썸넬 img ref :
https://coding-factory.tistory.com/554
🌱 Set
Set은 쉽게 말해서 집합이라고 보면 됩니다. 기본적으로 Set 혹은 Set 계열을 구현하는 클래스들은 다음과 같은 공통점이 있습니다.
- 중복되는 요소(원소)를 허용하지 않는다.
- 저장 순서를 유지하지 않는다. (LinkedHashSet 만 예외)
Set은 크게 HashSet, LinkedHashSet, TreeSet으로 나뉩니다.
🌿 HashSet
입력 순서를 보장하지 않고, 순서도 마찬가지로 보장되지 않습니다. 가장 쉽게 이해할 수 있는 예로 게임에서 닉네임을 만든다거나 아이디를 생성할 때 '중복확인'을 눌러 중복된 닉네임 또는 아이디인지 확인하는 것입니다. 이는 데이터가 정렬되어 있을 필요도 없고, 빠르게 중복되는 값인지만 찾으면 되기 때문에 유용한 방법이 될 수 있습니다.
좀 더 상세하게 말하자면 Hash에 의해 데이터의 위치를 특정시켜 해당 데이터를 빠르게 색인(search)할 수 있게 만든 것입니다. 즉, Hash 기능과 Set 컬렉션이 합쳐진 것이 HashSet입니다. 그렇기 때문에 삽입, 삭제, 색인이 매우 빠른 컬렉션 중 하나입니다.
참고로 타입이 다른 값은 동일한 객체로 간주하지 않습니다.
내부적으로 HashMap을 이용해서 만들어졌습니다. 이름대로 해싱을 이용해서 구현되었습니다.
🌿 LinkedHashSet
이름에서 볼 수 있듯이 Link + Hash + Set 이 결합된 형태입니다. LinkedList는 요소들을 넣은 순서대로 연결합니다. 즉, 첫 번째 요소부터 차례대로 출력하면 입력했던 순서대로 출력된다는 것이고 이는 순서를 보장한다는 의미입니다.
Set의 경우, 기본적으로 입력 순서대로의 저장순서를 보장하지 않아 '중복은 허용하지 않으면서 순서를 보장받고 싶은 경우'에 주로 사용됩니다. 예를 들면, 캐시에 이미 저장된 페이지를 다시 적재하지 않고 새로운 페이지를 할당하기 위해 최근에 사용되지 않은 가장 오래된 캐시를 비우고자 할 때, LRU 알고리즘을 사용합니다. 이 알고리즘은 입력된(저장된) 순서를 알아야 가장 오래된 데이터를 비울 수 있는데, 여기에 적용할 수 있는 자료구조 중 하나입니다.(실제로는 LinkedHashMap을 대부분 사용한다.)
🌿 TreeSet
입력 순서대로의 저장 순서를 보장하지 않으면서 중복 데이터를 허용하지 않습니다. 다만, 특별한 점이 있다면 SortedSet Interface를 구현한 TreeSet은 데이터의 '가중치에 따른 순서'대로 정렬되어 보장한다는 것입니다. 즉, '중복되지 않으면서 특정 규칙에 의해 정렬된 형태의 집합'을 쓰고 싶을 때 사용합니다. 정렬된 형태로 있다보니 특정 구간의 집합 요소들을 탐색할 때 매우 유용합니다.(Tree라는 자료구조 자체가 데이터를 일정 순서에 의해 정렬하는 구조입니다. 여기에 Set이 더해져 중복값을 방지한 자료구조입니다.)
트리는 데이터를 순차적으로 저장하는 것이 아니라 저장위치를 찾아서 저장해야하고, 삭제하는 경우 트리의 일부를 재구성해야하므로 연결리스트보다 데이터의 추가/삭제 시간은 더 걸립니다. 대신 배열이나 연결리스트에 비해 검색과 정렬기능이 더 뛰어납니다. (중복 원소 저장 x)
🌿 Set Interface
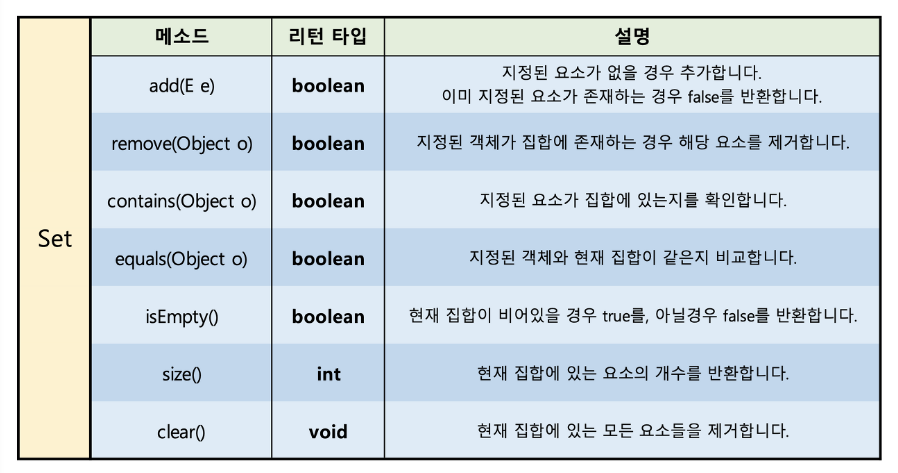
📌 메소드
📌 구현
코드package interface_form;
public interface SetInterface<E> {
/**
* 지정된 요소가 Set에 없는 경우 요소를 추가
*
* @param e 집합에 추가할 요소
* @return {@code true} 만약 Set에 지정 요소가 포함되지 않았을 경우 정상 추가
* else {@code false}
* */
boolean add(E e);
/**
* 지정된 요소가 Set에 있는 경우 해당 요소를 삭제
*
* @param o 집합에서 삭제할 특정 요소
* @return {@code true} 만약 Set에 지정 요소가 포함되었을 경우 정상 삭제
* else {@code false}
* */
boolean remove(Object o);
/**
* 현재 집합에 특정 요소가 포함되어있는지 여부를 반환
*
* @param o 집합에서 찾을 특정 요소
* @return {@code true} Set에 지정 요소가 포함되어 있을 경우
* else {@code false}
* */
boolean contains(Object o);
/**
* 지정된 객체가 현재 집합과 같은지 여부를 반환
*
* @param o 집합과 비교할 객체
* @return {@code true} 비교할 집합과 동일한 경우
* else {@code false}
* */
boolean equals(Object o);
/**
* 현재 집합이 빈 상태(요소가 없는 상태)인지 여부를 반환
*
* @return {@code true} 집합이 비어있는 경우
* else {@code false}
* */
boolean isEmpty();
/**
* 현재 집합의 요소의 개수를 반환
* 만약 존재하는 요소가 {@code Integer.MAX_VALUE}를 넘을 경우 {@code Integer.MAX_VALUE} 반환
*
* @return 집합에 들어있는 요소의 개수를 반환
* */
int size();
/*
* 집합의 모든 요소를 제거
* 이 작업을 수행하면 비어있는 집합이 됨
* */
void clear();
}
🌿 HashSet 구현
Separate Chaining 기반으로 구현

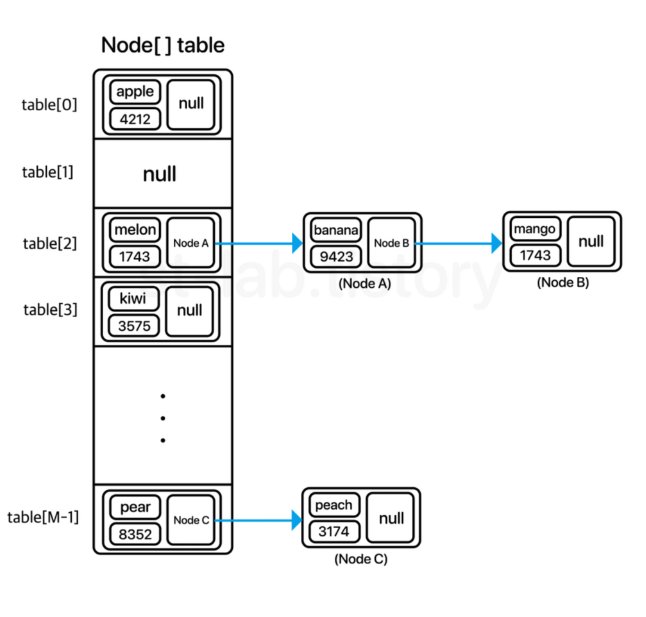
📌 Node 구현
package set;
public class Node<E> {
/*
* hash와 key 값은 변하지 않으므로
* final로 선언
* */
final int hash;
final E key;
Node<E> next;
public Node(int hash, E key, Node<E> next) {
this.hash = hash;
this.key = key;
this.next = next;
}
}
📌 구현
코드package set.hashSet;
import interface_form.SetInterface;
import java.util.Arrays;
public class HashSet<E> implements SetInterface<E> {
//최소 기본 용적이며 2^n 꼴 형태가 좋음
private final static int DEFAULT_CAPACITY = 1 << 4; //Node 배열의 기본 및 최소 용적(16)
// 3 / 4이상 채워질 경우 resize
private final static float LOAD_FACTOR = 0.75f;
Node<E>[] table; //해시 테이블(요소 정보 저장)
private int size; //요소의 개수
@SuppressWarnings("unchecked")
public HashSet() {
table = (Node<E>[]) new Node[DEFAULT_CAPACITY];
size = 0;
}
//보조 해시 함수 (상속 방지를 위해 private static final 선언)
private static final int hash(Object key) {
int hash;
if (key == null) {
return 0;
} else {
//hashCode()의 경우 음수가 나올 수 있으므로 절댓값을 통해 양수로 변환
return Math.abs(hash = key.hashCode()) ^ (hash >>> 16);
}
}
@SuppressWarnings("unchecked")
private void resize() {
int newCapacity = table.length * 2;
//기존 테이블의 2배 용적으로 생성
final Node<E>[] newTable = (Node<E>[]) new Node[newCapacity];
//0번째 index부터 차례대로 출력
for (int i = 0; i < table.length; i++) {
//각 인덱스의 첫 번째 노드(head)
Node<E> value = table[i]; //value는 link를 타고 노드를 순회
//해당 값이 없을 경우 다음으로
if (value == null) {
continue;
}
table[i] = null; //gc
Node<E> nextNode; //현재 노드의 다음 노드
//현재 인덱스에 연결된 노드들을 순회
while (value != null) {
int idx = value.hash % newCapacity; //새로운 index
/*
* 새로 담을 index에 요소(노드)가 존재하는 경우
* == 새로 담을 newTable에 index값이 겹칠 경우 (해시 충돌)
* */
if (newTable[idx] != null) {
Node<E> tail = newTable[idx];
//가장 마지막 노드로 이동
while (tail.next != null) {
tail = tail.next;
}
/*
* 반드시 value가 참조하고 있는 다음 노드와의 연결을 끊어주어야 함
* 안하면 각 인덱스의 마지막 노드(tail)도 다른 노드를 참조하게 되어
* 잘못된 참조가 발생할 수 있음
* */
nextNode = value.next; //value 갱신용
value.next = null; //링크 제거
tail.next = value; //새 테이블의 해당 인덱스에 링크 연결
}
//충돌되지 않는다면(=빈 공간이라면 해당 노드 추가)
else {
/*
* 반드시 value가 참조하고 있는 다음 노드와의 연결을 끊어주어야 함
* 안하면 각 인덱스의 마지막 노드(tail)도 다른 노드를 참조하게 되어
* 잘못된 참조가 발생할 수 있음
* */
nextNode = value.next; //value 갱신용
value.next = null; //링크 제거
newTable[idx] = value; //새 테이블에 삽입
}
value = nextNode; //다음 노드로 이동(value 갱신)
}
}
table = null; //table gc 처리
table = newTable; //table 교체
}
@Override
public boolean add(E e) {
//key(e)에 대해 만들어두었던 보조해시함수의 값과 key(데이터 e)를 보냄
return add(hash(e), e) == null;
}
private E add(int hash, E key) {
int idx = hash % table.length;
//table[idx]가 비어있을 경우 새 노드 생성
if (table[idx] == null) {
table[idx] = new Node<E>(hash, key, null);
}
/*
* table[idx]에 요소가 이미 존재할 경우(==해시 충돌)
*
* 두 가지 경우의 수
* 1. 객체가 같은 경우
* 2. 객체는 같지 않으나 얻어진 index가 같은 경우
* */
else {
Node<E> temp = table[idx]; //현재 위치 노드
Node<E> prev = null; //temp의 이전 노드
//첫 노드(table[idx])부터 탐색
while (temp != null) {
/*
* 만약 현재 노드의 객체가 같은 경우(hash값이 같으면서 key가 같을 경우)는
* HashSet은 중복을 허용하지 않으므로 key를 반납(반환)
* Key가 같은 경우는 주소가 같거나 객체가 같은 경우가 존재
* */
if ((temp.hash == hash) && (temp.key == key || temp.key.equals(key))) {
return key;
}
prev = temp;
temp = temp.next;
}
//마지막 노드에 새 노드 연결
prev.next = new Node<E>(hash, key, null);
}
size++;
//데이터의 개수가 현재 table 용적의 75%를 넘어가는 경우 용적 늘림
if (size >= LOAD_FACTOR * table.length) {
resize();
}
return null; //정상 추가되었을 경우
}
@Override
public boolean remove(Object o) {
//null이 아니라는 것은 노드가 정상 삭제되었다는 의미
return remove(hash(o), o) != null;
}
private Object remove(int hash, Object key) {
int idx = hash % table.length;
Node<E> node = table[idx]; //indx의 head 노드
Node<E> removedNode = null; //삭제 대상 노드를 담을 변수
Node<E> prev = null; //이전 노드를 담을 변수
//삭제할 노드가 없음
if (node == null) {
return null;
}
//삭제할 노드 탐색
while (node != null) {
//같은 노드를 찾았다면
if (node.hash == hash && (node.key == key || node.key.equals(key))) {
removedNode = node; //삭제되는 노드를 반환하기 위한 변수
//해당 노드의 이전 노드가 존재하지 않는 경우(head 노드인 경우)
if (prev == null) {
table[idx] = node.next; //head의 다음 노드가 head가 됨
} else {
prev.next = node.next; //삭제 노드 기준, 앞 뒤 노드 연결
node = null; //노드 삭제
}
size--;
break; //탐색 종료
}
//탐색 실패 후 다음 노드로 이동
prev = node;
node = node.next;
}
return removedNode;
}
@Override
public boolean contains(Object o) {
int idx = hash(o) % table.length;
Node<E> temp = table[idx];
/*
* 같은 객체 내용이어도 hash값은 다를 수 있음
* 하지만, 내용이 같은지를 알아보고 싶을 때 쓰는 메소드이기에
* hash값은 따로 비교 안해주어도 큰 지장 없음
* 단, o가 null인지는 확인해야 함
* */
while (temp != null) {
//같은 객체를 찾앗을 경우
if ((o == temp.key) || (o != null && o.equals(temp.key))) {
return true;
}
temp = temp.next;
}
return false;
}
@Override
public boolean isEmpty() {
return size == 0;
}
@Override
public int size() {
return size;
}
@Override
public void clear() {
if (table != null && size > 0) {
for (int i = 0; i < table.length; i++) {
table[i] = null;
}
size = 0;
}
}
@SuppressWarnings("unchecked")
@Override
public boolean equals(Object obj) {
//만약 파라미터 객체가 현재 객체와 동일한 객체라면
if (obj == this) {
return true;
}
//만약 obj 객체가 HashSet이 아닌 경우
if (!(obj instanceof HashSet)) {
return false;
}
HashSet<E> oSet;
/*
* Object로부터 HashSet<E>로 캐스팅되어야 비교 가능
* 만약 캐스팅이 불가능할 경우 ClassCastException 발생
* 이 경우 false를 return
* */
try {
//HashSet 타입으로 캐스팅
oSet = (HashSet<E>) obj;
//사이즈(요소 개수)가 다르다는 것은 명백히 다른 개체
if (oSet.size() != size) {
return false;
}
//HashSet의 각 index 검사
for (int i = 0; i < oSet.table.length; i++) {
Node<E> oTable = oSet.table[i];
//각 index(연결리스트)의 구성 요소 일치 확인
while (oTable != null) {
/*
* 서로 Capacity가 다를 수 있기 때문에 index에 연결된 원소들을
* 비교하는 것이 아닌 contains로 원소의 존재 여부를 확인해야 함
* */
if (!contains(oTable)) {
return false; //하나라도 존재하지 않으면 다른 객체이므로 false
}
oTable = oTable.next;
}
}
} catch (ClassCastException e) {
return false;
}
//위 검사가 모두 완료되면 같은 객체임이 증명됨
return true;
}
public Object[] toArray() {
if (table == null) {
return null;
}
Object[] ret = new Object[size];
int index = 0;
for (int i = 0; i < table.length; i++) {
Node<E> node = table[i];
//해당 인덱스에 연결된 모든 노드를 하나씩 담음
while (node != null) {
ret[index] = node.key;
index++;
node = node.next;
}
}
return ret;
}
@SuppressWarnings("unchecked")
public <T> T[] toArray(T[] a) {
Object[] copy = toArray(); //toArray() 통해 먼저 배열을 얻음
//들어온 배열이 copy된 요소 개수보다 작을 경우 size에 맞게 늘려주면서 복사
if (a.length < size) {
return (T[]) Arrays.copyOf(copy, size, a.getClass());
}
//그 외에는 copy배열을 a에 0번째부터 채움
System.arraycopy(copy, 0, a, 0, size);
return a;
}
}
📌 테스트 및 설명
코드package set.hashSet;
public class HashSetApplication {
public static void main(String[] args) {
Custom a = new Custom("aaa", 10);
Custom b = new Custom("aaa", 10);
HashSet<Custom> set = new HashSet<>();
set.add(a);
if (set.add(b)) {
System.out.println("hashset에 b객체가 추가됨");
} else {
System.out.println("중복원소!");
}
}
static class Custom {
String str;
int val;
public Custom(String str, int val) {
this.str = str;
this.val = val;
}
@Override
public boolean equals(Object obj) {
if ((obj instanceof Custom) && obj != null) {
//주소가 같은 경우
if (obj == this) {
return true;
}
Custom other = (Custom) obj;
//str이 null인 경우 객체 비교 불가
if (str == null) {
//둘 다 str이 null이면 val 비교
if (other.str == null) {
return other.val == val;
}
return false;
}
//str과 val 내용 동일
if (other.str.equals(str) && other.val == val) {
return true;
}
}
return false;
}
@Override
public int hashCode() {
final int prime = 31; //소수
int result = 17;
/*
* 연산 과정 자체는 어떻게 해주어도 무방하지만
* 최대한 중복되지 않도록
* */
result = prime * result * val;
result = prime * result + (str != null ? str.hashCode() : 0);
return result;
}
}
}
보조 해시 함수 hash()
최대한 해시 충돌을 피하기 위해 보조해시함수를 사용하여 고른 분포를 할 수 있도록 하기 위한 함수입니다. 여기서는 Java 11의 구현과 유사하게 key의 hashCode의 절댓값과 그 값을 16비트 오른쪽으로 밀어낸 값하고의 XOR 값을 반환하도록 했습니다.
생성자
사용자 용적 설정 생성자가 없습니다. HashSet의 용적을 2^n 꼴로 두는 것이 매우 편리하고 좋기 때문입니다. 또한, 사용자가 해시 충돌을 예측하기 어렵고, 해시 충돌이 발생하더라도 Separate Chaining 방식으로 연결되기 때문에 굳이 사용자에게 용적을 설정하게 둘 필요는 없습니다.
상속 방지
기능적으로는 private는 접근 제한자고, final은 변수의 참조를 다시 할 수 없도록 하는 기능입니다. 이는 불필요한 변경 같은 불상사를 막고, JIT 컴파일러가 최적화를 할 때도 단 한번의 참조만 이루어진다는 키워드를 붙여줌으로써 힌트를 부여해 컴파일러가 성능 최적화를 이룰 수 있게 만듭니다. 또한, static은 Compile Time에 메모리에 올라가기 때문에 클래스 종속적이며 객체 생성 전에 이미 메모리에 있으므로 상속이 불가합니다.
add()
위 코드에서는 equals() 수준에서만 비교했지만, 좀 더 정확하게 하려면 hash 값이 같은지 그리고 주소값 또는 key 객체 내용이 같은지도 만족해야 추가할 수 있도록 하는 것이 좀 더 정확하게 만들 수 있습니다.
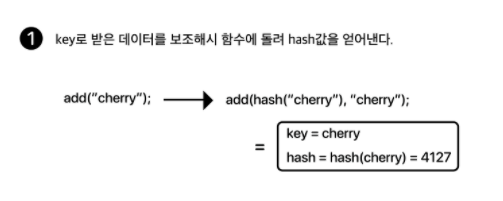
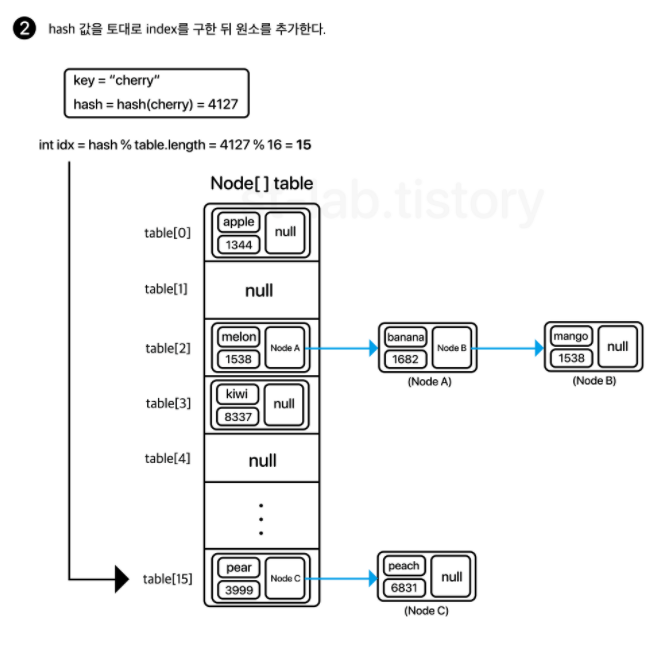
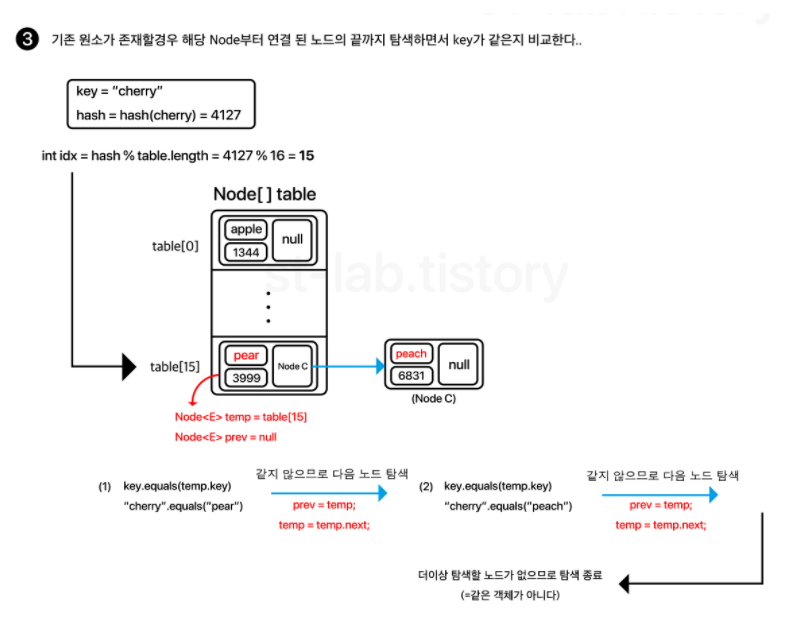
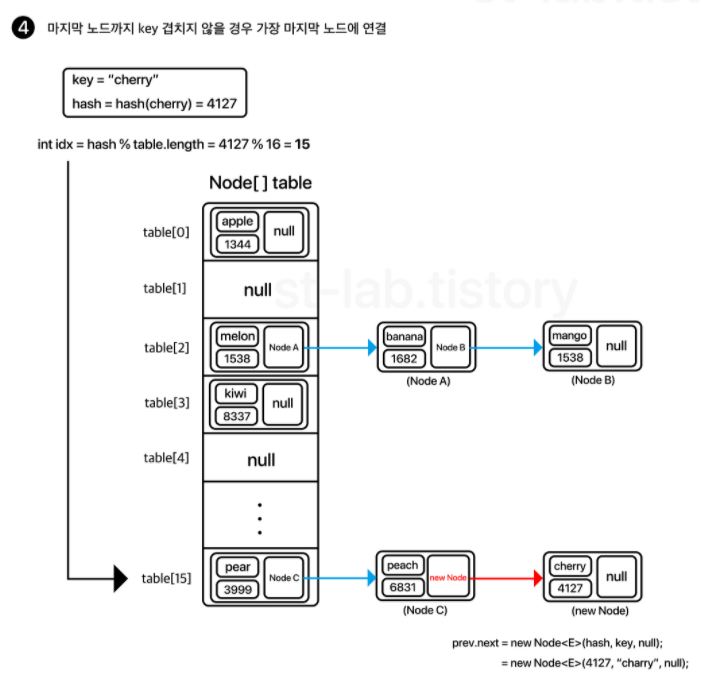
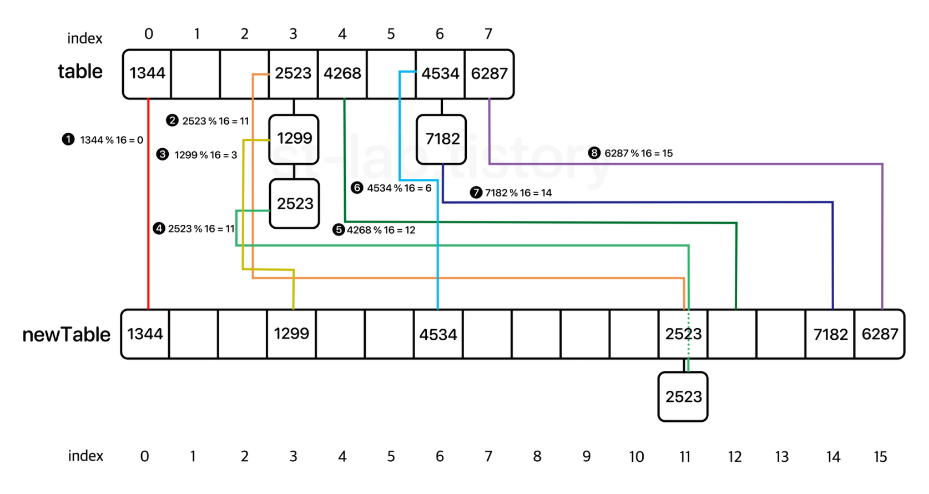
resize()
기본적으로 현재 용적의 두 배로 늘려주면 됩니다.
일단 Node 배열을 하나 새로 생성해두고, 기존 테이블에 있는 모든 요소들을 탐색하면서 각 노드의 hash값을 이용하여 새로 만든 배열의 길이로 나눈 나머지를 구해 재배치를 해주는 것입니다.
각 인덱스별로 순회하되, 해당 인덱스의 연결된 노드를 우선적으로 탐색하면서 재배치합니다.
또한, value.next를 미리 제거한 후 노드를 삽입합니다. 그 이유는 해당 링크로 연결된 노드가 그대로 딸려올 수 있기 때문입니다.
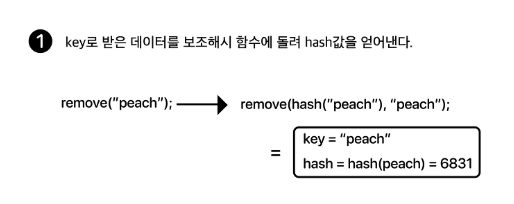
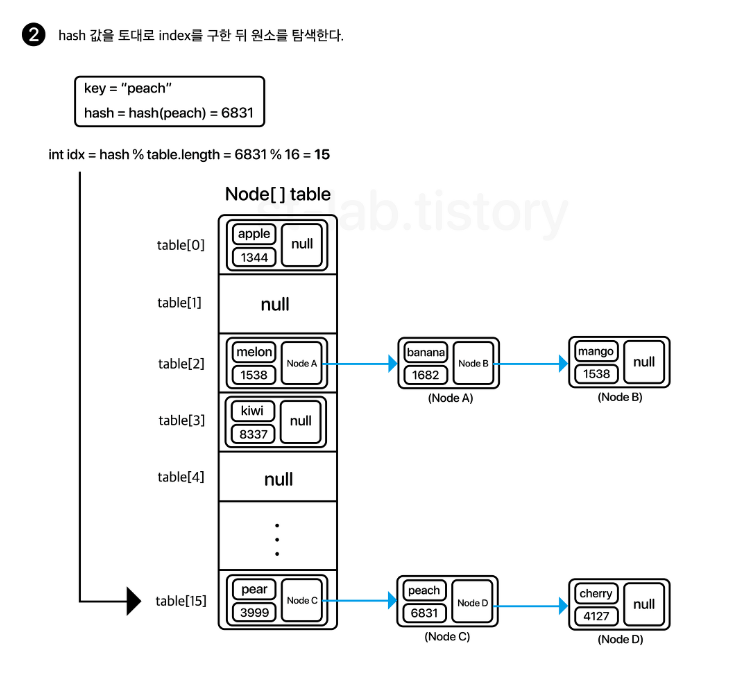
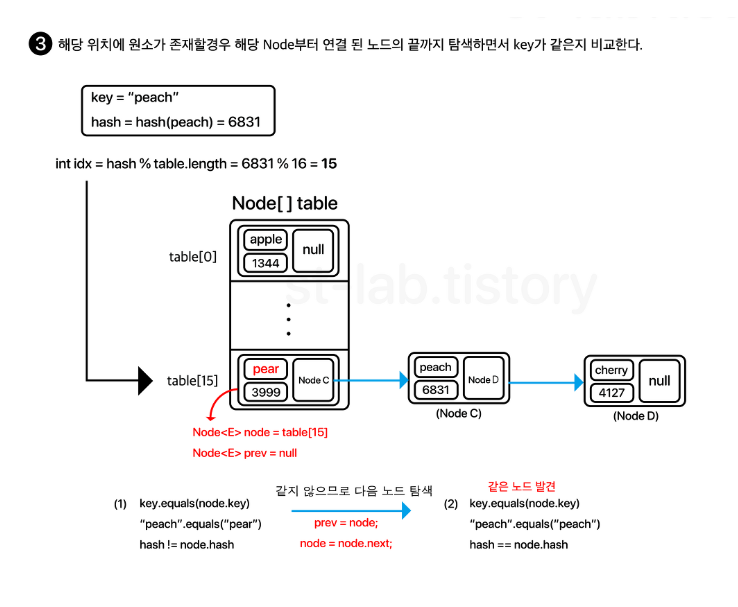
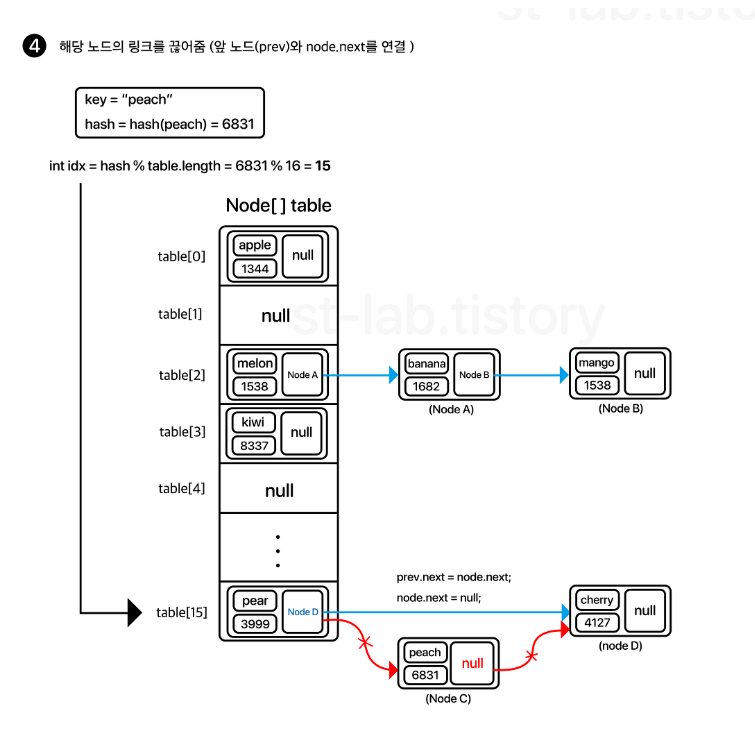
remove()
toArray()
toArray 관련 내용 - 우선순위 큐 부분
테스트 시, 반드시 hashCode와 equals()를 재정의(override)해야 합니다. 그렇지 않으면 같은 내용을 담고 있을지라도 new로 생성된 객체들은 모두 서로 다른 객체로 hashCode()가 달리 나오기 때문입니다.
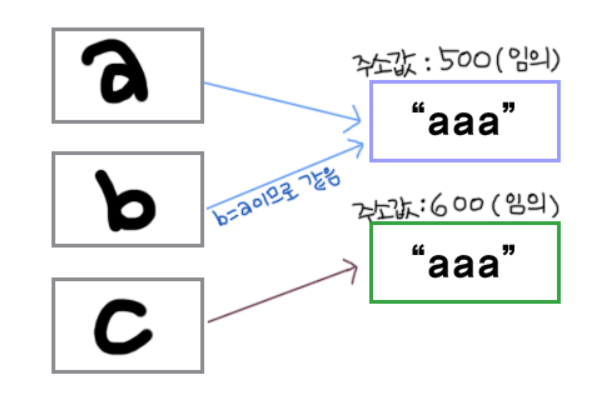
🔎 '=='과 equals() 차이
'==' : 객체의 주소를 비교
equals() : 객체의 내용을 비교