썸넬 img ref :
https://onlyfor-me-blog.tistory.com/348
🌱 Map
키와 값을 하나의 쌍으로 묶어서 저장하는 컬렉션 클래스로 키는 중복될 수 없지만 값은 중복을 허용합니다. 기존에 저장된 데이터와 중복된 키와 값을 저장하면 기존의 값은 없어지고 저장된 값이 남게 됩니다.
🌿 Map 메서드
📌 Map.Entry 인터페이스
Map 인터페이스의 내부 인터페이스입니다. Map에 저장되는 key-value 쌍을 다루기 위해 내부적으로 Entry 인터페이스를 정의해놓았습니다. 이것은 보다 객체지향적으로 설계하도록 유도하기 위한 것으로 Map 인터페이스를 구현하는 클래스에서는 Map.Entry 인터페이스도 함께 구현해야 합니다.
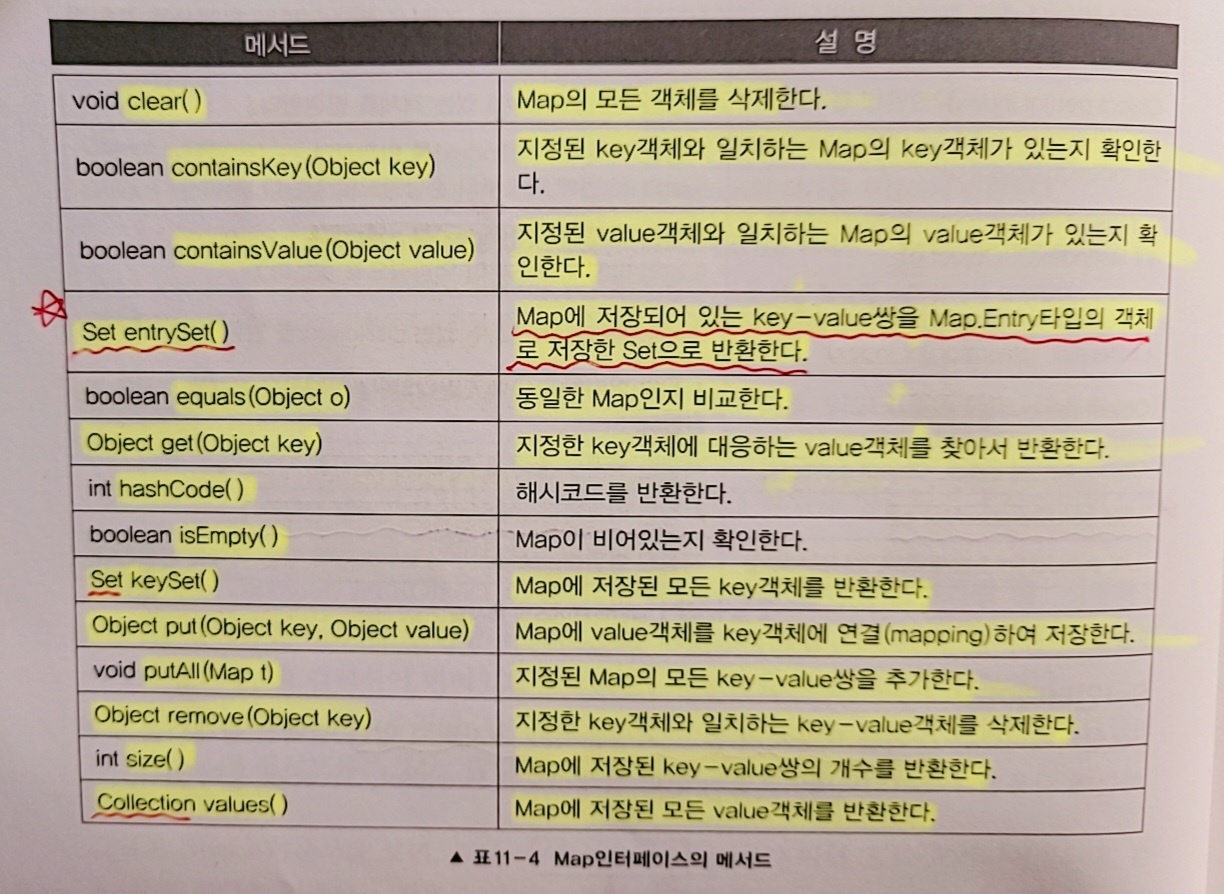
| 메서드 | 설명 |
|---|---|
| boolean equals(Object o) | 동일한 Entry인지 비교 |
| K getKey() | Entry의 Key 객체를 반환 |
| V getValue() | Entry의 Value 객체를 반환 |
| int hashCode() | Entry의 해시코드를 반환 |
| V setValue(V value) | Entry의 value 객체를 지정된 객체로 변경 |
🔎 Map 의 Iterator 얻는 방법
Map 인터페이스를 구현한 컬렉션 클래스는 key와 value 쌍으로 저장하고 있기 대문에 iterator()를 직접 호출할 수 없고, 그 대신 keySet()이나 entrySet()과 같은 메소드를 통해서 키와 값을 각각 따로 Set의 형태로 얻어 온 후에 다시 iterator()를 호출해야 Iterator를 얻을 수 있습니다.
Map map = new HashMap();
...
Iterator it = map.entrySet().iterator();📌 Map.get
key에 대한 value를 리턴하며, null 값인 경우 NPE 발생함
📌 Map.getOrDefault
getOrDefault(key, default) -> NPE 발생 안함
key에 대한 value를 리턴하며, key가 존재하지 않을 경우 default를 리턴
public class UpdateValueOfHashMap3 {
public static void main(String[] args) {
Map<String, Integer> map = new HashMap<>();
map.put("apple", 1);
map.put("melon", 2);
map.put("kiwi", 3);
map.put("melon", map.getOrDefault("melon", 0) + 10);
map.put("banana", map.getOrDefault("banana", 0) + 10);
System.out.println("Result: " + map);
}
}ref : https://codechacha.com/ko/java-how-to-update-value-of-key-from-hashmap/#5-getordefault
📌 Map.compute
key가 존재하는 경우에만 value를 증가시키도록 함 (NPE 발생 안함)
public class UpdateValueOfHashMap4 {
public static void main(String[] args) {
Map<String, Integer> map = new HashMap<>();
map.put("apple", 1);
map.put("melon", 2);
map.put("kiwi", 3);
map.compute("apple", (k, v) -> (v == null) ? 1 : v + 20);
map.compute("banana", (k, v) -> (v == null) ? 1 : v + 1);
System.out.println("Result: " + map);
}
}
//결과
Result: {banana=1, apple=21, kiwi=3, melon=2}ref : https://codechacha.com/ko/java-how-to-update-value-of-key-from-hashmap/#5-getordefault
📌 Map.putIfAbsent
map.putIfAbsent(K key, V value)
key에 대한 value를 반환하며, key가 존재하지 않는 경우 key와 value를 Map에 저장하고 null 반환
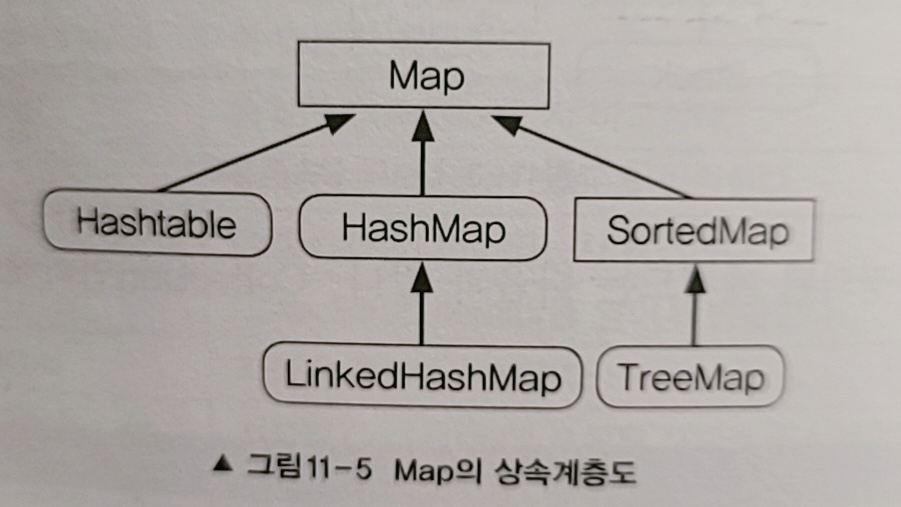
🌿 HashMap
Hashtable보다는 새로운 버전인 HashMap을 사용할 것을 권장
Map을 구현했으므로 key, value 쌍을 하나의 데이터(entry)로 저장하고, 해싱을 사용하기 때문에 많은 양의 데이터를 검색하는데 있어서 뛰어난 성능을 보입니다.
key : 컬렉션 내의 키 중에서 유일해야 함(null 허용)
value : 중복 허용(null 허용)
🔎 hashCode()
HashMap과 같이 해싱을 구현한 컬렉션 클래스에서는 Object 클래스에 정의된 hashCode()를 해시함수로 사용합니다. Object 클래스에 정의된 hashCode()는 객체의 주소를 이용하는 알고리즘으로 해시코드를 만들어 내기 때문에 모든 객체에 대해 hashCode()를 호출한 결과가 서로 유일한 훌륭한 방법입니다.
🌿 TreeMap
이진검색트리의 형태로 키와 값의 쌍으로 이루어진 데이터를 저장한다. TreeMap에 객체를 저장하면 자동으로 정렬되는데, 키는 저장과 동시에 자동 오름차순으로 정렬되고 숫자 타입일 경우에는 값으로, 문자열 타입일 경우에는 유니코드로 정렬한다.
정렬 순서는 기본적으로 부모 키 값과 비교해서 키 값이 낮은 것은 왼쪽 자식 노드에 키 값이 높은 것은 오른쪽 자식 노드에 Map.Entry 객체를 저장한다.
일반적으로 검색에 관한한 대부분의 경우에서 HashMap이 TreeMap보다 더 뛰어나므로 HashMap을 사용하는 것이 좋다. 다만 범위검색이나 정렬이 필요한 경우에는 TreeMap을 사용하는 것이 효율성 면에서 좋다.
ref :
https://coding-factory.tistory.com/557
자바의 정석
📌 레드-블랙 트리(Red-Black Tree)

TreeMap은 이진탐색트리의 문제점을 보완한 레드-블랙 트리(Red-Black Tree)로 이루어져 있다. 일반적인 이진 탐색 트리는 트리의 높이만큼 시간이 필요하다. 값이 전체 트리에 잘 분산되어 있다면 효율성에 있어 크게 문제가 없으나 데이터가 편향되어 들어올 경우 한쪽으로 크게 치우쳐진 트리가 되어 굉장히 비효율적인 성능을 보인다. 이 문제를 보완하기 위해 레드-블랙 트리는 부모 노드보다 작은 값을 가지는 노드는 왼쪽 자식으로, 큰 값을 가지는 노드는 오른쪽 자식으로 배치하여 데이터의 추가나 삭제 시 트리가 한쪽으로 치우쳐지지 않도록 균형을 맞춘다.
📌 메서드
- TreeMap 값 추가
TreeMap<Integer,String> map = new TreeMap<Integer,String>();//TreeMap생성
map.put(1, "사과");//값 추가
map.put(2, "복숭아");
map.put(3, "수박");- TreeMap 값 삭제
map.remove(1); //key값 1 제거
map.clear(); //모든 값 제거- TreeMap 단일 값 출력
System.out.println(map); //전체 출력 : {1=사과, 2=복숭아, 3=수박}
System.out.println(map.get(1));//key값 1의 value얻기 : 사과
System.out.println(map.firstEntry());//최소 Entry 출력 : 1=사과
System.out.println(map.firstKey());//최소 Key 출력 : 1
System.out.println(map.lastEntry());//최대 Entry 출력: 3=수박
System.out.println(map.lastKey());//최대 Key 출력 : 3- Value 연산
public class Main {
public static vodi main(String[] args) throws Exception {
TreeMap<Character, Integer> map = new TreeMap<>();
String alphabets = "sadadwcqwdbvcicbkwaaazcsw";
char[] inputs = alphabets.toCharArray();
for(char input : inputs) map.merge(input, 1, Integer::sum);
}
}각 알파벳의 개수 카운팅
Integer::sum 을 통해 해당 key가 존재하는 경우 1을 더해준다.
만약 해당 key가 존재하지 않는다면 1로 초기화한다.
key에 대한 다수의 value를 결합할 때 사용
🌿 LinkedHashMap
연결 리스트로 저장되는 맵으로 Map에 입력한 순서가 보장되는 클래스
🌱 HashMap 정렬
🌿 List 이용
📌 Key로 정렬(Sort by Key)
리스트는 순서가 있는 자료형이므로 리스트를 이용하여 map을 정렬할 수 있음
public class Example {
public static void main(String[] args) {
Map<String, String> map = new HashMap<>();
map.put("Nepal", "Kathmandu");
map.put("United States", "Washington");
map.put("India", "New Delhi");
map.put("England", "London");
map.put("Australia", "Canberra");
List<String> keyList = new ArrayList<>(map.keySet());
//오름차순
keyList.sort((s1, s2) -> s1.compareTo(s2));
//keyList.sort(String::compareTo) 대체 가능
for (String key : keyList) {
System.out.println("key: " + key + ", value: " + map.get(key));
}
}
}
//결과
key: Australia, value: Canberra
key: England, value: London
key: India, value: New Delhi
key: Nepal, value: Kathmandu
key: United States, value: Washington📌 Value로 정렬(Sort by Value)
public class Example {
public static void main(String[] args) {
Map<String, String> map = new HashMap<>();
map.put("Nepal", "Kathmandu");
map.put("United States", "Washington");
map.put("India", "New Delhi");
map.put("England", "London");
map.put("Australia", "Canberra");
List<String> valueList = new ArrayList<>(map.values());
//오름차순
valueList.sort(String::compareTo);
for (String value : valueList) {
System.out.println("Value: " + value);
}
}
}
//결과
Value: Canberra
Value: Kathmandu
Value: London
Value: New Delhi
Value: Washington🌿 TreeMap 이용
TreeMap은 객체를 생성할 때 인자로 Comparator를 전달할 수 있으며, 요소를 추가할 때 Comparator를 사용하여 key를 정렬하며 그 순서대로 저장된다. 즉, 데이터를 가져올 때 이미 정렬된 순서대로 리턴이 되어 다시 정렬할 필요는 없다.
아래 예제는 Comparator는 key를 오름차순으로 정렬하도록 하였고, 이것을 TreeMap 생성자의 인자로 전달하여 객체를 생성함
public class Example {
public static void main(String[] args) {
Comparator<String> comparator = (s1, s2) -> s1.compareTo(s2);
Map<String, String> map = new TreeMap<>(comparator);
map.put("Nepal", "Kathmandu");
map.put("United States", "Washington");
map.put("India", "New Delhi");
map.put("England", "London");
map.put("Australia", "Canberra");
for (Map.Entry<String, String> entry : map.entrySet()) {
System.out.println("Key: " + entry.getKey() + ", "
+ "Value: " + entry.getValue());
}
}
}
//결과
Key: Australia, Value: Canberra
Key: England, Value: London
Key: India, Value: New Delhi
Key: Nepal, Value: Kathmandu
Key: United States, Value: WashingtonTreeMap은 value를 정렬하지는 않기 때문에 key를 정렬하는 경우에만 사용하면 된다.
🌿 Stream 이용
sorted(Map.Entry.comparingByKey()) 또는 sorted(Map.Entry.comparingByValue()) 이용하여 key 또는 value 기준 정렬
public class Example {
public static void main(String[] args) {
Map<String, String> map = new HashMap<>();
map.put("Nepal", "Kathmandu");
map.put("United States", "Washington");
map.put("India", "New Delhi");
map.put("England", "London");
map.put("Australia", "Canberra");
// sort by key
List<Map.Entry<String, String>> entries =
map.entrySet().stream()
.sorted(Map.Entry.comparingByKey())
.collect(Collectors.toList());
for (Map.Entry<String, String> entry : entries) {
System.out.println("Key: " + entry.getKey() + ", "
+ "Value: " + entry.getValue());
}
// sort by value
System.out.println();
entries = map.entrySet().stream()
.sorted(Map.Entry.comparingByValue())
.collect(Collectors.toList());
for (Map.Entry<String, String> entry : entries) {
System.out.println("Key: " + entry.getKey() + ", "
+ "Value: " + entry.getValue());
}
}
}
//결과
Key: Australia, Value: Canberra
Key: England, Value: London
Key: India, Value: New Delhi
Key: Nepal, Value: Kathmandu
Key: United States, Value: Washington
Key: Australia, Value: Canberra
Key: Nepal, Value: Kathmandu
Key: England, Value: London
Key: India, Value: New Delhi
Key: United States, Value: Washington🌿 LinkedHashMap 이용
LinkedHashMap 특성을 이용하여 입력 순서대로 데이터를 다시 꺼내도록 한다. 만약 Map을 사용하고 있는데, 입력한 순서대로 Map에 저장되길 원한다면 LinkedHashMap를 사용할 수 있다.
HashMap의 key 리스트를 정렬하고, 정렬된 순서대로 LinkedHashMap에 입력하면 정렬된 Map을 얻을 수 있다.
📌 Key로 정렬(Sort by Key)
public class Example {
public static LinkedHashMap<String, String> sortMapByKey(Map<String, String> map) {
List<Map.Entry<String, String>> entries = new LinkedList<>(map.entrySet());
Collections.sort(entries, (o1, o2) -> o1.getKey().compareTo(o2.getKey()));
LinkedHashMap<String, String> result = new LinkedHashMap<>();
for (Map.Entry<String, String> entry : entries) {
result.put(entry.getKey(), entry.getValue());
}
return result;
}
public static void main(String[] args) {
Map<String, String> map = new LinkedHashMap<>();
map.put("Nepal", "Kathmandu");
map.put("United States", "Washington");
map.put("India", "New Delhi");
map.put("England", "London");
map.put("Australia", "Canberra");
Map<String, String> result = sortMapByKey(map);
for (Map.Entry<String, String> entry : result.entrySet()) {
System.out.println("Key: " + entry.getKey() + ", "
+ "Value: " + entry.getValue());
}
}
}
//결과
Key: Australia, Value: Canberra
Key: England, Value: London
Key: India, Value: New Delhi
Key: Nepal, Value: Kathmandu
Key: United States, Value: Washington📌 Value로 정렬(Sort by Value)
public class Example {
public static LinkedHashMap<String, String> sortMapByValue(Map<String, String> map) {
List<Map.Entry<String, String>> entries = new LinkedList<>(map.entrySet());
Collections.sort(entries, (o1, o2) -> o1.getValue().compareTo(o2.getValue()));
LinkedHashMap<String, String> result = new LinkedHashMap<>();
for (Map.Entry<String, String> entry : entries) {
result.put(entry.getKey(), entry.getValue());
}
return result;
}
public static void main(String[] args) {
Map<String, String> map = new LinkedHashMap<>();
map.put("Nepal", "Kathmandu");
map.put("United States", "Washington");
map.put("India", "New Delhi");
map.put("England", "London");
map.put("Australia", "Canberra");
Map<String, String> result = sortMapByValue(map);
for (Map.Entry<String, String> entry : result.entrySet()) {
System.out.println("Key: " + entry.getKey() + ", "
+ "Value: " + entry.getValue());
}
}
}
//결과
Key: Australia, Value: Canberra
Key: Nepal, Value: Kathmandu
Key: England, Value: London
Key: India, Value: New Delhi
Key: United States, Value: Washington