학습률, Learning Rate
매 가중치에 대해 구해진 기울기 값을 얼마나 경사 하강법에 적용할 지를 결정하는 하이퍼파라미터
학습률은 처음엔 크게주고 점점 작게주면서 최소를 찾는게 좋다
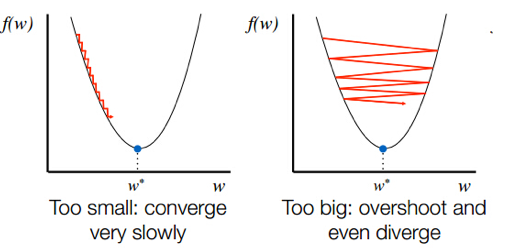
학습률이 너무 크거나 작으면최적점에 이르기까지 너무 오래 걸리거나 주어진 Iteration 내에서 최적점에 도달하는 데 실패하기도 함
때문에 최적의 학습률을 찾는 것은 학습에서 중요한 요소
해결방법 : 학습률 감소 / 학습률 계획법
1. 학습률 감소, Learning rate Decay
학습률 감소는 Adagrad, RMSprop, Adam 과 같은 주요 옵티마이저에 이미 구현되어 있기 때문에 쉽게 적용할 수 있다. 해당 옵티마티저의 하이퍼파라미터를 조정하면 감소 정도를 변화시킬 수 있다
# optimizer 내 lr(learning rate) 인자를 통해 학습률을 설정할 수 있습니다. beta_1 인자는 학습률 감소율을 설정하며 Adam 내 수식의 변수를 그대로 사용합니다.
model.compile(optimizer=tf.keras.optimizers.Adam(lr=0.001, beta_1 = 0.89)
, loss='sparse_categorical_crossentropy'
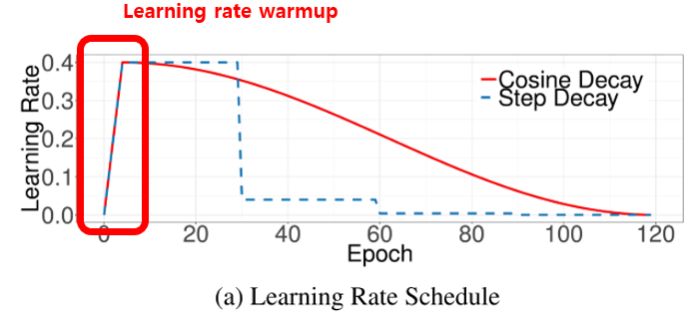
, metrics=['accuracy'])2. 학습률 계획법, Learning rate Scheduling
Warm-up Step
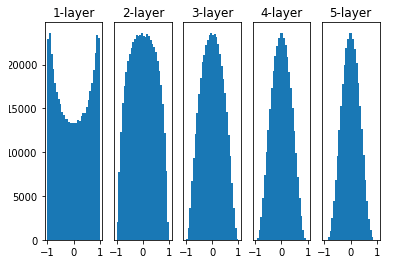
가중치 초기화
1) Xavier 초기화
2) He 초기화Sigmoid ⇒ Xavier 초기화
ReLU ⇒ He 초기화
적용하는 방법
# 모델 내 추가하는 Dense layer 내 kernel_initializer 인자를 통해 가중치 초기화를 설정할 수 있습니다.
Dense(32, activation='relu', kernel_initializer='he_uniform')머신러닝으로써의 딥러닝
딥러닝도 머신러닝 모델이라고 할 수 있기 때문에 과적합에 주의해야함
과적합 방지를 위한 방법들
1. 가중치 감소, Weight Decay
과적합은 가중치의 값이 클 때 주로 발생.
가중치 감소에서는 가중치 값이 너무 커지지 않도록 조건을 추가
손실 함수에 가중치와 관련된 항을 추가
Keras에서 가중치 감소를 적용하고 싶은 층에 regulaizer 파라미터를 추가한다
# from tensorflow.keras import regularizers
Dense(64,
kernel_regularizer=regularizers.l2(0.01),
activity_regularizer=regularizers.l1(0.01))2. 드롭 아웃, Dropout
Iteration 마다 레이어 노드 중 일부를 사용하지 않으면서 학습을 진행하는 방법
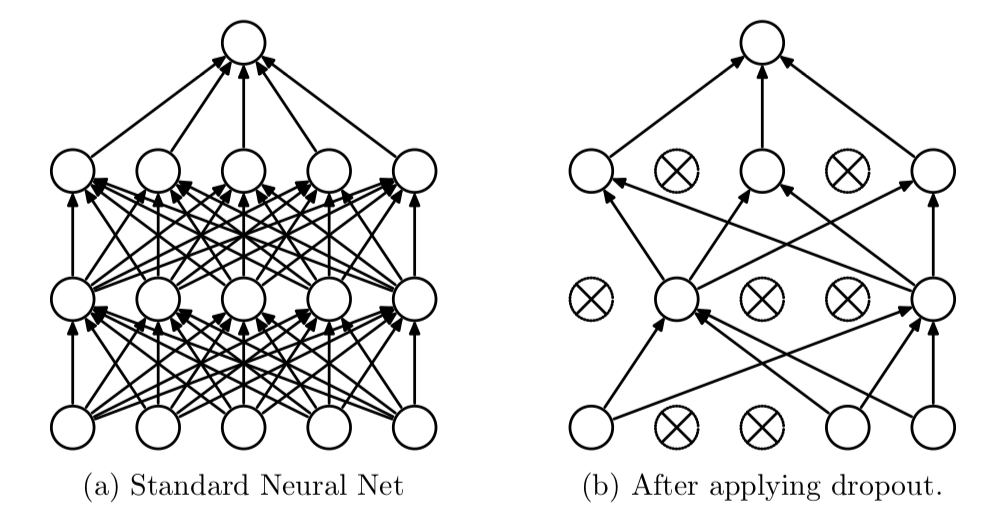
Dropout을 적용할 때 0~1 사이의 실수를 입력한다
Keras 에서는 아래와 같이 Dropout 을 적용하고 싶은 층 다음에 Dropout 함수를 추가하면 됩니다.
# from tensorflow.keras import regularizers
# from tensorflow.keras.layers import Dropout
Dense(64,
kernel_regularizer=regularizers.l2(0.01),
activity_regularizer=regularizers.l1(0.01))
Dropout(0.5) <<< 이 부분
3. 조기 종료, Early Stopping
학습 데이터에 대한 손실은 계속 줄어들지만 검증 데이터셋에 대한 손실은 증가한다면 학습을 종료
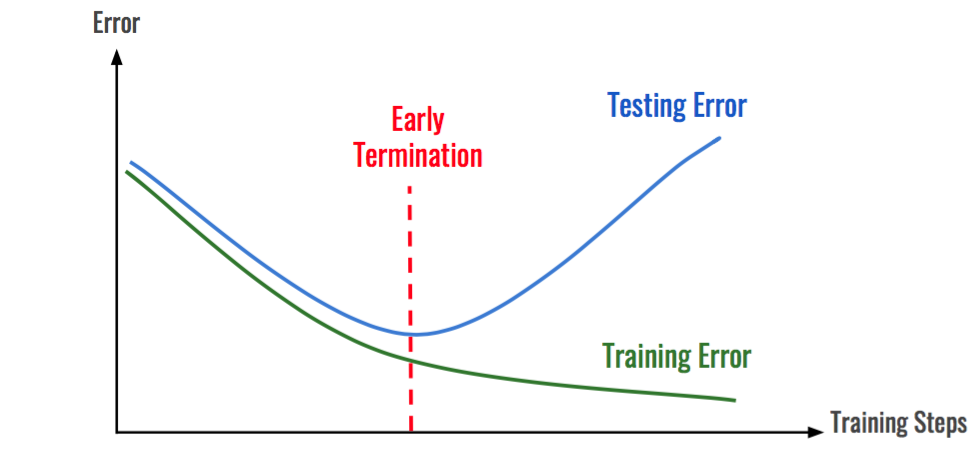

ㅋㄷ