분할(Segmentation)
아래 이미지와 같이 하나의 이미지에서 같은 의미를 가지고 있는 부분을 구분해내는 Task

동일한 의미(사람, 자동차, 도로, 인도, 자연물 등)마다 해당되는 픽셀이 모두 레이블링 되어있는 데이터셋을 픽셀 단위에서 레이블을 예측한다
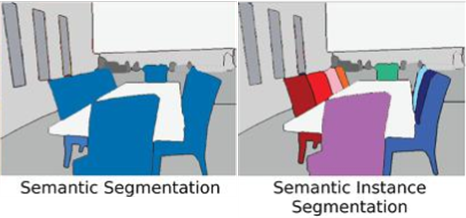
Semantic Segmentation vs (Semantic) Instance Segmentation
의미적(Semantic)으로 '사람'으로 분류되는 개체에 대해서는 모두 동일하게 라벨링을 해줌
이러한 구분 방식을 의미적 분할(Semantic Segmentation)이라고 함
 이렇게 개체까지 구분하는 방식을 Instance Segmentation 이라고 함
이렇게 개체까지 구분하는 방식을 Instance Segmentation 이라고 함
두 방법을 아래와 같이 구분한다
대표적인 Segmentation Model
이미지 분할(Segmentation)을 위한 대표적인 모델 --> FCN, U-net
FCN(Fully Convolutional Networks)
CNN의 분류기 부분, 즉 완전 연결 신경망(FUlly Connected layer)부분을 합겅곱 층(Convolutional Layer)으로 대체한 모델
FCN에서는 CNN에서 사용하였던 완전 연결 신경망의 위치정보를 무시한다는 단점을 합성곱 층으로 모두 대체함으로써 해결함
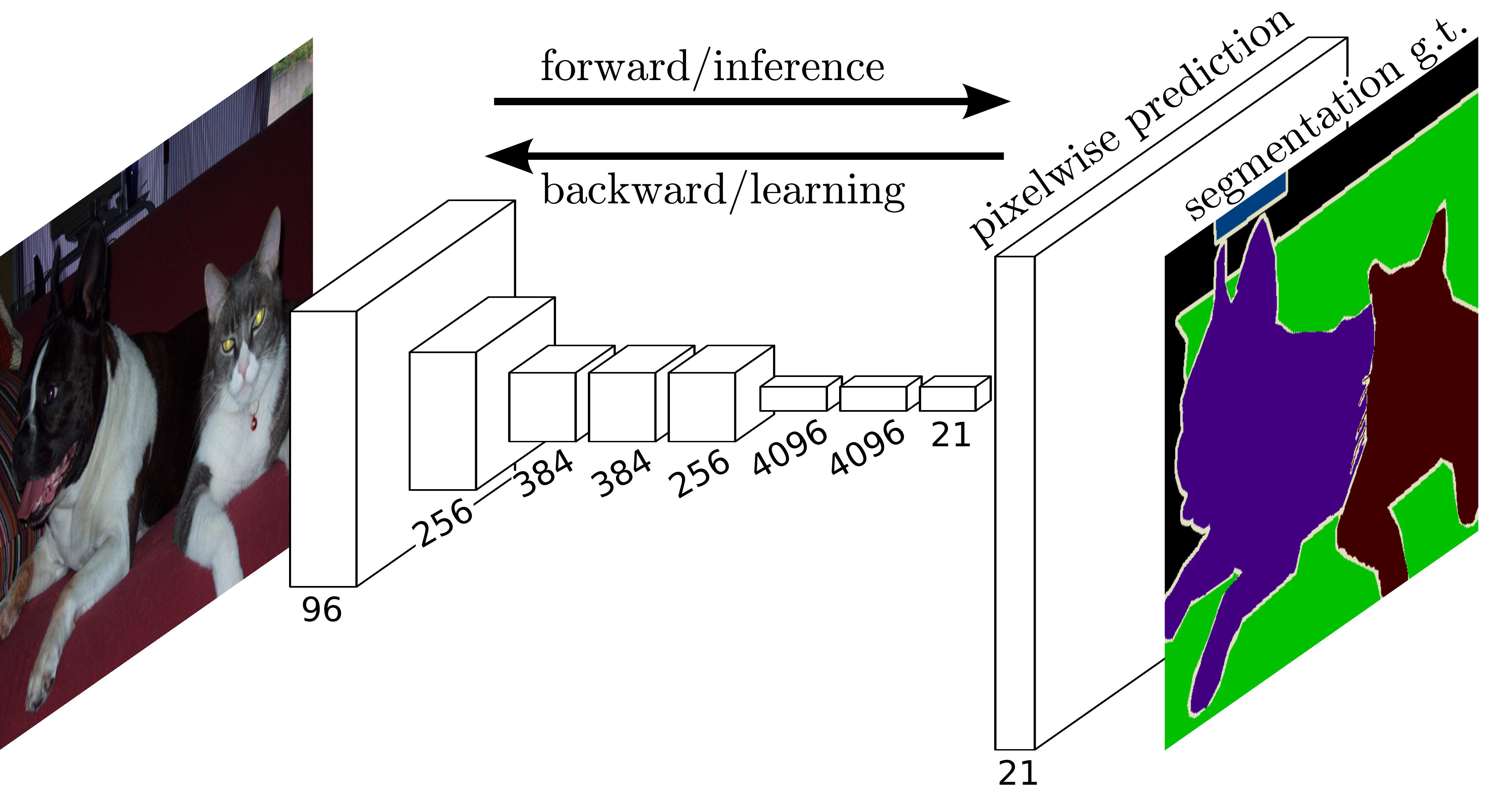
갑자기 이미지의 크기가 커지는 부분은
Segmetntatio은 픽셀별로 분류를 진행하기 때문에 원래 이미지와 비슷하게 크기를 키워주는 Upsampling을 해주어야 한다
- Upsampling
CNN에서 사용되는 것처럼 Convolution과 Pooling을 사용하여 이미지의 특징을 추출하는 과정을 Downsampling(다운샘플링)이라고 함 반대로 이미지의 크기로 키우는 과정은 Upsampling(업샘플링)
Upsampling에는 기존 Convolution 과는 다른 Transpose Convolution이 적용됨
Transpose Convolution 에서는 각 픽셀에 커널을 곱한 값에 Stride를 주어 나타냄으로써 이미지 크기를 키워나감
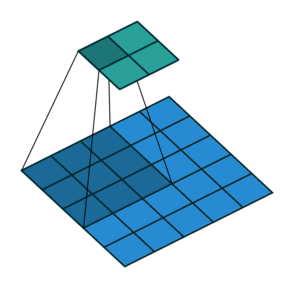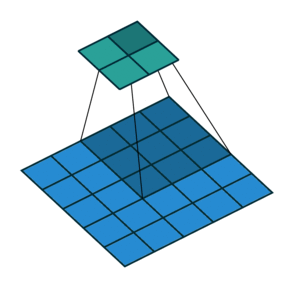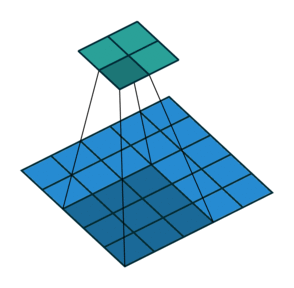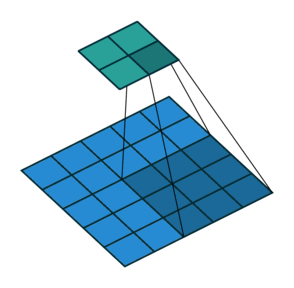
2X2 이미지가 입력되었을 때 3X3 필터에 의해 Transpose convolution되는 과정
U-net
Segmentation을 위한 대표적 모델 중 하나
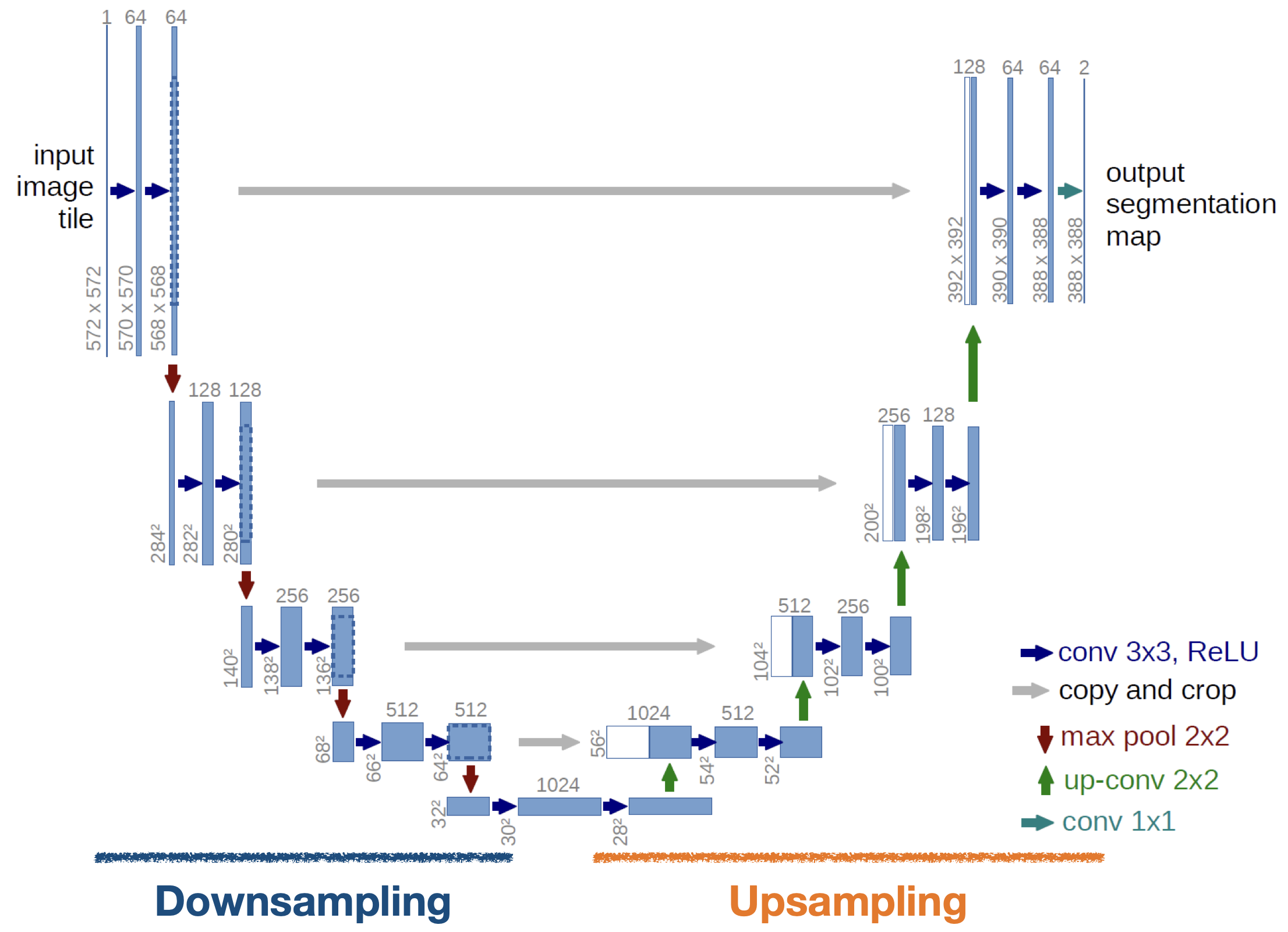
Downsampling과 Upsampling 두 부분으로 나눌 수 있다
Downsampling에서는 Convolution과 Maxpooling을 거치며 이미지의 특징을 추출
Upsampling에서는 Convolution과 Transpose Convolution을 거치며 원본 이미지와 비슷한 크기로 복원
Downsampling 출력으로 나왔던 Feature map을 적당한 크기로 잘라서 붙여준 뒤 추가 데이터로 사용
Example
- 필요한 패키지 다운로드 후 import
- Dataset을 다운로드
- 전처리 함수를 정의
이미지와 정규화 하는 함수를 정의하고 훈련 및 시험 데이터셋을 불러오는 전처리 함수 정의 - 데이터셋에 전처리 함수를 적용
- 특정 이미지를 불러와서 Segmentation이 잘 되었을 때 픽셀의 클래스가 어떻게 분류될지 확인
- 모델 정의
- 모델의 예측을 보여주는 함수와 학습 중에 해당 함수를 동작할 수 있도록 Callback을 정의
- 모델 학습
- 학습 완료 후 시험 데이터셋 내 특정 이미지에 대한 예측 결과 시각화
객체 탐지/인식(Object Detection/Recognition)
객체 탐지/인식은 전체 이미지에서 레이블에 맞는 객체를 찾아내는 Task
자율주행을 위한 주요 인공지능 기술로 사용
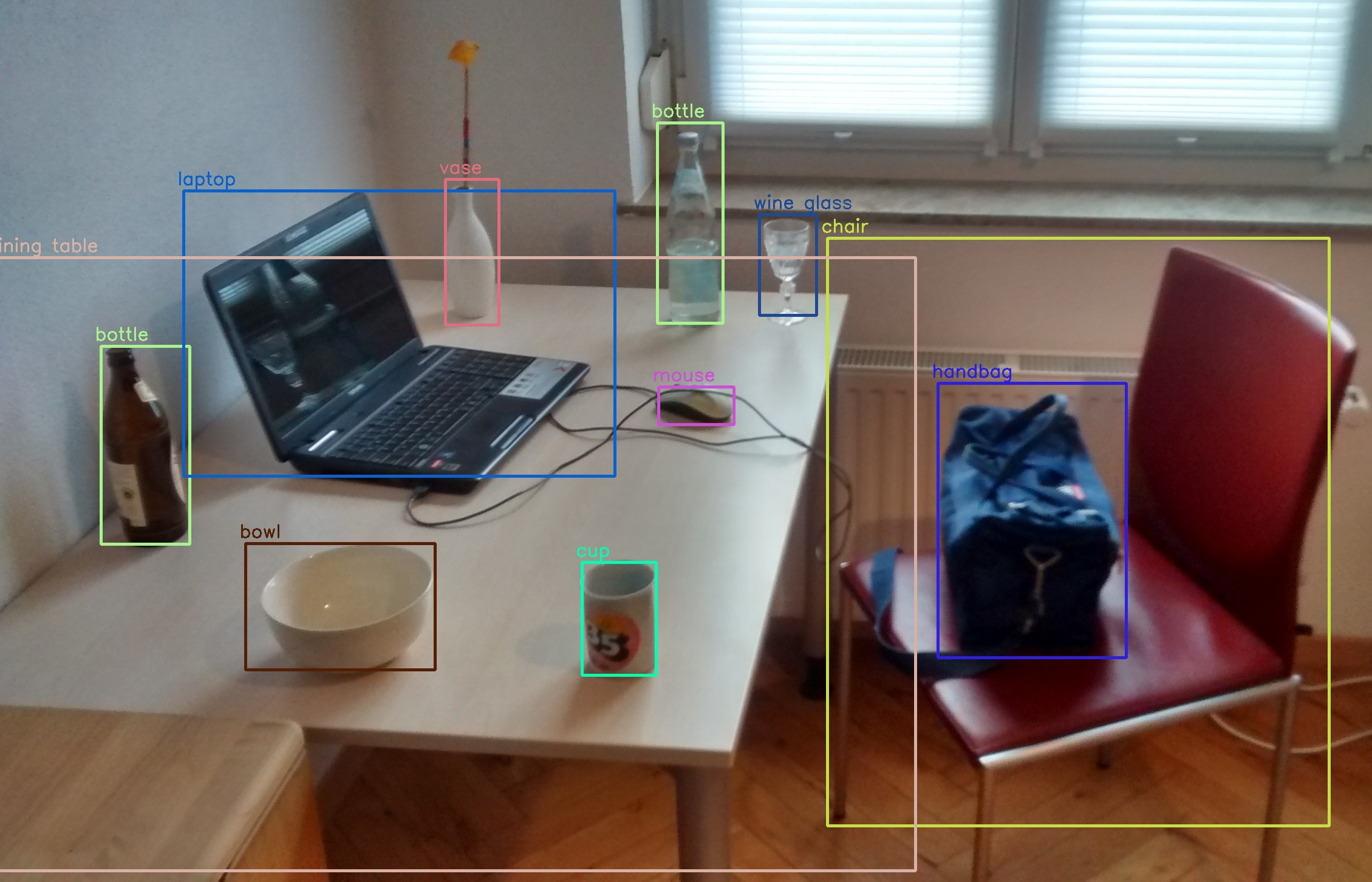
Bounding Box라고 하는 사각형 박스를 만든 후, 박스 내의 객체가 속하는 클래스가 무엇인지 분류
IoU(Intersection over Union)
객체 탐지를 평가하는 지표
초록색 박스처럼 정답에 해당하는 Bounding Box를 Ground-truth라고 함

모델이 빨간색 박스처럼 예측했을 때 IoU는 다음 식을 사용하여 구할 수 있다
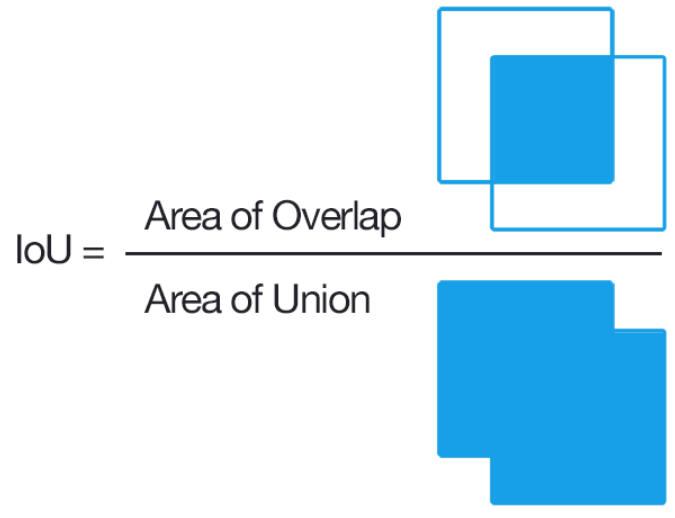
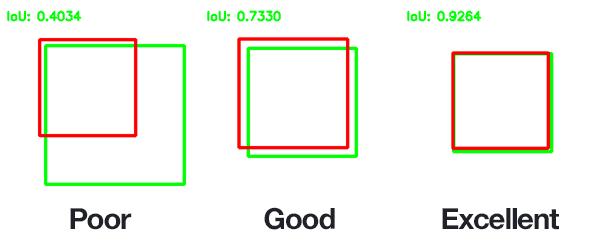
IoU를 사용하면 객체가 포함되어 있지만 너무 큰 범위를 잡는 문제를 해결할 수 있다
Ground-truth/Prediction에 해당하는 Bounding Box에 따라 IoU가 구해지는 예시
대표적인 개체 탐지 Model

어떤 단계를 거쳐 분류가 진행되는지에 따라 2-stage방식과 1-stage방식으로 나눔
Two Stage Detector
Two Stage Detector는 일련의 알고리즘을 통해 객체가 있을만한 곳을 추천받은(Region Proposal) 뒤에 추천받은 Region, 즉 RoI(Region of Interest)에 대해 분류를 수행하는 방식
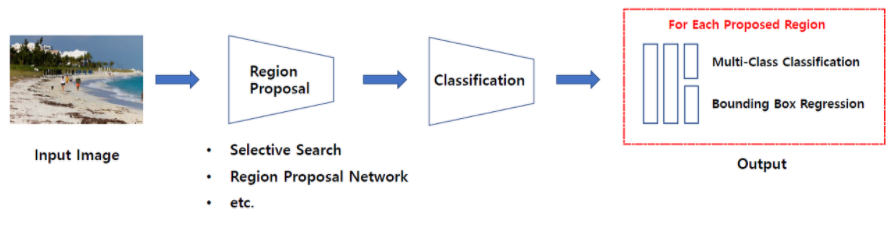
R-CNN계열(R-CNN, Fast R-CNN, Faster R-CNN 등)의 모델이 있다
One Stage Detector
One Stage Detector는 특정 지역을 추천받지 않고 입력 이미지를 Grid 등의 같은 작은 공간으로 나눈 뒤 해당 공간을 탐색하며 분류를 수행하는 방식
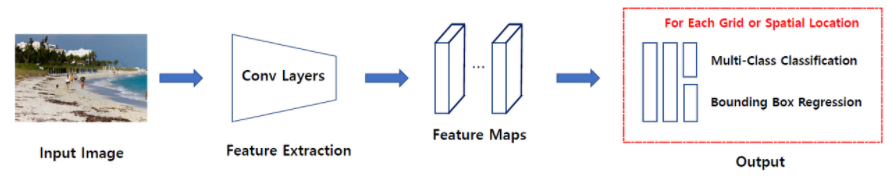
모델로는 SSD(Single Shot multibox Detector)계열과 YOLO(You Only Look Once)계열의 모델이 있다
YOLO모델
13 x 13 / 26 x 26 / 52 x 52 (세밀한 Detrection 가능) 3가지의 Feature Map을 동시에 얻을 수 있기 때문에 속도가 굉장히 빠르다 인식속도는 초당 120프레임
R-CNN과 YOLO 레퍼런스 : https://hackmd.io/PREEDxG4QDqDlRyVQ5rG1A
YOLO모델 코드 레퍼런스 : https://colab.research.google.com/drive/1x2-2frS8kIO5hk2jUcQIWzGfzgOZn4uX?usp=share_link
