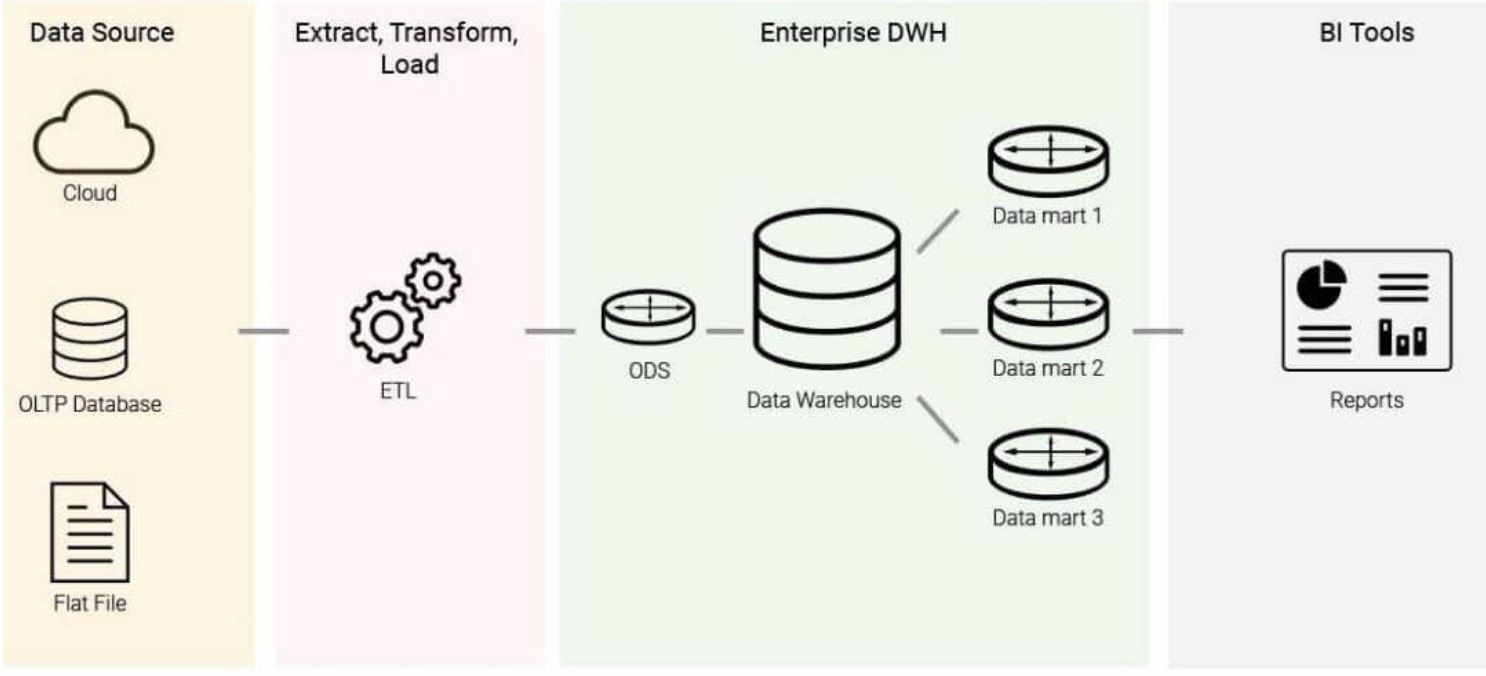
데이터 웨어하우스는 OLTP(Online Transaction Processing)를 위한 데이터 저장소가 아닌 OLAP(Online Analytical Processing)를 위한 저장소입니다. ETL(Extract-Transform-Load) 이라는 프로세스를 통해 데이터를 데이터 웨어하우스로 가져옵니다: 여러 데이터 소스가 지정된 경우 데이터를 추출하여 균일한 스키마로 변환한 다음 데이터 웨어하우스에 로드합니다. 웨어하우스에서 비즈니스 인텔리전스 쿼리를 실행할 수 있습니다. OLAP와 OLTP의 차이점은 다음과 같습니다. OLAP는 열(column) 관점으로 쿼리를 짜는 반면 OLTP는 행(row) 관점입니다.
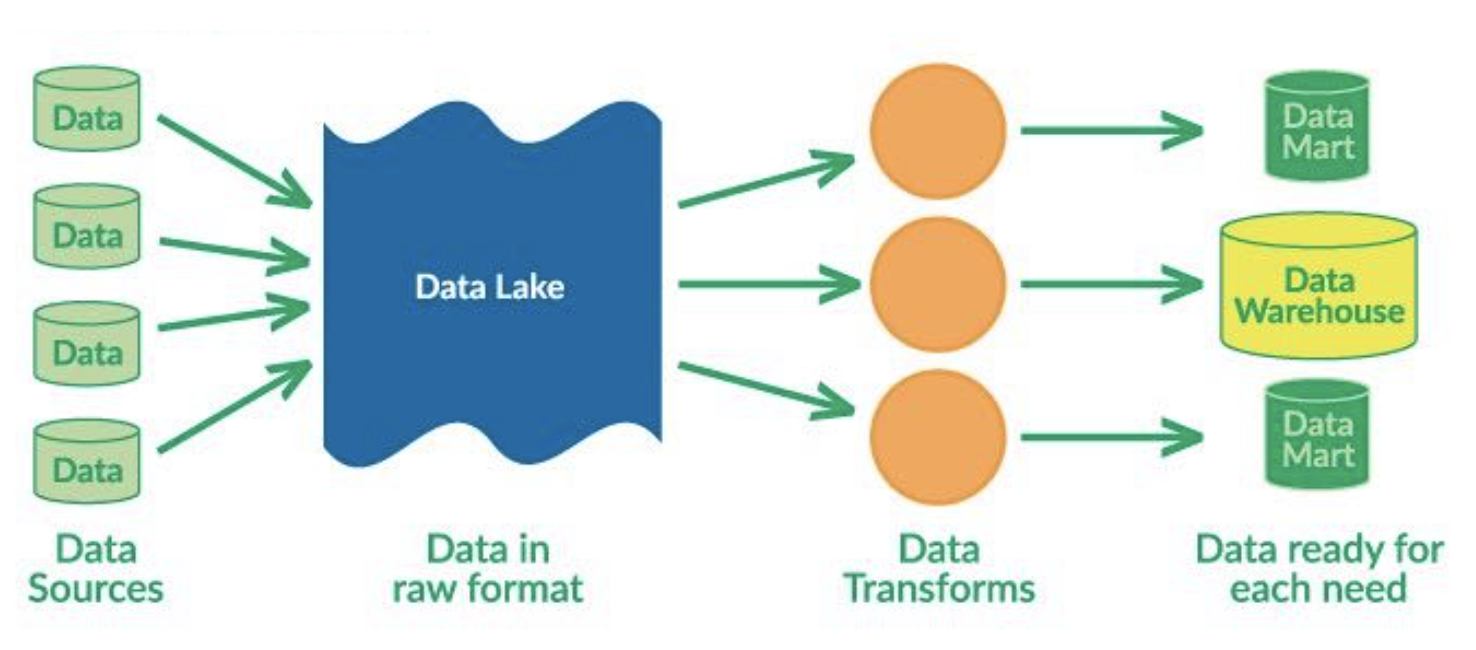
데이터 레이크는 여러 소스로부터 구조화되지 않은 데이터가 집합되어 있는 것입니다. 데이터 웨어하우스와 데이터 웨어하우스의 주요 차이점은 데이터 레이크가 ELT(Extract-Load-Transform) 프로세스를 사용한다는 점입니다. 즉, 모든 데이터를 덤프하고 나중에 특정 요구 사항에 맞게 데이터를 변환합니다.
데이터 레이크와 데이터 웨어하우스를 통합하여 정형 데이터와 비정형 데이터를 함께 사용할 수 있도록 하는 것이 큰 추세입니다. 이를 위한 두 개의 큰 플랫폼은 Snowflake와 Databricks입니다. 이에 관심이 있다면, "데이터 중심 애플리케이션 설계"는 가장 기초적인 원칙부터 잘 설명할 수 있는 훌륭한 책입니다.
데이터 탐색 Data Exploration
데이터를 탐색하려면 그에 맞는 언어를 사용해야 합니다. 대부분은 SQL을 사용하고 DataFrame이 지분이 점점 늘어나고 있습니다. SQL은 수십 년 동안 존재해온 구조화된 데이터의 표준 인터페이스입니다. Pandas는 SQL과 같은 작업을 수행할 수 있도록 하는 Python 생태계의 주요 DataFrame입니다. 트랜잭션 데이터베이스와 분석적인 데이터 웨어하우스와 데이터 레이크, 양쪽 모두와 상호 작용할 수 있도록 두 가지 모두를 유창하게 사용할 줄 아는 것이 좋습니다.
Pandas는 파이썬 기반 데이터 과학을 할 때 빈번하게 사용하는 일꾼과도 같습니다. DASK DataFrame을 사용하여 CPU 코어 차원에서 Panda 작업을 병렬화하고 RAPID를 사용하여 GPU에서 Panda 작업을 수행할 수 있습니다.
데이터 처리 Data Processing
데이터 처리 과정은 동기 부여가 되는 사례가 있는 것이 유용합니다. 우리가 매일 밤 사진의 인기도를 예측하는 모델을 훈련시켜야 한다고 가정해 보겠습니다. 각 사진에 대해 훈련 데이터는 다음을 포함해야 합니다:
- 데이터베이스에 있는 메타데이터 (예: 게시 시간, 제목 및 위치)
- 로그에서 추출하는 사용자의 특징들 (예: 오늘 로그인한 횟수)
- classifier를 작동시키는 데 필요한 사진 classifier 결과물 (예: 사진 내용 및 스타일)
우리의 최종 작업은 사진 예측 모델을 훈련시키는 것이지만 그러기 위해서는 데이터베이스에서 데이터를 얻어내고 로그를 처리하고 분류 모델을 돌려서 예측을 출력해야 합니다. 결과적으로 작업에 종속성이 있습니다. 일부 태스크는 다른 태스크가 완료될 때까지 시작할 수 없으므로 태스크를 완료되면 그 태스크에 종속된 태스크가 시작됩니다.
파일이 아니라 프로그램과 데이터베이스에 종속성이 있는 것이 이상적입니다. 이를 통해 우리는 이 작업을 많은 기계에 분산시키고 많은 종속성 그래프를 한 번에 실행할 수 있어야 합니다.
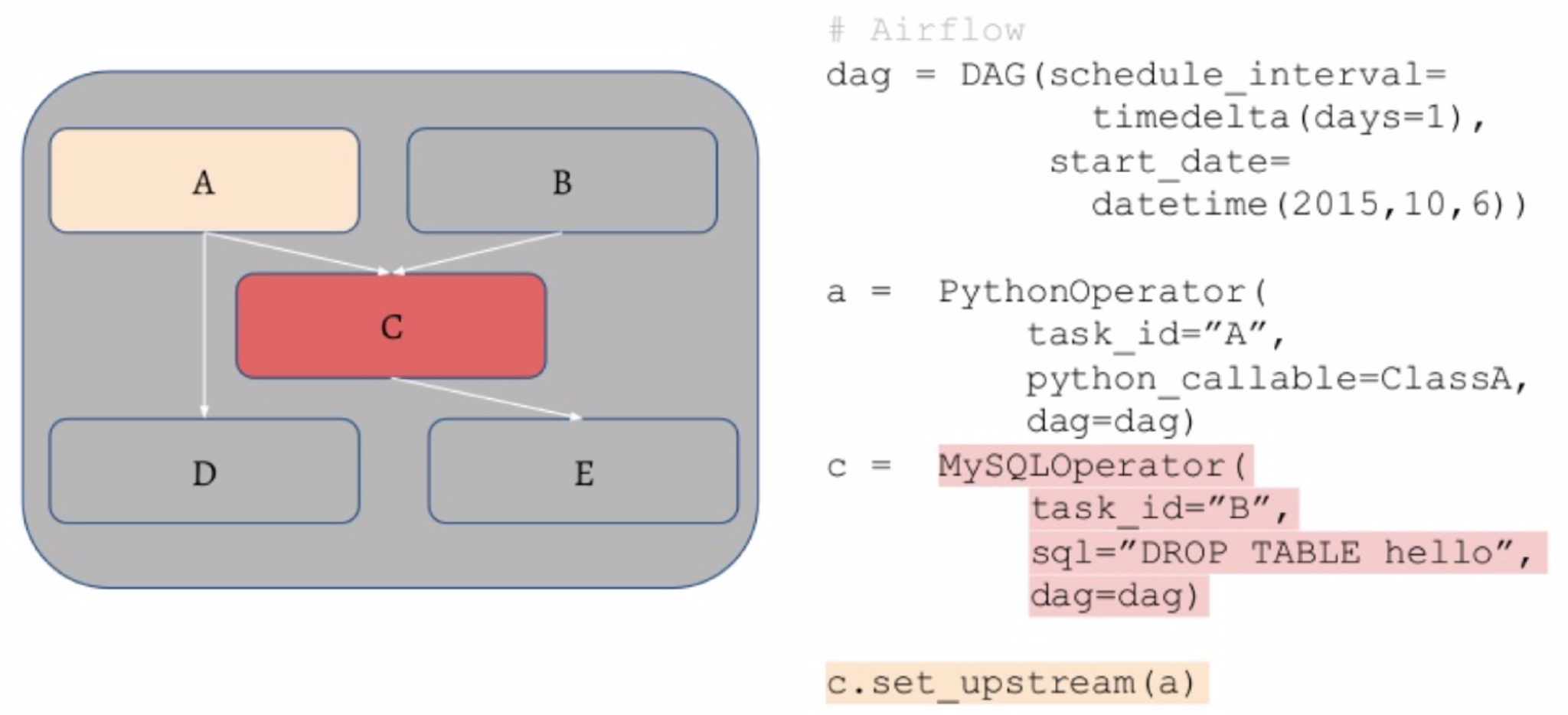
- Airflow는 Python 코드를 사용하여 태스크의 DAG(방향 비순환 그래프)를 지정할 수 있는 Python의 표준 스케줄러입니다. SQL 연산 또는 Python 함수를 이 그래프의 연산자로 사용할 수 있습니다.
- 이러한 작업을 분산 처리하기 위해서 워크플로 매니저는 태스크를 위한 태스크 큐(queue)를 가지고 있으며 큐에서 끌어오는 worker를 관리합니다. 작업이 실패하면 작업을 재시작하고 작업이 완료되면 사용자에게 ping을 보냅니다.
- Prefect와 Dagster는 장기적으로 공기 흐름을 개선하고 대체할 경쟁자입니다.
여기서 가장 중요한 조언은 이러한 작업들을 과도하게 설계하지 말라는 것입니다. 요즘 시대는 CPU 코어와 RAM이 많은 기계를 얼마든지 구할 수 있는 시대입니다. 예를 들어, UNIX에는 강력한 병렬 처리, 스트리밍 및 고도로 최적화된 도구가 이미 내장되어 있습니다.
피쳐 저장소 Feature Store

데이터 처리를 통해 훈련에 필요한 아티팩트가 생성된다고 가정해 보겠습니다. 훈련을 받은 모델이 프로덕션 환경에서 동일한 처리가 수행되는지 확인하려면 어떻게 해야 합니까? 다시 훈련을 진행하는 중에 불필요한 재연산을 피하는 방법은 무엇일까요?
피쳐 저장소는 이에 대한 솔루션입니다. (이 과정 전체는 사실 필요하지 않을 수도 있습니다.)
- 피처 저장소에 대한 첫 번째 언급은 ML 플랫폼인 미켈란젤로를 설명하는 Uber 블로그 게시물에서 나왔습니다. 오프라인 훈련 프로세스와 온라인 예측 프로세스가 있어 두 프로세스가 동기화될 수 있도록 내부에 피쳐 저장소를 구축했습니다.
- Tecton은 피쳐 저장소 분야의 선도적인 SaaS 솔루션입니다.
- Feast는 일반적인 오픈 소스 옵션입니다.
- Featureform은 비교적 새로운 옵션입니다.
데이터셋 Datasets
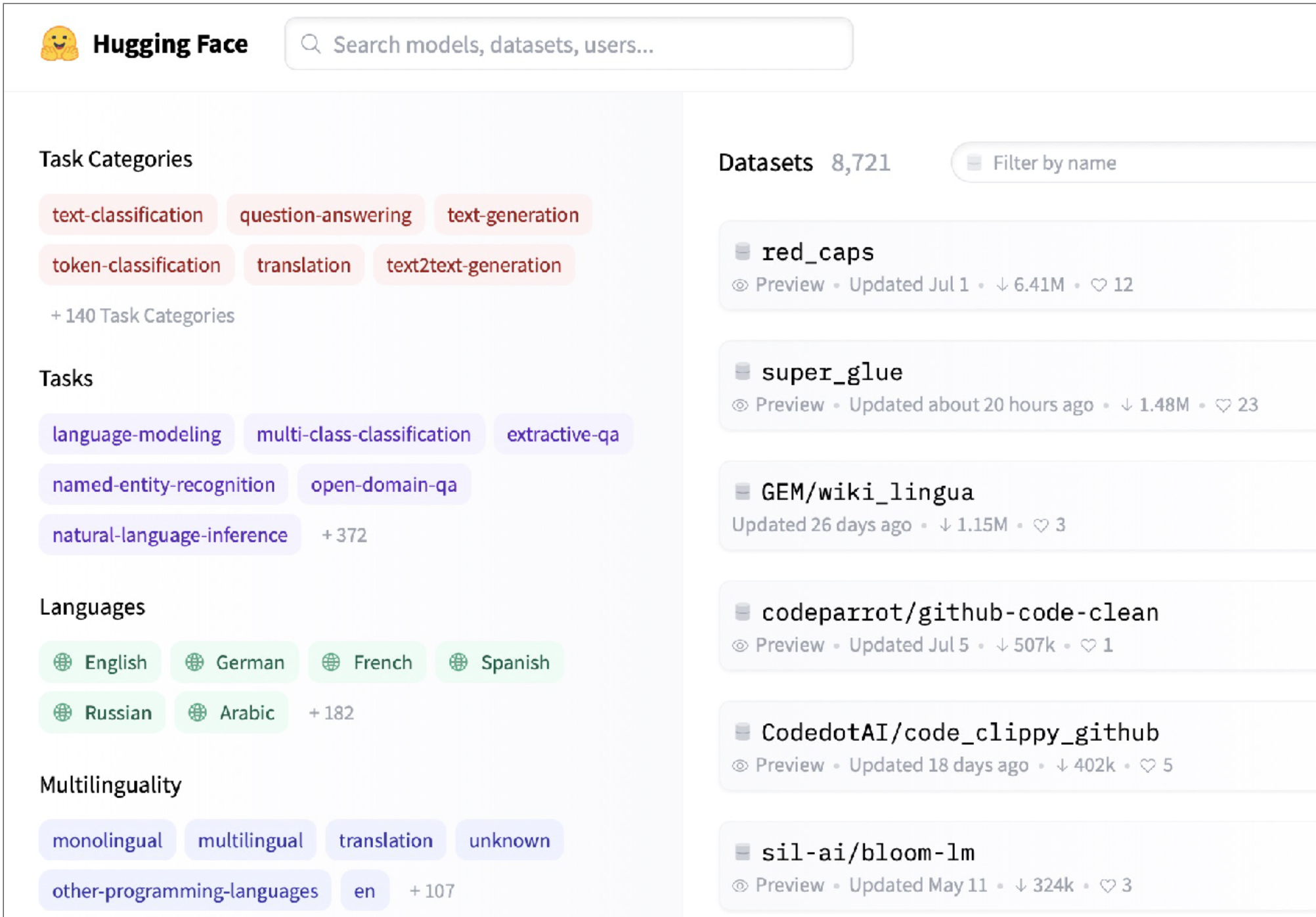
Hugging Face Datasets는 기계 학습을 위해 준비된 훌륭한 데이터셋 소스입니다. 컴퓨터 비전, NLP 등과 같은 매우 다양한 작업을 다루는 8,000개 이상의 데이터 세트가 있습니다. HuggingFace의 Github-Code 데이터 세트는 이러한 데이터 세트가 ML 애플리케이션에 어떻게 적합한지 보여주는 좋은 예입니다. Github-Code는 스트리밍할 수 있고 최신 Apache Parquet 형식이며 이를 사용하기 위해 1TB 이상의 데이터를 직접 다운로드할 필요가 없습니다. 또 다른 샘플 데이터 세트는 RedCaps이며, Reddit의 1,200만 개의 이미지-텍스트 쌍으로 구성됩니다.
기계 학습을 위한 또 다른 흥미로운 데이터셋 솔루션은 Activeloop입니다. 이 툴은 데이터를 다운로드하지 않고도 데이터를 사용하고 샘플을 탐색할 수 있도록 하는 기능이 특히 잘 갖추어져 있습니다.
데이터 라벨링 Data Labeling
라벨링이 필요없는 경우
데이터 라벨링을 이야기할 때 제일 먼저 강조해야 하는 것은... 바로 때로는 데이터 라벨링을 할 필요가 없을 수도 있다는 것입니다! 이 경우에는 여러 가지 옵션이 있습니다.
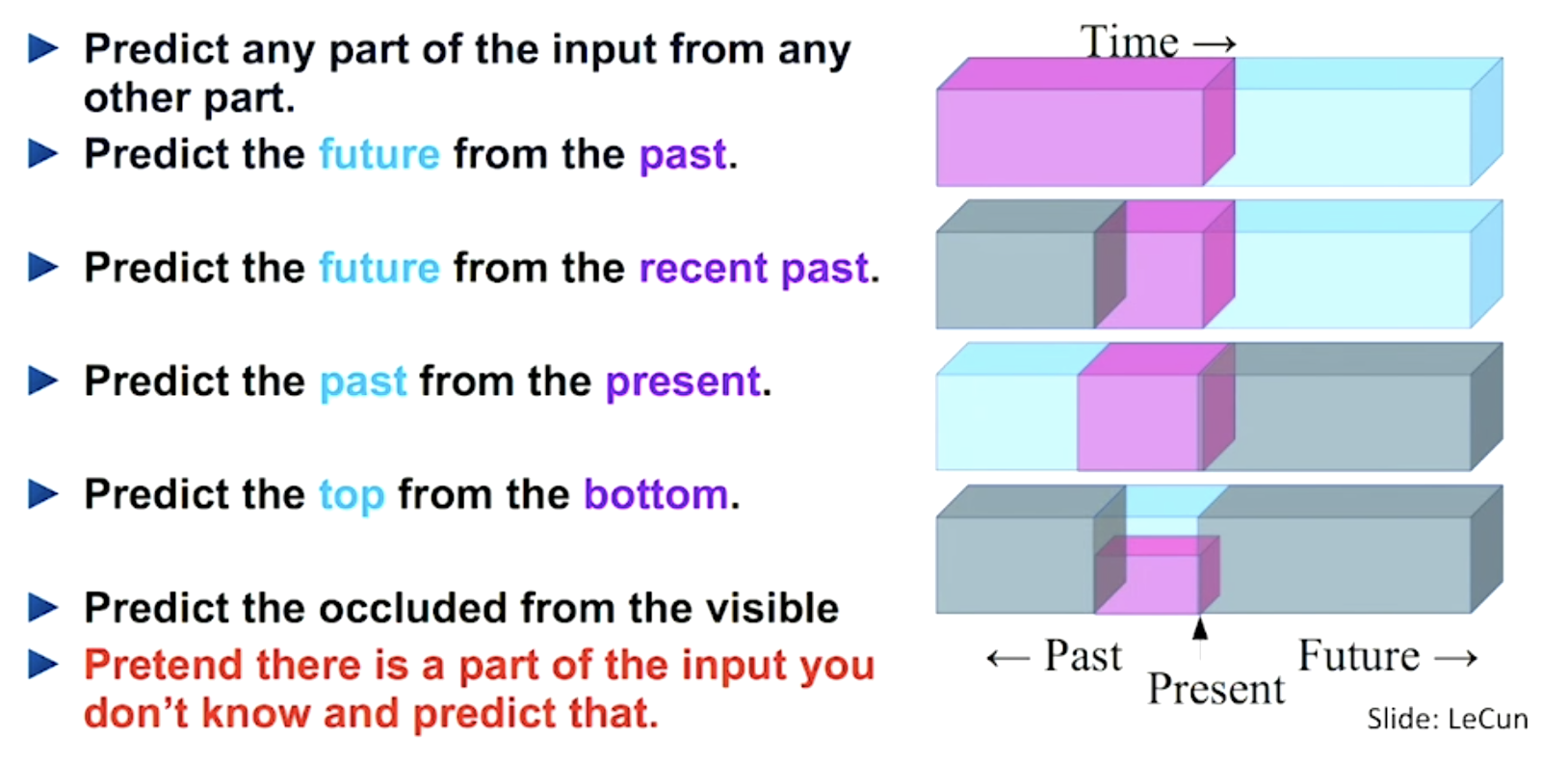
자기 지도 학습(Self-supervised learning) 은 모든 데이터에 힘들게 레이블을 지정하는 것을 피할 수 있는 매우 중요한 아이디어입니다. 데이터의 일부를 사용하여 데이터의 다른 부분에 레이블을 지정할 수 있습니다. 이것은 현재 NLP에서 매우 흔한 방법론입니다. 이에 대해서는 이후 기초 모델 강의에서 더 자세히 다루겠습니다. 요점은 데이터의 일부분을 마스킹해서 모델에 제공한다는 것입니다.(예: 문장의 끝을 생략하는 방식). 모델은 데이터의 앞 부분을 사용하여 마스킹된 문장의 뒷 부분을 예측할 수 있습니다 (예: 문장의 시작부터 배우고 끝을 예측할 수 있음). 이것은 OpenAI CLIP이 시연한 것처럼, 데이터의 형식을 걸쳐 사용할 수도 있습니다. 예를 들어 이미지와 텍스트를 각각 임베팅해서 서로를 예측하게 할 수 있습니다.
이미지 데이터 증강(augmentation)은 특히 비전 태스크에서는 거의 강제적으로 채택해야 하는 기술입니다. torchvision과 같은 프레임워크가 이런 작업을 도와줍니다. 데이터 증가를 통해 샘플의 실제 핵심 "의미"는 변경되지 않고 수정됩니다. (예를 들어 밝기가 변합니다.) 흥미롭게도, 증강 기술은 실제로 라벨링을 대체할 수 있습니다. 동일한 이미지에서 생성된 증강 이미지 간의 일치(agreement)를 극대화하고 다른 이미지 간의 일치를 최소화하는 것이 학습 목표인 SimCLR은 이를 입증하는 모델입니다.
다른 형태의 데이터의 경우, 몇 가지 증강 기술에 대한 트릭을 추가로 더 적용할 수 있습니다. 표 데이터의 일부 셀을 삭제하여 missing data를 시뮬레이션할 수 있습니다. 텍스트에는 아직 확립된 기술은 없지만 단어의 순서를 변경하거나 단어를 삭제하는 방법이 제안되고 있습니다. 음성 데이터에서는 음성의 속도를 변경하거나, 묵음을 중간에 삽입하는 과정 등을 수행할 수 있습니다.
합성 데이터는 현재 과소평가된 아이디어입니다. 레이블에 대한 사전 지식을 기반으로 새로운 데이터를 합성할 수 있습니다. 예를 들어, 이미지에서 영수증을 인식하는 방법을 배워야 할 경우 여러분은 영수증을 만들 수 있습니다. 이것은 매우 정교하고 내용이 깊어질 수 있으므로 조심스럽게 밟으십시오.
또한 창의력을 발휘하여 유저에게 데이터 라벨링을 요청할 수 있습니다. 앱의 모든 사용자가 알고 있듯이 Google 포토는 정기적으로 사용자에게 사진 속의 사람들이 동일한 사람인지 물어서 직접 이미지를 라벨링하게 만듭니다.
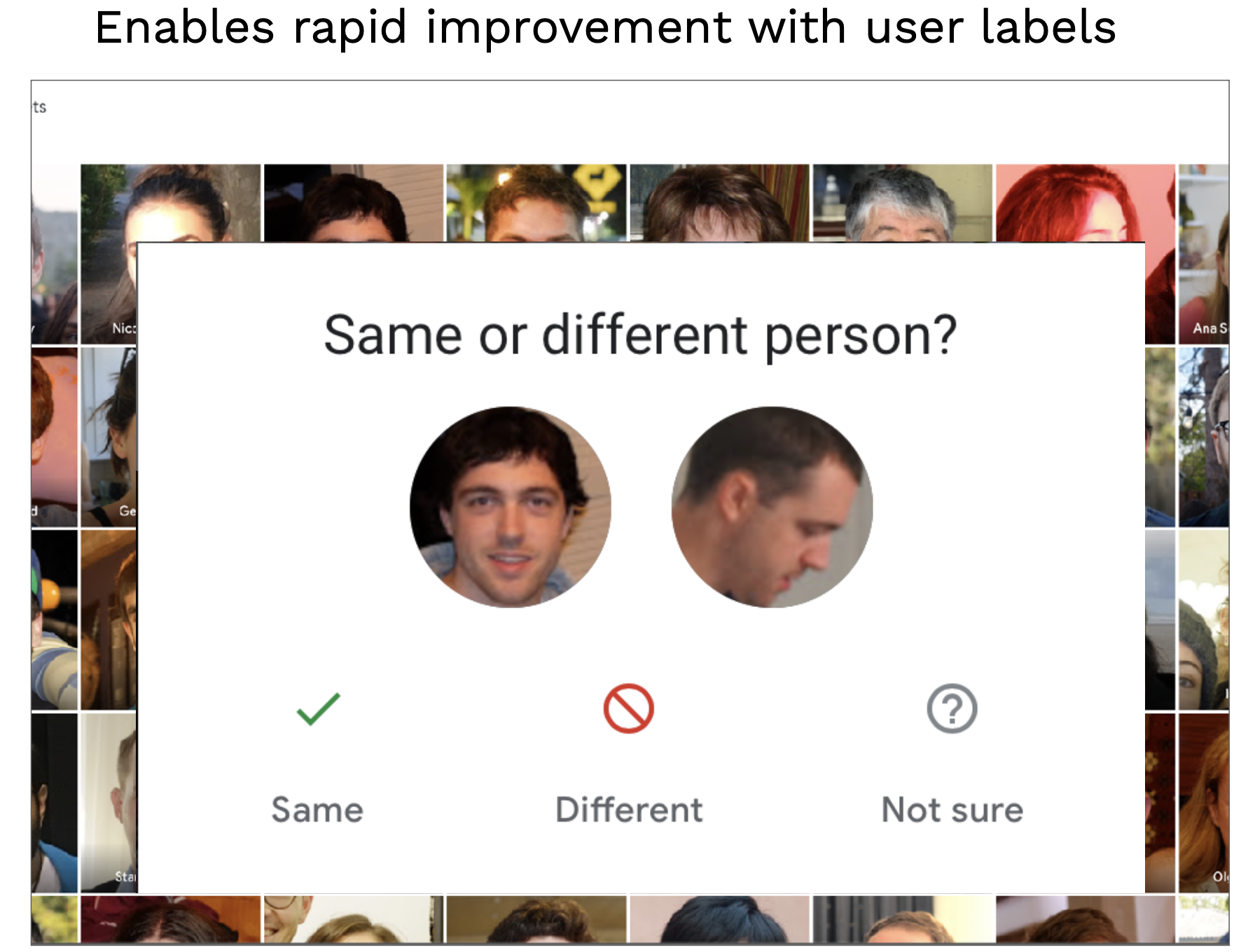
이것이 바로 데이터 플라이휠의 예입니다. 데이터를 개선하면 사용자가 모델을 개선할 수 있으며, 이를 통해 제품 경험이 개선됩니다.
라벨링 솔루션
이러한 옵션은 모두 데이터 라벨링을 방지하기 위한 훌륭한 옵션입니다. 그러나 프로젝트를 시작하려면 일반적으로 일부 데이터에 대해서는 반드시 라벨링을 해야 합니다.
라벨링에는 'bounding box'처럼 정보를 올바르게 확보하는 데 도움이 되는 표준적인 주석(annotation) 기능이 있습니다. annotation을 하는 사람을 제대로 교육하는 것이 annotation 몇 개보다 훨씬 더 중요합니다. 복잡하고 주관적인 라벨링 작업을 라벨러가 어떻게 수행하는 지에 대한 가이드를 표준화하는 것은 매우 중요합니다. 품질 보증(QA) 또한 주석 및 라벨링이 올바르게 수행되고 있는지 확인하는 데 중요합니다.
주석에 대한 작업을 소싱할 수 있는 몇 가지 옵션이 있습니다:
- Full-service 데이터 레이블링 공급업체는 엔드 투 엔드 레이블링 솔루션을 제공합니다.
- 주석자를 직접 고용하고 교육할 수 있습니다.
- Mechanical Turk와 같은 플랫폼에서 라벨링을 크라우드소싱할 수 있습니다.
Full-service 기업은 소프트웨어 구축, 인력 관리 및 품질 검사에 대해서 신경을 안 쓸 수 있게 하는 훌륭한 솔루션을 제공합니다. 이런 업체를 사용하는 것은 합리적입니다. 그러나 여러 가지 업체를 꼼꼼히 검토하는 데 시간을 할애해야 합니다. 또한 몇 가지 좋은 퀄리티의 표준 데이터에 직접 레이블을 지정하여 여러분 스스로 데이터를 이해하고 라벨링 업체를 평가하십시오. 여러 업체와 통화하고, 데이터에 대한 작업 샘플을 요청하고, 여러분의 레이블링과 비교하는 것이 좋습니다.
- Scale AI는 시장을 선점중인 데이터 레이블링 솔루션입니다. 작업을 스핀업할 수 있는 API를 제공합니다.
- 다른 솔루션으로는 Labelbox와 Supervisely가 있습니다.
- LabelStudio는 annotate를 직접 수행할 수 있는 오픈 소스 솔루션입니다. 엔터프라이즈 버전도 포함되어 있습니다. 맞춤화된 인터페이스를 설계하고 Activa Learning을 위한 플러그인 모델까지 설계할 수 있는 훌륭한 기능을 갖추고 있습니다!
- Diffgram은 Label Studio의 경쟁사입니다.
- Aquarium과 Scale Nucleus와 같은 최근 제품은 모델에게 가장 문제가 되는 일부 데이터셋에 레이블링 리소스를 집중하는 데에 도움을 줍니다.
- Snorkel은 유사한 개념인 'weak supervision'을 사용하는 데이터 세트 관리 및 레이블링 플랫폼입니다. 구성 가능한 규칙을 만들어 모든 데이터를 동일하게 취급하는 경우보다 더 빠르게 데이터를 라벨링할 수 있습니다. 예를 들어 "놀라운"이라는 용어가 있는 모든 문장이 긍정적인 정서라고 라벨링하게 할 수 있습니다.
결론적으로, 자기 지도 학습과 같은 기술을 사용하여 라벨링하는 것을 피하려고 노력하세요. 그럴 수 없는 경우 레이블링 소프트웨어를 사용하거나 라벨링 작업을 올바른 업체에 아웃소싱하세요. 만약 여러분이 공급업체를 살 여유가 없다면, 일을 크라우드소싱하는 것보다 단기 아르바이트를 고용하는 것을 고려해보세요. 라벨링 퀄리티를 보장받는 방법입니다.
데이터 버전 관리 Data Versioning
데이터 버전 관리에는 다양한 접근 방식이 있습니다:
Level 0
이 경우 데이터는 파일 시스템에만 저장됩니다. 이러한 경우 데이터가 버전이 없기 때문에 사실상 모델도 버전 관리가 불가능한 문제가 발생합니다. 모델은 본질상 코드 절반, 데이터 절반이기 때문입니다. Level 0 의 데이터 관리는 모델을 이전 버전으로 돌이켜 성능을 회복하고 싶을 때에 그렇게 할 수 없는 결과로 이어질 것입니다.
Level 1
학습을 진행할 때마다 데이터를 스냅샷하는 레벨 1을 사용하면 그런 상황을 방지할 수 있습니다. 이 단계는 다소 효과가 있지만 아직 이상적인 단계는 아닙니다.
Level 2
레벨 2에서 데이터는 마치 코드처럼 버전화됩니다. 버전 코드가 지정되어 마치 하나의 통합된 asset처럼 작동합니다. git-lfs와 같은 시스템을 사용하면 코드와 함께 큰 데이터 asset을 버전화해서 저장할 수 있습니다. 이 방법은 매우 효과적입니다!
Level 3
레벨 3은 대용량 데이터 파일 작업에 특화된 솔루션이 포함되지만, 매우 특별한 요구 사항(즉, 굉장히 크거나 지켜야 할 규칙이 많은 파일)이 없는 한 이 정도의 솔루션은 필요하지 않습니다.
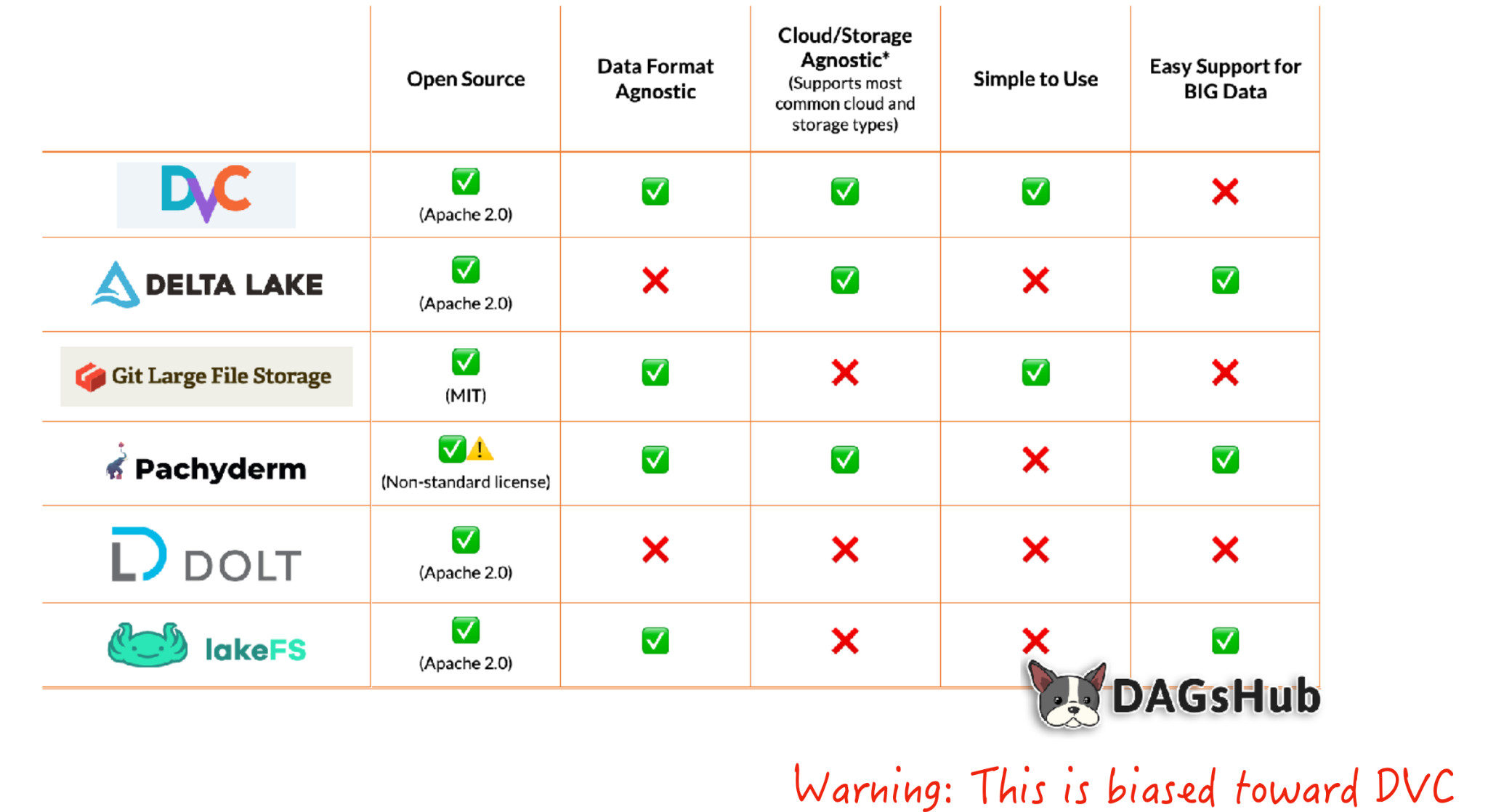
DVC는 이를 위한 훌륭한 도구입니다. DVC는 데이터 파일에 대한 변경 사항을 커밋하거나 커밋을 트리거할 때마다 데이터 자산을 원격 스토리지 위치에 업로드해줍니다. DVC는 마치 git-lfs의 고급 버전과 같다고 보면 됩니다. 데이터 및 모델 아티팩트에 대한 과거 기록 추적과 같은 기능이 있기 때문에 파이프라인을 다시 만드는 데 활용할 수 있습니다.
연합 학습, differential privacy 및 암호화된 데이터에 대한 학습과 같은 기술들은 개인 정보를 관리해야 하는 데이터와 연관되어 있습니다. 이러한 기술은 아직 연구 중이므로 현재는 이렇다 할 권장 사항이 아직 없습니다.
