이전 포스트에서 기존 모델(LSTM + FC Layer)에서 입력에 이전 날의 상추 무게를 concat하여 모델 개선을 이루어냈다. 이번에는 transformer 모델로 변경하여 학습을 시켜보려 한다.
항상 hugging face를 통해 BERT와 같은 모델을 사용했었지 transformer 모델을 실제 데이터에 학습시켜보는 것은 처음이라 여러 번 테스트해보고 학습에 적용했다.
transformer 테스트
먼저 PyTorch에서 transformer 모델을 어떻게 사용하는지 공식 문서를 찾아봤다.
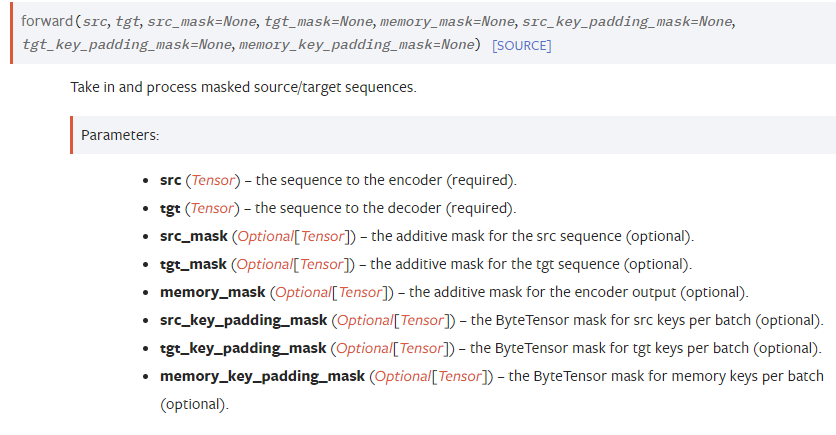
forward 과정에서 src, tgt가 필요한 것을 알 수 있다.
현재 내가 적용하려는 생육 환경에서 tgt는 sequence가 아니라 그 날의 상추 무게인 스칼라 값이라 이를 적용하기에는 좋은 모델이라 생각되지 않아 decoder를 제외한 encoder 모델만 사용하기로 결정했다.
(그래도 28일 간의 상추 무게 sequence로 고려하여 모델을 구성할 수 있을 것 같긴 하다.)
transformer encoder
PyTorch에 transformer encoder만을 또 따로 제공해준다. 공식 문서
예제를 보면 encoder layer를 선언하고, encoder를 선언할 때 그 encoder layer를 변수로 선언한다.
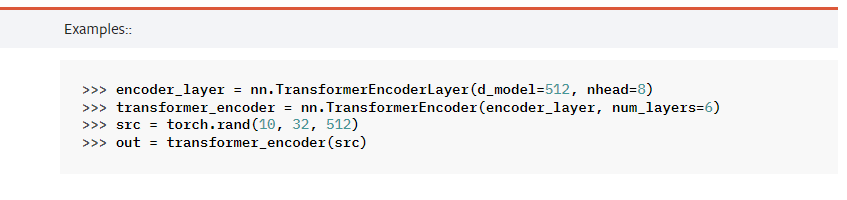
입력의 차원 : (batch size, sequence 길이, d_model)
출력의 차원 : (batch size, sequence 길이, d_model)
모델 적용
이제 어느정도 PyTorch의 transformer encoder 모델을 어떻게 사용하는지 익혔으니, 이를 학습에 사용될 수 있는 형태로 모델을 만들었다.
사실상 이전 LSTM 모델에서 LSTM을 transformer encoder로 변경한 것 말고는 크게 달라진 점은 없다.
class TransformerEncoderModel(nn.Module):
def __init__(self, d_model=16, nhead=4, num_layers=6):
super(TransformerEncoderModel, self).__init__()
self.d_model = d_model
self.nhead = nhead
self.num_layers = num_layers
self.encoder_layers = [
nn.TransformerEncoderLayer(d_model=self.d_model, nhead=self.nhead)
for _ in range(28)
]
self.encoders = nn.ModuleList([
nn.TransformerEncoder(self.encoder_layers[i], num_layers=self.num_layers)
for i in range(28)
])
# self.pos_encoder = PositionalEncoding(d_model)
self.linears = nn.ModuleList([
nn.Linear(self.d_model * 24, 1) for _ in range(28)
])
def forward(self, x):
# x : (batch_size, day, hour, feature) - (N, 28, 24, 15)
prev_weights = [0] * CFG['BATCH_SIZE']
output_weights = torch.Tensor().to(device)
for encoder, linear, chunks in zip(self.encoders, self.linears, torch.chunk(x, 28, dim=1)):
# chunk : (1, 24, 15)
input_tensor = torch.Tensor().to(device)
for chunk, prev_weight in zip(chunks, prev_weights):
prev_weight_tensor = torch.Tensor(24).fill_(prev_weight).view(1, -1, 1).to(device)
x = torch.cat([chunk, prev_weight_tensor], dim=-1)
input_tensor = torch.cat([input_tensor, x], dim=0)
output = encoder(input_tensor) # x : (N, 24, 16)
weights = linear(output.view(-1, self.d_model * 24)) # weights : (N, 1)
output_weight = weights.unsqueeze(dim=1)
prev_weights = weights.squeeze(dim=1)
output_weights = torch.cat([output_weights, output_weight], dim=1)
return output_weights학습 결과
학습 결과는 다음과 같았다.
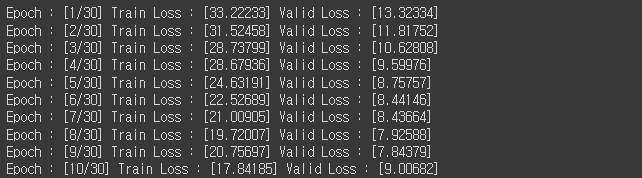
확실히 이전 LSTM 모델에 비해 train loss와 valid loss가 줄어든 것을 확인할 수 있었다. 그러나 9 epoch 이후부터는 valid loss가 크게 증가하여, 오버피팅이 일어나는 것 또한 확인할 수 있었다.
제출 결과
이전 LSTM 모델이 16점이 나온 반면, 이번 모델은 17점이 나왔다.
제출 결과는 예상과는 다르게 좋지 못했다.
일단 직접 학습된 결과를 보면서 어떤 문제가 있는 지 살펴봐야 할 것 같다.
