🌱 허프만 알고리즘
압축 단위마다 문자의 출현 빈도를 조사하여 빈도가 높은 순서대로 비트 수가 적은 부호를 부여함으로써 데이터를 압축하는 방식
간단히 말해서 많이 사용된 문자는 더 적은 비트로 나타내고 적게 사용된 문자는 더 많은 비트를 사용하여 효율적으로 문자열을 나타내는 방식
-
문자 압축 예시
AAAAAABBBBCDD
A(6) B(4) C(1) D(2) : 문자(개수)
가장 적은 사용 빈도를 가진 두 항을 묶고 그 합을 적어준다.
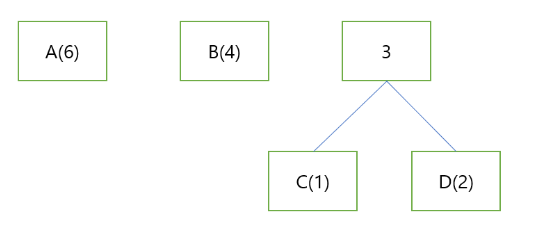
이와 같이 한번 더 묶는다.
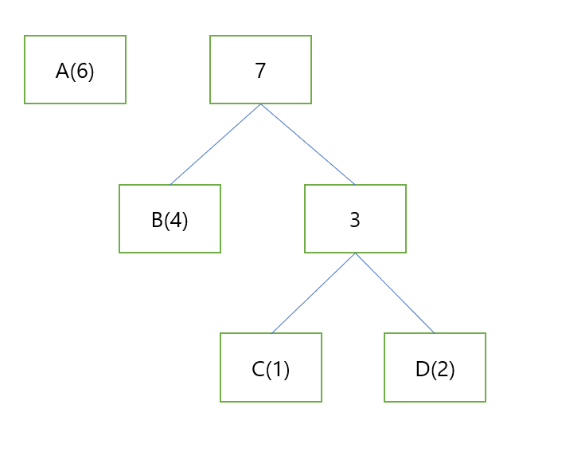
마지막 남은 A까지 묶어주면 다음과 같은 그림이 나온다.
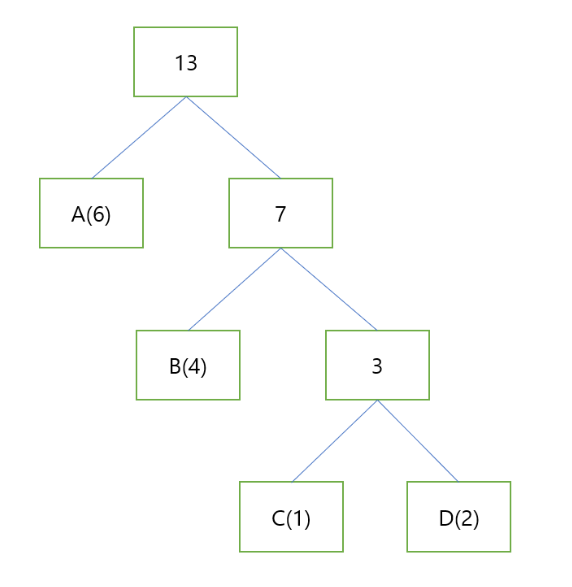
이제 루트 노드를 기준으로 왼쪽으로 한번 가면 0, 오른쪽으로 가면 1이라고 하겠다.
그럼 A는 0, B는 10, C는 110, D는 111로 나타낼 수 있다.
이를 사용하여 AAAAAABBBBCDD 를 나타내면 00000010101010110111111이 된다.
이와 같이 문자의 사용 빈도를 이용하여 문자열을 압축하는 알고리즘이 허프만 알고리즘이다.
-
정수 압축 예시
가장 용량이 적은 것부터 합쳐가면 최소 압축 용량을 만들 수 있다.
그리고 각 용량을 비교할 때, 이전에 합했던 값을 포함시켜야 최소 부분 용량을 얻을 수 있다.
ex)
sum : 60, {40, 50} -> 결과는 60+40 또는 60+50
sum : 60, {40, 50, 60} -> 결과는 40+50
핵심
크기든 빈도든 작은 것을 먼저 계산하여 비트를 크게 하고, 큰 것을 나중에 계산하여 비트를 작게 하자
Reference URL : https://dy-coding.tistory.com/entry/%EB%B0%B1%EC%A4%80-13975%EB%B2%88-%ED%8C%8C%EC%9D%BC-%ED%95%A9%EC%B9%98%EA%B8%B0-3-java
