알고리즘/자료구조 <면접>
1.선형 자료구조
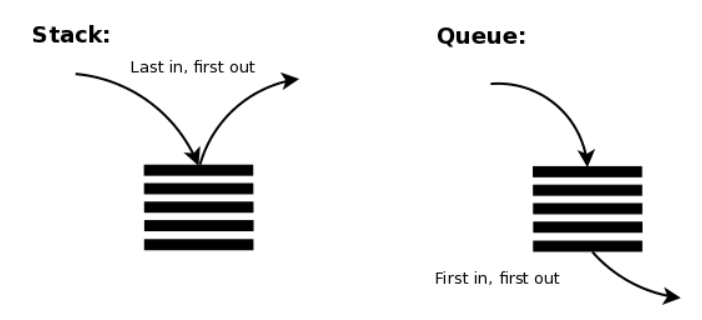
크기를 지정하고 해당 크기만큼의 연속된 메모리 공간을 할당받는 작업을 수행하는 자료형을 말합니다.장점메모리에 연속적으로 할당되어 있어 어느 위치에서나 O(1)에 조회가 가능(검색 성능 우수)인덱스를 이용하여 무작위 접근 가능(순차 접근을 하지 않아도 됨)순차 접근을 하
2.비선형 자료구조
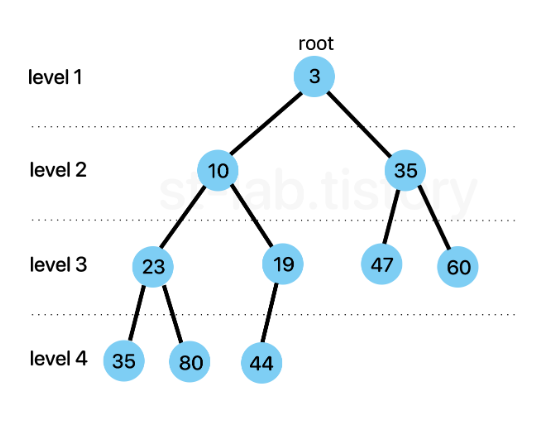
최솟값 또는 최댓값을 빠르게 찾아내기 위해 완전이진트리 형태로 만들어진 자료구조입니다.마지막 노드를 제외한 모든 노드가 채워져있으면서 리프 노드가 왼쪽부터 채워진 노드를 말합니다. 여기서 추가로 리프 노드 외 모든 노드가 2개의 자식 노드를 갖게 되면 포화 이진 트리(
3.알고리즘

합리적인 시간 내에 최적에 가까운 답을 찾는 매우 실용적인 알고리즘입니다. 최적해를 찾기도 하고 대부분은 정답을 근사하게 찾는 용도로 활용되고 속도가 매우 빠릅니다. 활용 가능한 문제로는 최적 부분 구조와 탐욕 선택 속성이 있습니다. 최적 부분 구조는 문제의 최적 해결
4.동적 계획법(DP)
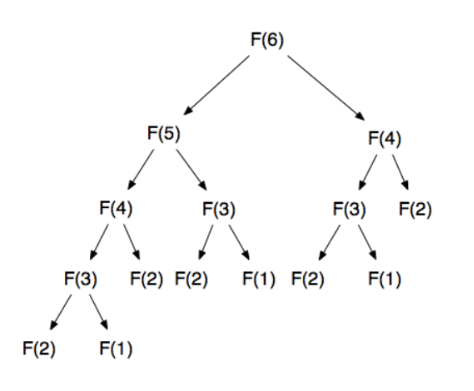
문제를 각각의 작은 문제로 나누어 해결한 결과를 저장해뒀다가 나중에 큰 문제의 결과와 합하여 풀이하는 알고리즘입니다. 풀이 방법에는 상향식 타뷸레이션과 하향식 메모이제이션이 있습니다. 타뷸레이션은 작은 문제의 정답을 이용하여 큰 문제를 해결하는 식이고, 메모이제이션은
5.유클리드 호제법
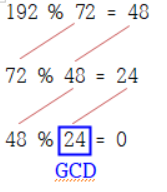
자연수 a,b에 대해서 a와 b를 나눈 나머지를 r이라 한다면, a,b의 최대 공약수와 b,r의 최대 공약수는 같다.최대 공약수(GCD) 찾기 192와 72의 최대 공약수를 찾는 경우 192/72는 약분하면 8/3이 됨 192 % 72 = 4872 % 48 = 2448
6.에라토스테네스의 체
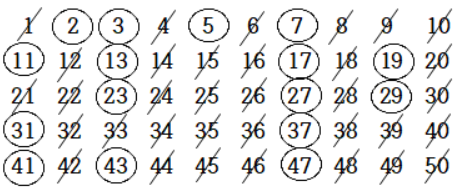
특정 자연수 범위에서 소수 숫자를 판별하기 위한 대표적인 알고리즘2부터 N까지 모든 자연수를 나열N이하 범위에서 2부터 자기 자신을 제외한 배수들을 제거위 과정은 N의 제곱근까지 반복반복 과정이 끝난 후 남은 수들이 소수ref : https://velog.io
7.효율적인 약수 개수 구하기
일반적인 방법개선된 알고리즘한 개의 약수를 찾는 순간, 반대편 약수의 존재도 보장된 것이므로 체킹 횟수를 대폭 줄일 수 있다.
8.Upper Bound(상계), Lower Bound(하계)
원하는 값을 찾지 못했을 때 -1을 반환하는 이진 탐색과 달리 원하는 값을 초과하는 첫 번째 위치, 원하는 값 이상의 첫 번째 위치를 반환한다.이렇게 -1이 아닌 어떻게든 적절한 위치를 찾아낸다는 특성 덕분에 주로 특정 값을 배열의 어느 위치에 넣어야 되는지를 탐색할
9.허프만 알고리즘
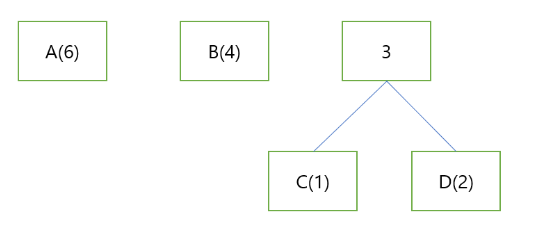
압축 단위마다 문자의 출현 빈도를 조사하여 빈도가 높은 순서대로 비트 수가 적은 부호를 부여함으로써 데이터를 압축하는 방식간단히 말해서 많이 사용된 문자는 더 적은 비트로 나타내고 적게 사용된 문자는 더 많은 비트를 사용하여 효율적으로 문자열을 나타내는 방식문자 압축
10.퀵 정렬(Quick Sort)
하나의 리스트를 피벗(pivot)을 기준으로 하나는 pivot보다 작은 값들의 부분리스트, 하나는 pivot보다 큰 값들의 부분리스트로 정렬한 뒤, 각 부분리스트에 대해 위 방식대로 재귀적으로 수행하여 정렬하는 방법분할 정복(Divide and Conqure)퀵 정렬은
11.카운팅 정렬/계수 정렬(Counting Sort)

카운팅 정렬은 수 많은 정렬 알고리즘 중 시간복잡도가 O(n)으로 엄청난 성능을 보여주는 알고리즘이다.
12.버블 정렬(Bubble Sort)
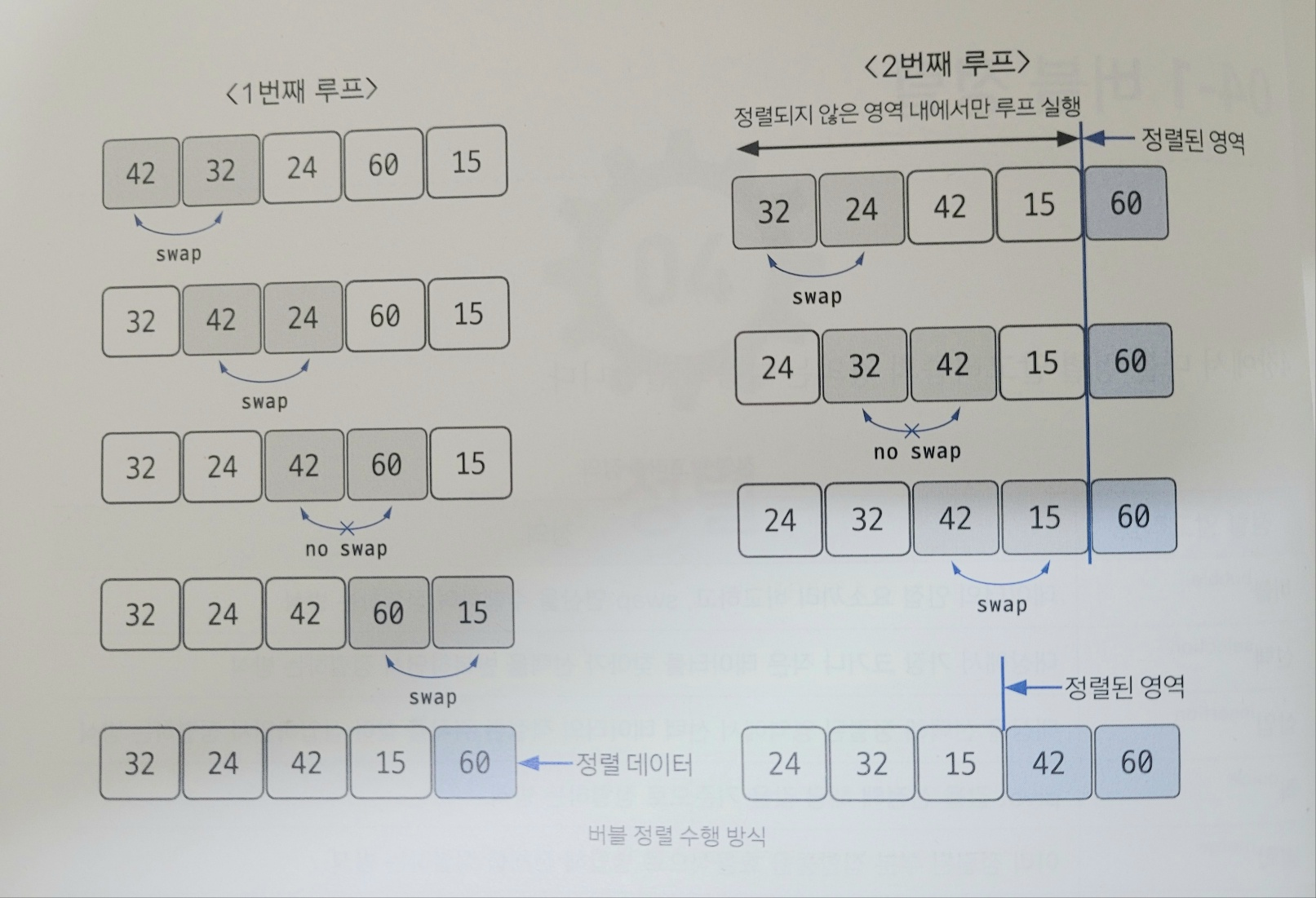
데이터의 인접 요소끼리 비교하고, swap 연산을 수행하며 정렬하는 방식<span style='background-color: 비교 연산이 필요한 루프 범위를 설정인접한 데이터 값을 비교swap 조건에 부합하면 swap 연산루프 범위가 끝날 때마다 2~3 반복정렬
13.선택 정렬(Selection Sort)
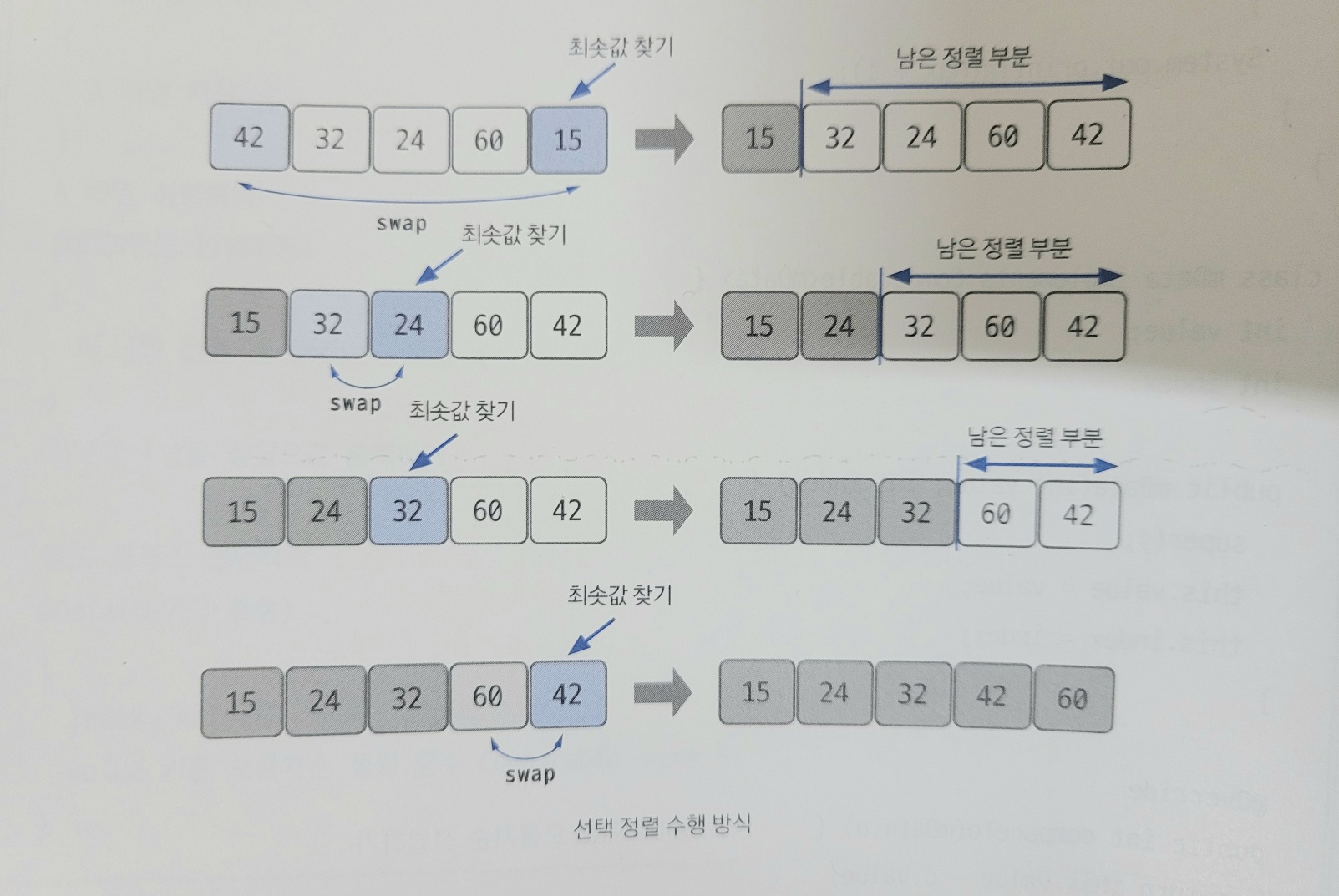
대상 데이터에서 최대나 최소 데이터를 데이터가 나열된 순으로 찾아가며 선택하는 방법<span style='background-color: 핵심 : 최솟값 또는 최댓값을 찾고, 남은 정렬 부분의 가장 앞에 있는 데이터와 swap하는 것남은 정렬 부분에서 최솟값 또는
14.삽입 정렬(Insertion Sort)
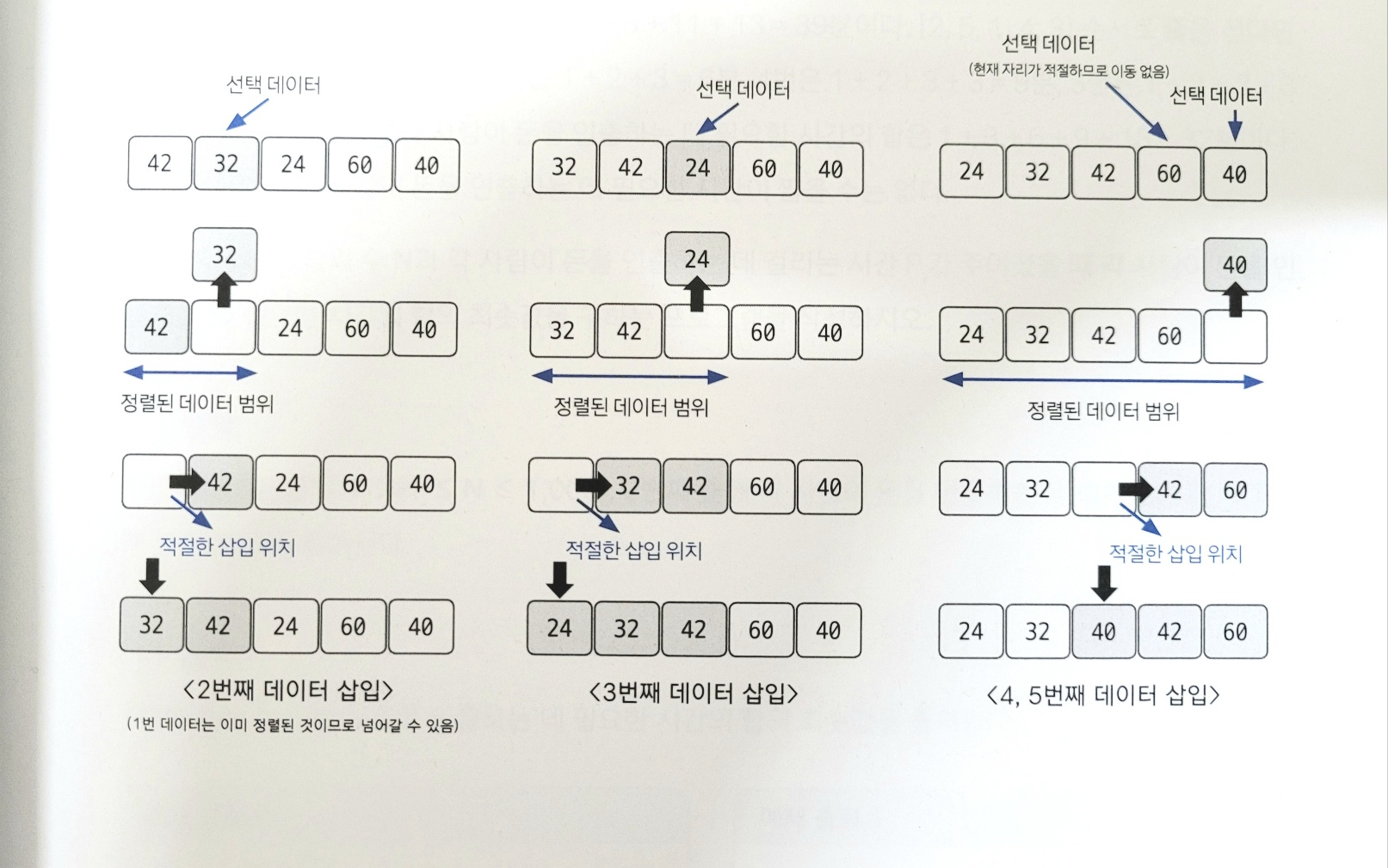
이미 정렬된 데이터 범위에 정렬되지 않은 데이터를 적절한 위치에 삽입시켜 정렬하는 방식<span style='background-color: 느린 편 + 구현이 쉬움핵심 : 선택 데이터를 현재 정렬된 데이터 범위 내에서 적절한 위치에 삽입하는 것현재 index에
15.병합 정렬(Merge Sort)
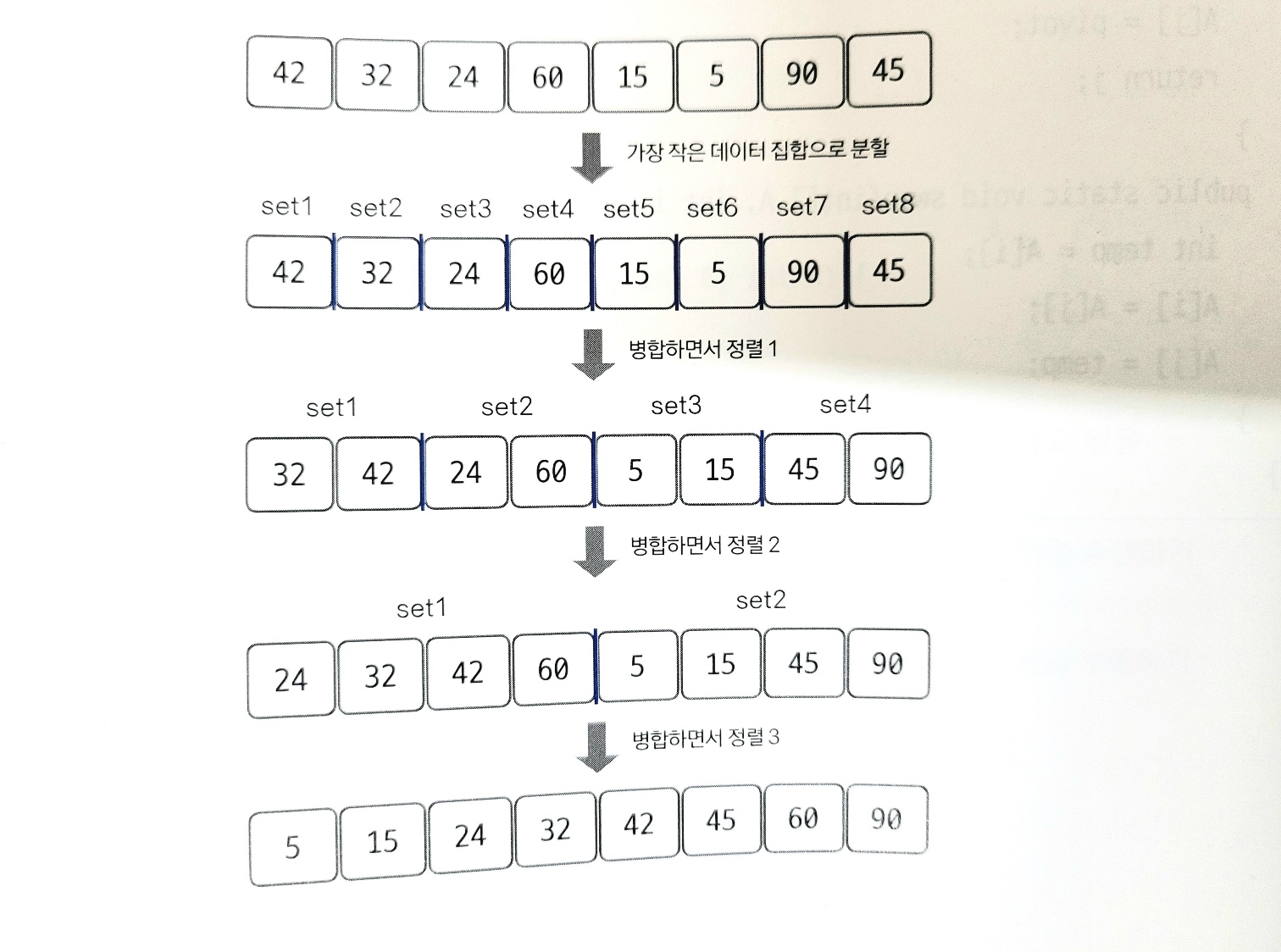
분할 정복 방식을 사용해 데이터를 분할하고 분할한 집합을 정렬하며 합치는 알고리즘<span style='background-color: 최초에는 가장 작은 그룹 단위로 그룹을 나눈다.이 상태에서 2개씩 그룹을 합치며 오름차순 정렬그룹의 크기가 전체 크기가 될 때까
16.기수 정렬(Radix Sort)

기수 정렬은 값을 비교하지 않는 특이한 정렬이다. 기수 정렬은 값을 놓고 비교할 자릿수를 정한 다음 해당 자릿수만 비교한다.<span style='background-color: 핵심 : 기수 정렬은 10개의 큐를 이용한다. 각 큐는 값의 자릿수를 대표한다.기수
17.깊이 우선 탐색(DFS)
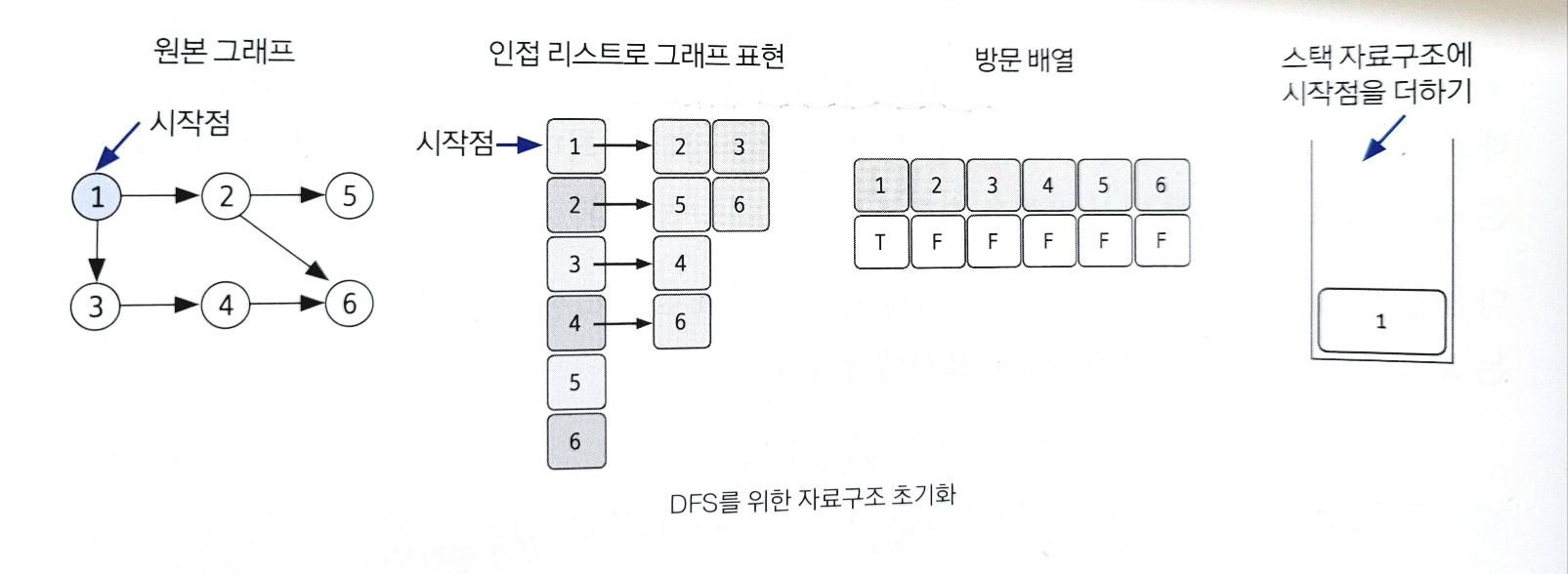
그래프 완전 탐색 기법 중 하나로, 그래프의 시작 노드에서 출발하여 탐색할 한 쪽 분기를 정하여 최대 깊이까지 탐색을 마친 후 다른 쪽 분기로 이동하여 다시 탐색을 수행하는 알고리즘이다.실제 구현 시 재귀 함수를 이용하므로 스택 오버플로에 유의해야 한다.핵심 이론노드
18.너비 우선 탐색(BFS)
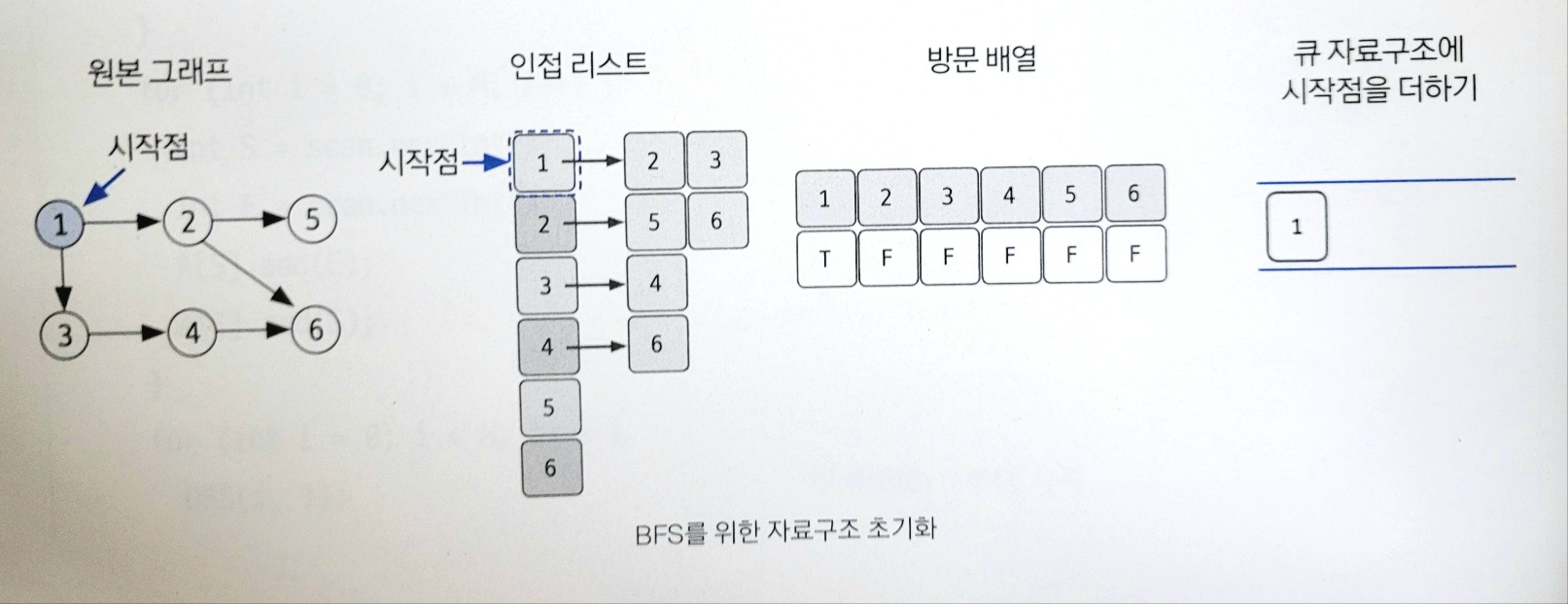
그래프를 완전 탐색하는 방법 중 하나로, 시작 노드에서 출발해 시작 노드를 기준으로 가까운 노드를 먼저 방문하면서 탐색하는 알고리즘이다.선입선출 방식으로 탐색하므로 큐를 이용해 구현한다. 또한 BFS는 탐색 시작 노드와 가까운 노드를 우선하여 탐색하므로 목표 노드에 도
19.이진 탐색(Binary Search)
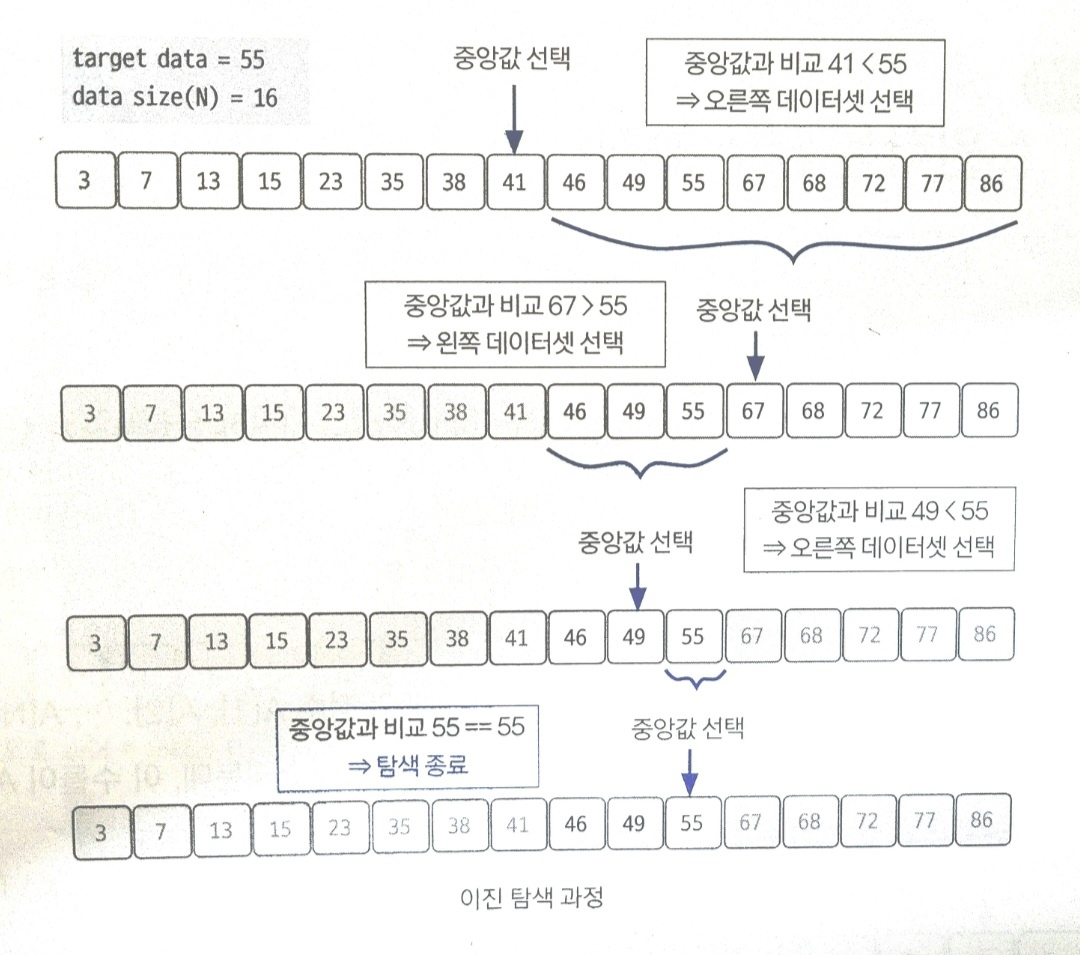
데이터가 정렬돼 있는 상태에서 원하는 값을 찾아내는 알고리즘이다. 대상 데이터의 중앙값과 찾고자 하는 값을 비교해 데이터의 크기를 절반씩 줄이면서 대상을 찾는다.<span style='background-color: 구현 및 원리가 비교적 간단하므로 많은 코딩 테
20.이분 그래프(Bipartite Graph)
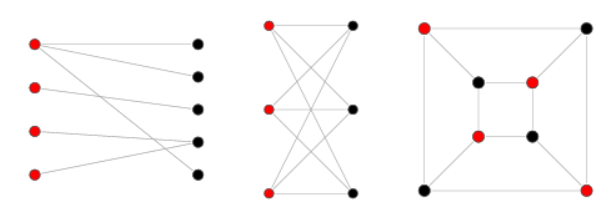
인접한 정점끼리 서로 다른 색으로 칠해서 모든 정점을 두 가지 색으로만 칠할 수 있는 그래프즉, 그래프의 모든 정점이 두 그룹으로 나눠지고 서로 다른 그룹의 정점이 간선으로 연결되어져 있는 그래프를 이분 그래프라고 한다.이분 그래프인지 확인하는 방법은 BFS, DFS