
Section6 Project의 주제를 채무 불이행 여부를 예측해보자! 로 잡았습니다. 해당 주제는 Section2에서 진행했던 프로젝트를 보완하는 방향으로 목표 설정을 했습니다.
Section2 Project 요약
데이터셋은 캐글에서 다운받은 Bank loan 데이터를 사용했습니다.
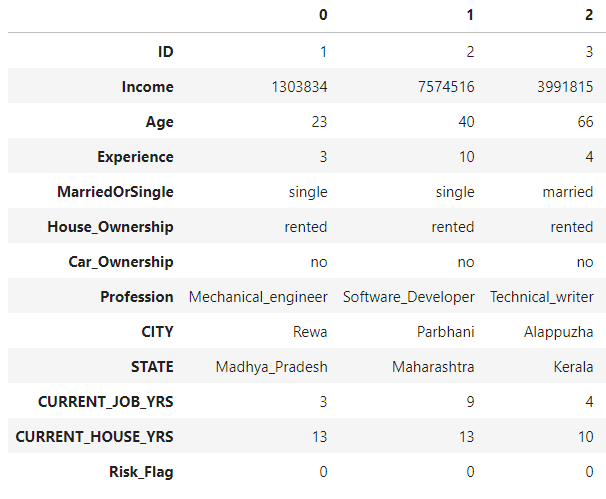
위의 사진처럼 구성된 데이터를 간단한 전처리를 통해서 분석에 사용하지 않을 컬럼을 제거했습니다. 또한 범주형 데이터의 범주를 줄이고 몇몇 수치형 데이터에 대해서 범주형 데이터로 변환시켜주었습니다.
아래 사진은 데이터 전처리를 한 후 head() 메소드를 통해서 살펴본 train 데이터셋입니다.
마지막으로 모델은 pipeline을 사용해서 구축했습니다. OrdinalEncoder와 TargetEncoder, SimpleImputer를 사용해서 데이터를 변환한 뒤 RandomForestClassifier 모델을 사용해 학습을 진행했습니다.
프로젝트를 진행하고 나서 아쉬웠던 점은 다양한 시각화를 도전해보고 싶었는데 시간이 부족해서 하지 못했던 점입니다. 또한 section2에서 배웠던 내용에 집중했던터라 배우지 못했던 모델을 사용해보지 못한 점이 아쉬웠습니다.
때문에 이번 프로젝트에서는 시각화와 모델 비교 그리고 추가적으로 성능 개선(하이퍼파라미터 튜닝)에 집중해보았습니다.
Section6 Project
데이터 탐색
시각화를 진행할 때 새로 알게 된 머신러닝 시각화 라이브러리인 yellowbrick을 주로 사용했습니다.
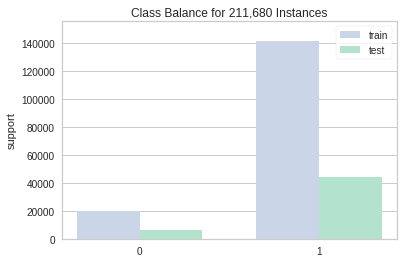
제일 먼저 Target 변수인 Risk_Flag 컬럼의 데이터를 탐색해봤습니다.
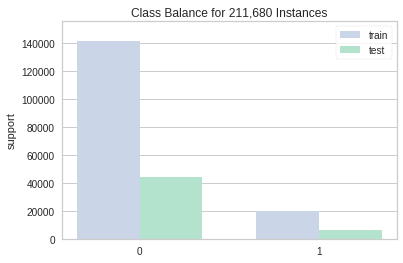
데이터가 0에 치우쳐져있는 상당히 불균형한 데이터임을 확인할 수 있었습니다.
그리고 Profession 컬럼에 대해서도 seaborn 라이브러리를 사용해서 시각화를 진행해봤습니다. 하지만 너무 많은 범주를 가지고 있어서 x축의 값을 확인하기가 어려웠습니다. 이는 STATE 컬럼의 시각화에서도 동일하게 나타났습니다.
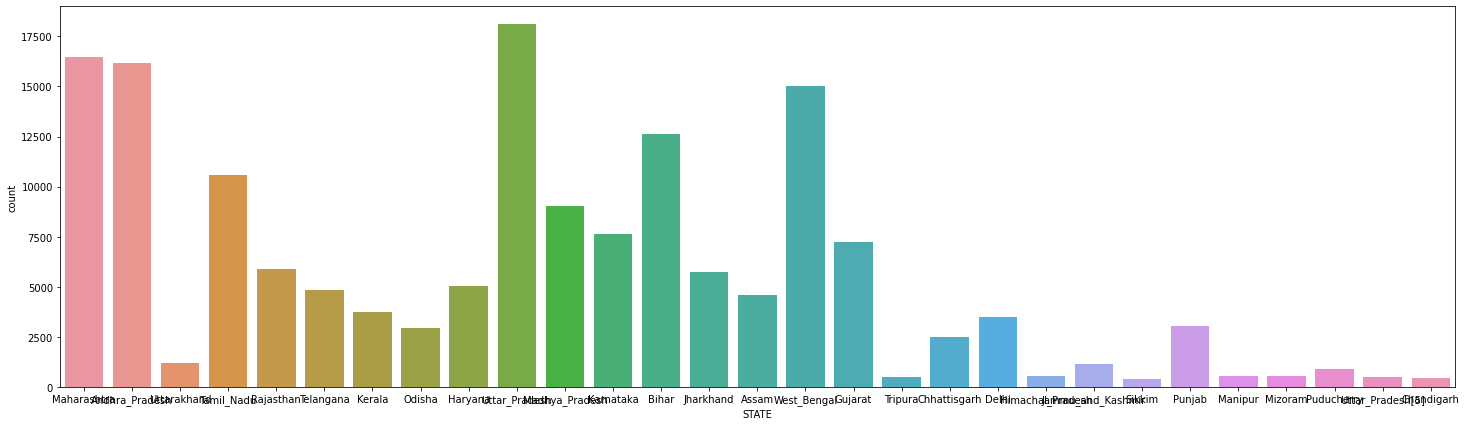
마지막으로 House_Ownership, Car_Ownership, Married_Or_Single 컬럼에 대한 데이터 분포도 한번 살펴봤습니다. 세가지 컬럼 모주 범주형 데이터임을 확인할 수 있었습니다.
데이터 전처리
데이터 전처리를 할 때는 중요하게 생각했던 부분이 범주가 많은 범주형 데이터의 범주를 줄여보자 였습니다.
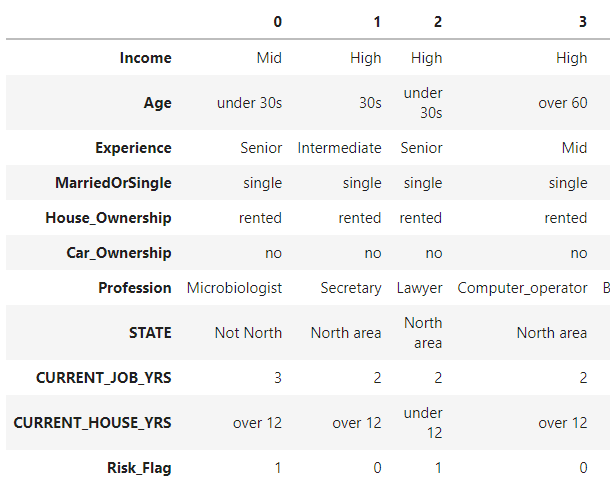
다행스럽게도 범주가 많다고 생각된 컬럼인 STATE와 Profession 컬럼 모두 수작업으로 작업이 불가능할 정도로 많지 않았습니다. 때문에 아래 사진과 같이 Profession를 기존 49가지 범주에서 2가지 범주로 줄여줬습니다.
STATE 컬럼의 경우 사진에는 포함이 되지 않았지만 따로 수도인 Delhi를 Capital로 설정해 29개의 범주에서 3가지 범주로 나뉠 수 있게 분류해주었습니다.

이번에는 plt의 suplot을 사용해서 데이터 전처리가 잘 되었는지 확인해보았습니다.
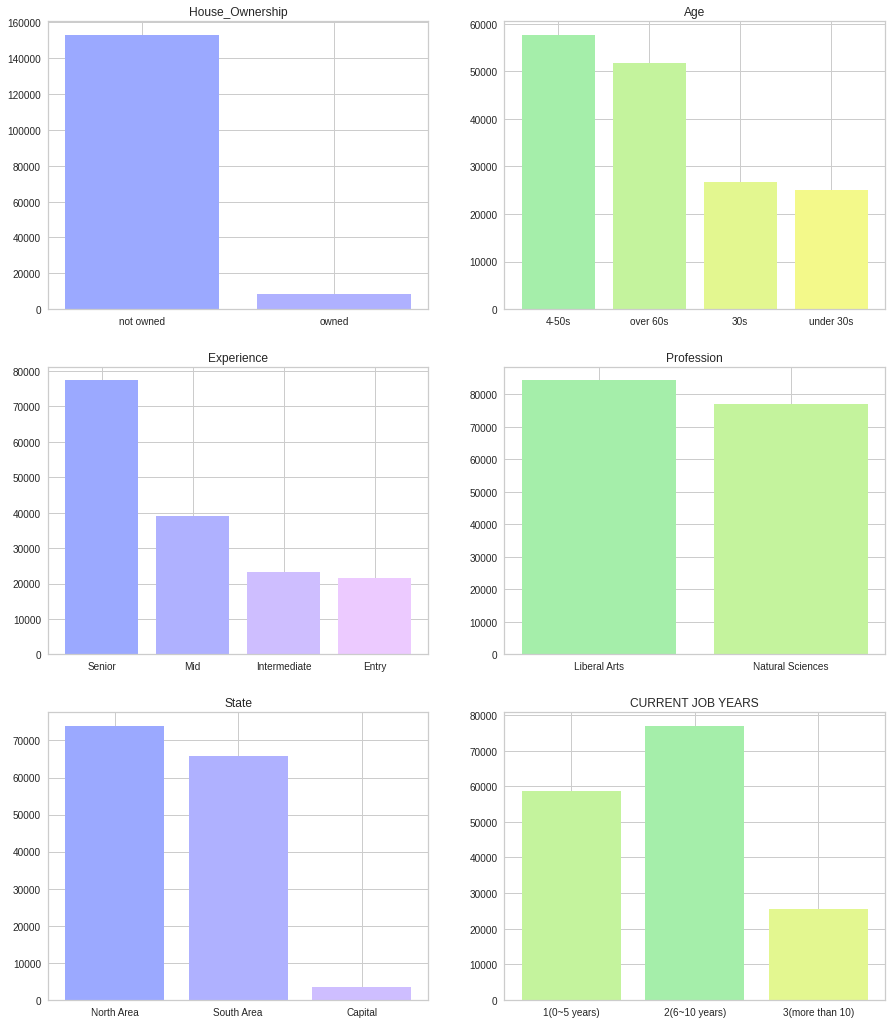
마지막으로 1을 예측하는 모델을 만들고자 Target 변수의 0과 1을 서로 변환해주었습니다.
기존 프로젝트에 진행한 전처리와 차이점
우선 제일 큰 차이점은 바로 Profession 컬럼을 전처리 해주었다는 점입니다. 기존 프로젝트에서는 TargetEncoder를 사용해서 각 직업을 숫자로 바꾸어줬습니다. 하지만 TargetEncoder를 사용했을 경우에는 A라는 직업이 10개, B라는 직업이 10개일 때 A와 B의 인코딩 후 수치가 똑같아진다는 단점이 있다는 것을 알았습니다. 때문에 데이터 전처리를 통해서 사회 계열과 자연 계열로 나누어줬습니다.
다음으로는 Income 컬럼에 대한 전처리를 해주지 않았습니다. 이번 프로젝트를 진행하면서 Income 컬럼을 전처리 했을 경우와 하지 않았을 경우를 비교해보았습니다. 하지만 Accuracy와 f1 score, ROC/AUC curve 모두 다른 점이 없었습니다. 또한 Income 컬럼을 전처리하려면 따로 MinMaxScaler를 사용했기 때문에 전처리를 패스해주었습니다.
마지막으로 기존 프로젝트에서는 North Area가 아래 사진과 같이 16개 지역이었지만, 이번에는 총 19개 지역으로 늘려주었습니다.

모델 비교
XGBClassifier
히스토램 기반 그레이디언트 부스팅은 뛰어난 앙상블 학습으로 평가 받고 있습니다. 히스토램 기반 그레이디언트 부스팅 라이브러리 중에서 가장 대표적인 라이브러리로 XGBoost로 꼽을 수 있습니다. XGBClassifier는 XGBoost 라이브러리에 포함된 모델입니다.
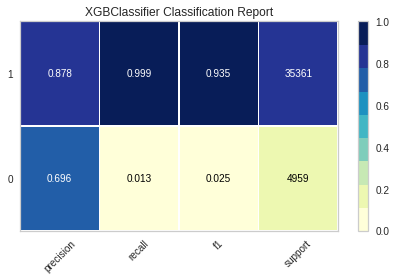
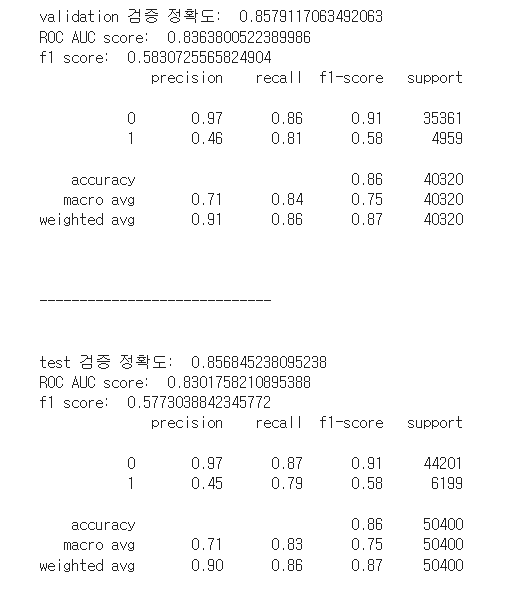
XGB 모델의 학습을 진행했을 때 위와 같은 지표를 얻을 수 있었습니다. 0에 관한 recall 점수가 매우 낮은 것을 볼 수 있었고 f1 score 또한 0에 가까운 점수를 얻었습니다.
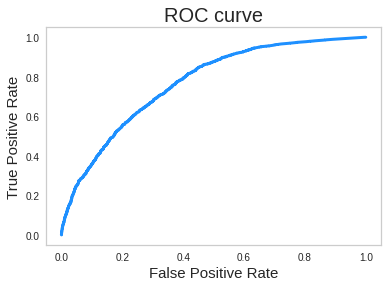
ROC/AUC Curve를 그려봤을 때 아래와 같은 그래프를 얻을 수 있었습니다. 해당 모델의 ROC/AUC Score는 0.5061로 거의 학습이 되지 않았음에 대해 확인이 가능했습니다.
LightGBM
LightGBM은 히스토램 기반 그레이디언트 부스팅 모델 중 하나로 빠르다는 장점을 갖고 있습니다. 실제로 학습을 진행했을 때 다른 모델들 보다 훨씬 빠르게 학습을 하는 모습을 확인할 수 있었습니다.
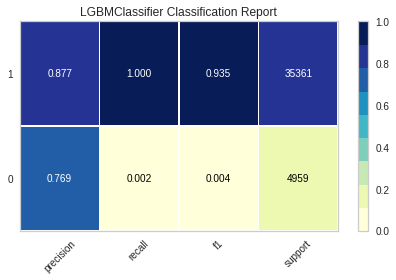
LightBGM 모델도 XGBClassifier 모델과 마찬가지로 0에 관한 recall score와 f1 score가 매우 낮게 나왔습니다.
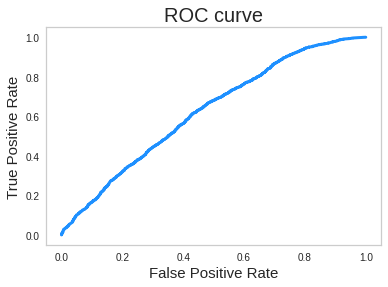
또한 ROC score도 0.501로 그래프를 그려봤을 때 거의 직선에 가까우므로 학습이 제대로 이루어지지 않았음을 확인할 수 있었습니다.
ExtraTreesClassifier
ExtraTreesClassifier는 랜덤 포레스트와 비슷하게 동작하지만 부트스트랩 샘플을 사용하지 않는다는 차이점을 갖고 있습니다. 부트스트랩을 사용하지 않는 대신 노드를 분할할 때 best를 찾아 분할하는게 아닌 무작위로 분할한다는 특징을 갖고 있는 모델입니다.
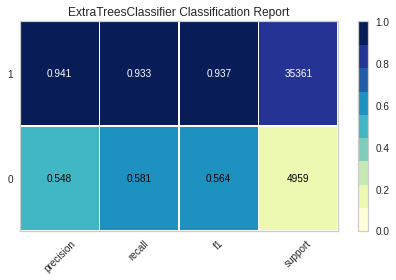
ExtraTreesClassifier는 0에 대한 평가 지표들이 낮은 편이었지만 앞의 두 모델과는 다르게 precision과 recall f1 모두 0.5 정도가 나왔기 때문에 제일 준수한 결과가 나왔다고 평가했습니다.
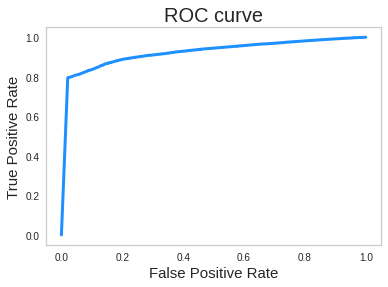
또한 ROC Score도 0.7567로 학습이 괜찮게 되었음을 확인해볼 수 있었습니다.
HistGradientBoostingClassifier
히스토램 기반 그레이디언트 부스팅은 정형 데이터를 다루는 머신러닝 모델 중 제일 인기가 많은 모델이다. 과대적합을 잘 억제하면서 그레이디언트 부스팅 모델보다 조금 더 높은 성능을 제공해줍니다.
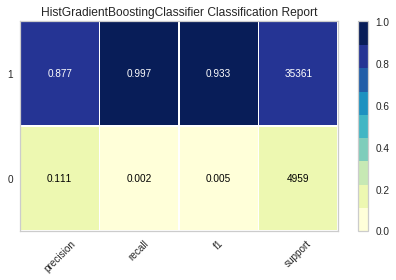
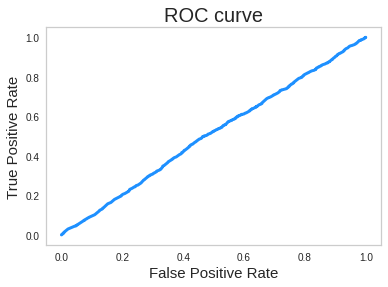
마지막으로 진행한 모델인 HistGradientBoostingClassifer도 앞서 진행했던 XGB모델과 LightGBM모델과 별반 다르지 않은 성능을 기록했습니다.
최종 모델
위의 모델들을 비교해봤을때 제일 우수한 성능을 가진 ExtraTreesClassifier를 최종 모델로 선정했습니다.
하이퍼파라미터 튜닝
하이퍼파라미터 튜닝은 GridSearchCV를 통해 진행했습니다. 다만 시간이 오래 걸리는 것을 감안해서 넉넉하게 시작했음에도 불구하고 중간중간 아래 사진과 같이 코랩 런타임이 끊겨버리는 일이 발생해서 제대로 된 하이퍼파라미터 튜닝을 하지 못해서 아쉬웠습니다.

때문에 최초로 시작했을 때는 총 8개의 하이퍼파라미터를 최소 3개 최대 5개의 값을 설정하고 시작했지만 장렬하게 실패를 겪었습니다.
몇 번의 실패를 거친 후 욕심을 버리고 아래와 같이 하이퍼파라미터를 설정했고 대략 6시간 정도를 기다린 후에 하이퍼파라미터 튜닝에 성공했습니다.

그리고 최종적으로 다음과 같이 하이퍼파라미터 튜닝을 했습니다.

기존 프로젝트 최종 모델과 비교
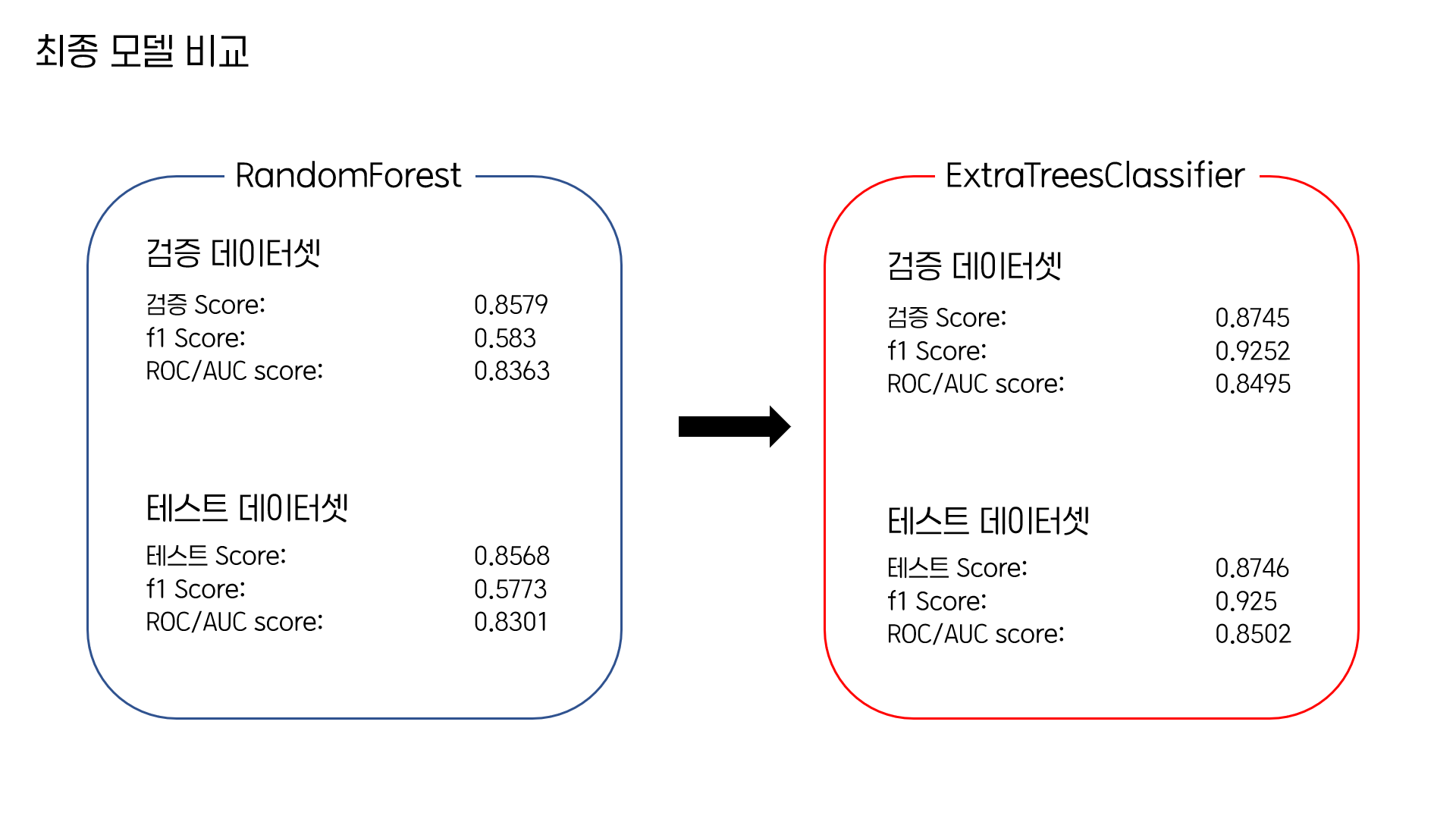
이번 프로젝트에서 선정된 최종 모델인 ExtraTreesClassifier를 GridSearchCV를 통해서 하이퍼파라미터 튜닝을 진행한 후에 Section2 프로젝트의 최종 모델이었던 RandomForest와 비교해보았습니다.
제일 눈에 띄는 변화는 바로 F1 Score가 크게 올랐다는 점이었습니다.
특성 중요도
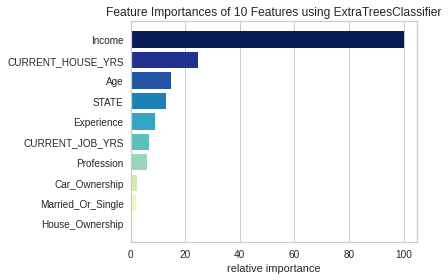
yellowbrick 라이브러리를 활용해서 특성 중요도에 대해서 간단하게 그려보았습니다. Income, CURRENT_HOUSE_YRS, Age, STATE, Experience 순으로 중요한 특성임을 확인할 수 있었습니다.
Confusion Matrix
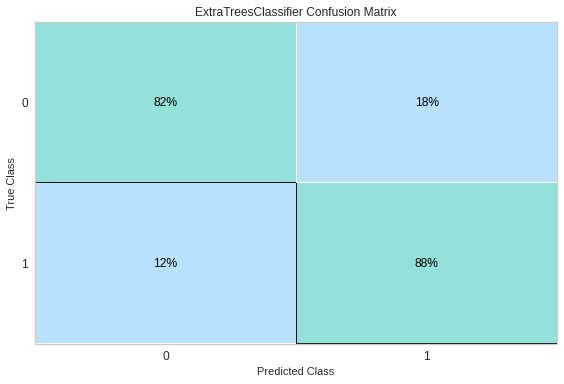
Confusion Matrix에서는 1을 올바르게 1이라고 예측한 경우가 88%, 0을 올바르게 0으로 예측한 경우가 82%에 달하는 것을 확인해 볼 수 있었습니다.
Classification Report
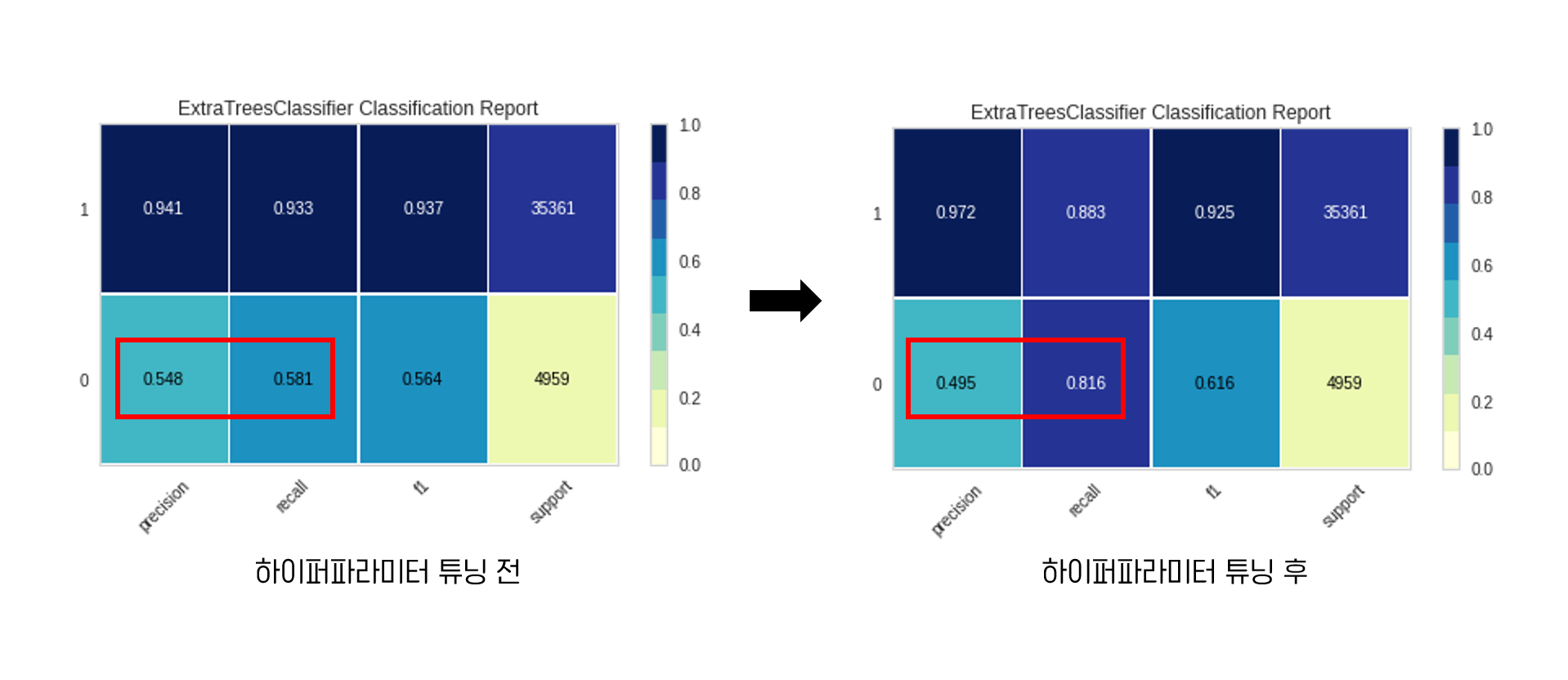
마지막으로 Classification Report를 하이퍼파라미터 튜닝 전과 후를 비교해보았습니다.
하이퍼파라미터 튜닝 전에는 0에 대한 precision 점수가 0.548, recall 점수는 0.581이었습니다. 튜닝 후에는 precision 점수가 낮아져서 0.495, recall 점수가 높아져서 0.816을 기록했다는 점이 제일 큰 차이점입니다.

안녕하세요 ! 혹시 데이터셋은 정확히 캐글의 어떤 이름의 데이터셋이었는 지 알려주실 수 있으실까요?