파일 목록 나열
import numpy as np # linear algebra import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv)import os for dirname, _, filenames in os.walk('/content/drive/MyDrive/Final_project/data'): for filename in filenames: print(os.path.join(dirname, filename))
Import
import os import math import random import matplotlib.pyplot as plt import cv2 import tensorflow as tf from tensorflow import keras from tensorflow.keras import layers import tensorflow_addons as tfa import tensorflow_datasets as tfds import matplotlib.pyplot as plt import seaborn as sns import tensorflow.keras.backend as K import os, random, json, PIL, shutil, re, imageio, glob from tensorflow.keras import Model, losses, optimizers from tensorflow.keras.callbacks import Callback
TPU 환경이 사용 가능한 경우 TPU를 설정하고 활용
try: tpu = tf.distribute.cluster_resolver.TPUClusterResolver() print(f'Running on TPU {tpu.master()}') except ValueError: tpu = None if tpu: tf.config.experimental_connect_to_cluster(tpu) tf.tpu.experimental.initialize_tpu_system(tpu) strategy = tf.distribute.experimental.TPUStrategy(tpu) else: strategy = tf.distribute.get_strategy() REPLICAS = strategy.num_replicas_in_sync AUTO = tf.data.experimental.AUTOTUNE print(f'REPLICAS: {REPLICAS}')
데이터 경로 구성
BASE_PATH = '/content/drive/MyDrive/Final_project/data/' MONET_PATH = os.path.join(BASE_PATH, 'monet_jpg') PHOTO_PATH = os.path.join(BASE_PATH, 'photo_jpg')
이미지 크기와 해당 크기의 이미지 수를 출력
def show_folder_info(path): d_image_sizes = {} for image_name in os.listdir(path): image = cv2.imread(os.path.join(path, image_name)) d_image_sizes[image.shape] = d_image_sizes.get(image.shape, 0) + 1 for size, count in d_image_sizes.items(): print(f'shape: {size}\tcount: {count}') print('Monet images:') show_folder_info(MONET_PATH) print('Photo images:') show_folder_info(PHOTO_PATH)
이미지 파일을 배치로 시각화하는 함수
def batch_visualization(path, n_images, is_random=True, figsize=(16, 16)): plt.figure(figsize=figsize) w = int(n_images ** .5) h = math.ceil(n_images / w) all_names = os.listdir(path) image_names = all_names[:n_images] if is_random: image_names = random.sample(all_names, n_images) for ind, image_name in enumerate(image_names): img = cv2.imread(os.path.join(path, image_name)) img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB) plt.subplot(h, w, ind + 1) plt.imshow(img) plt.axis('off') plt.show()
Monet 스타일 이미지 무작위로 선택
batch_visualization(MONET_PATH, 12, is_random=True, figsize=(23, 23))

사진 스타일 이미지 무작위로 선택
batch_visualization(PHOTO_PATH, 12, is_random=True, figsize=(23, 23))

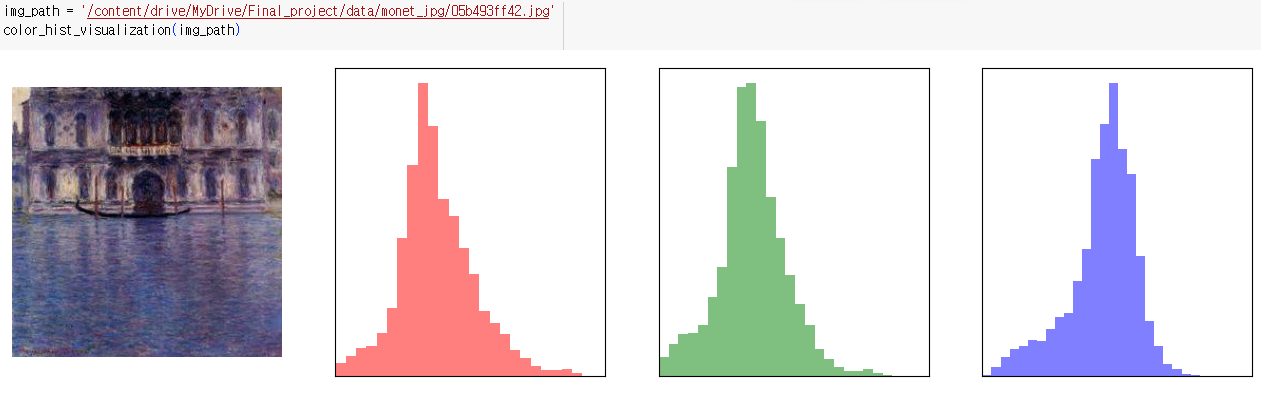
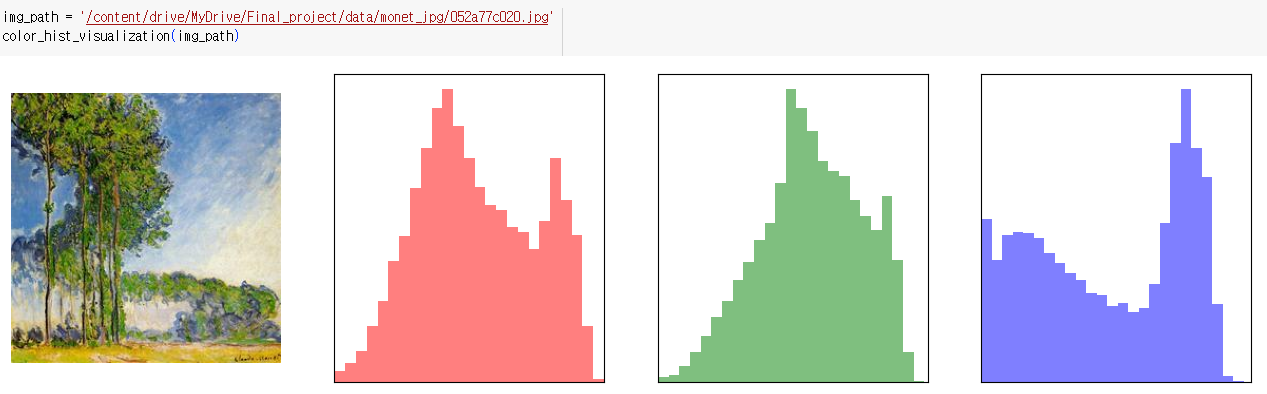
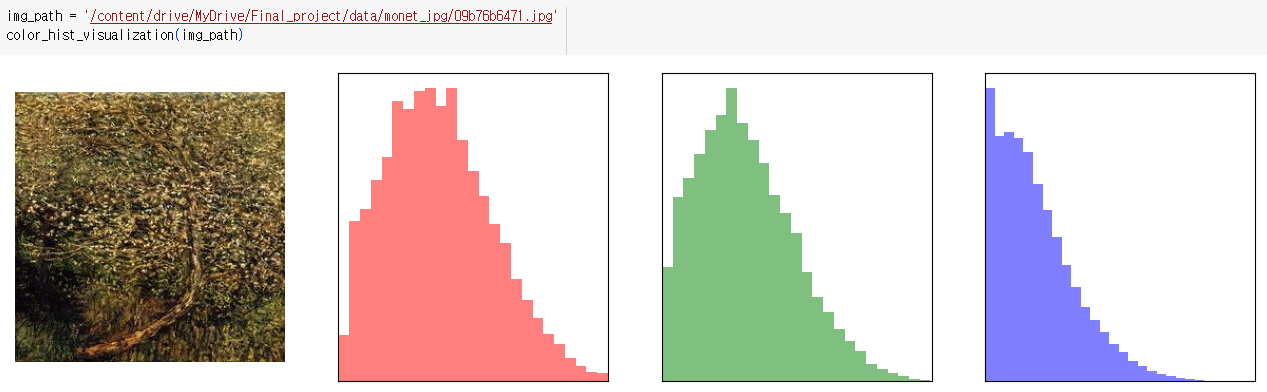
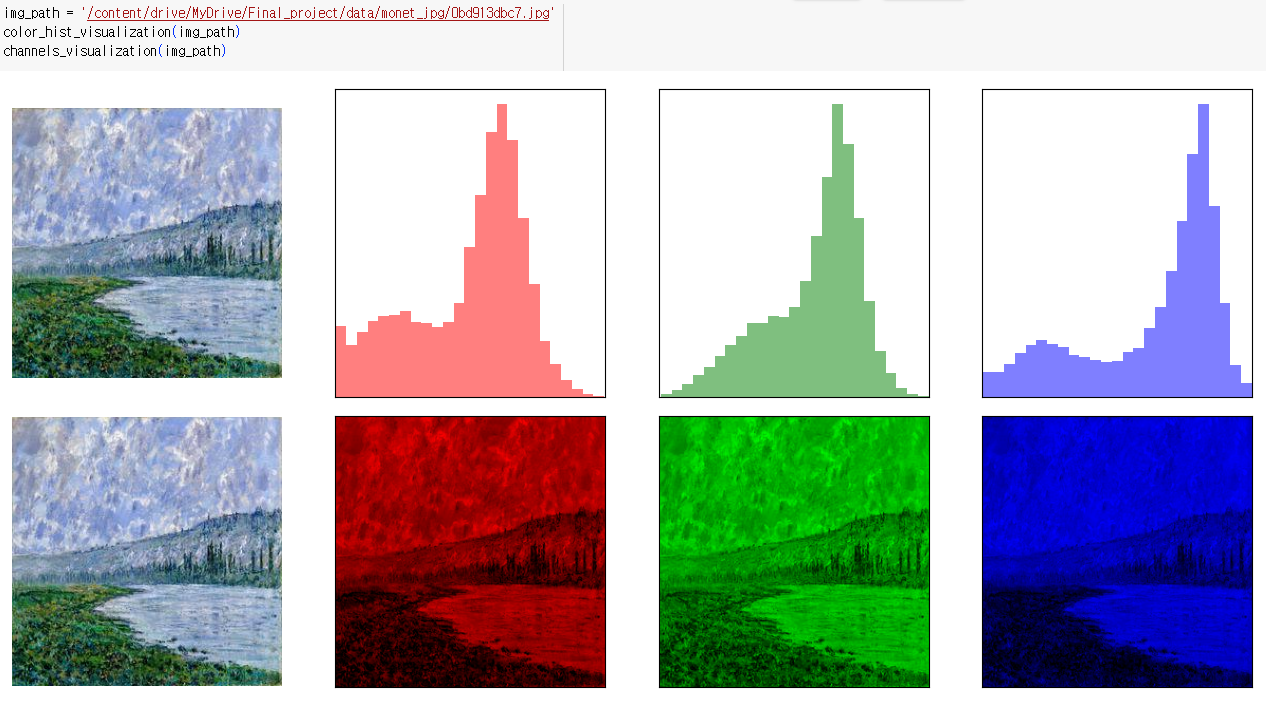
지정된 이미지의 색상 히스토그램 시각화
- 처음에는 원본 이미지가 표시되고, 그 다음에는 각각의 색상 채널에 대한 히스토그램이 표시됨
def color_hist_visualization(image_path, figsize=(16, 4)): plt.figure(figsize=figsize) colors = ['red', 'green', 'blue'] img = cv2.imread(image_path) img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB) plt.subplot(1, 4, 1) plt.imshow(img) plt.axis('off') for i in range(len(colors)): plt.subplot(1, 4, i + 2) plt.hist( img[:, :, i].reshape(-1), bins=25, alpha=0.5, color=colors[i], density=True ) plt.xlim(0, 255) plt.xticks([]) plt.yticks([]) plt.show()
이미지의 RGB(Red, Green, Blue) 각 채널을 개별적으로 시각화하는 함수
def channels_visualization(image_path, figsize=(16, 4)): plt.figure(figsize=figsize) img = cv2.imread(image_path) img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB) plt.subplot(1, 4, 1) plt.imshow(img) plt.axis('off') for i in range(3): plt.subplot(1, 4, i + 2) tmp_img = np.full_like(img, 0) tmp_img[:, :, i] = img[:, :, i] plt.imshow(tmp_img) plt.xlim(0, 255) plt.xticks([]) plt.yticks([]) plt.show()
이미지를 그레이스케일(흑백)로 변환한 후 원본 이미지와 그레이스케일 이미지를 시각화하는 함수
def grayscale_visualization(image_path, figsize=(8, 4)): plt.figure(figsize=figsize) img = cv2.imread(image_path) img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB) plt.subplot(1, 2, 1) plt.imshow(img) plt.axis('off') plt.subplot(1, 2, 2) tmp_img = np.full_like(img, 0) for i in range(3): tmp_img[:, :, i] = img.mean(axis=-1) plt.imshow(tmp_img) plt.axis('off') plt.show()

GCS_PATH
GCS_PATH = '/content/drive/MyDrive/Final_project/data'TensorFlow의 TFRecord 형식 파일에서 데이터 항목의 수를 계산하는 함수
def count_data_items(filenames): n = [int(re.compile(r"-([0-9]*)\.").search(filename).group(1)) for filename in filenames] return np.sum(n)Monet 스타일과 Photo 스타일 이미지 데이터에 대한 TFRecord 파일에서 데이터 항목 수를 계산
MONET_FILENAMES = tf.io.gfile.glob(str(GCS_PATH + '/monet_tfrec/*.tfrec')) PHOTO_FILENAMES = tf.io.gfile.glob(str(GCS_PATH + '/photo_tfrec/*.tfrec')) n_monet_samples = count_data_items(MONET_FILENAMES) n_photo_samples = count_data_items(PHOTO_FILENAMES) print('Number of Monet TFRecord Files:', len(MONET_FILENAMES)) print('Number of Photo TFRecord Files:', len(PHOTO_FILENAMES))
하이퍼파라미터를 설정
BUFFER_SIZE = 1000 BATCH_SIZE = 4 EPOCHS_NUM = 30 IMG_WIDTH = 256 IMG_HEIGHT = 256
- BUFFER_SIZE - 데이터셋을 섞을 때 사용하는 버퍼의 크기
- BATCH_SIZE - 학습할 때 사용하는 배치 크기
- EPOCHS_NUM - 에포크 수
- IMG_WIDTH, IMG_HEIGHT - 이미지 데이터의 가로 및 세로 크기
TFRecord에 저장된 이미지 데이터를 디코딩하고 전처리하는 함수
def decode_image(image): image = tf.image.decode_jpeg(image, channels=3) image = (tf.cast(image, tf.float32) / 127.5) - 1 image = tf.reshape(image, [IMG_HEIGHT, IMG_WIDTH, 3]) return image
- TensorFlow에서 사용되는 이진 데이터 형식
TFRecord 파일에서 데이터를 읽고 해석하는 함수
def read_tfrecord(example): tfrecord_format = { "image_name": tf.io.FixedLenFeature([], tf.string), "image": tf.io.FixedLenFeature([], tf.string), "target": tf.io.FixedLenFeature([], tf.string) } example = tf.io.parse_single_example(example, tfrecord_format) image = decode_image(example['image']) return image
데이터 증강 (data augmentation)을 수행하는 함수
- 데이터 증강은 학습 데이터를 다양한 방법으로 변형하여 모델의 일반화 성능을 향상시키고 overfitting을 방지하는 데 사용된다
- 이미지 데이터를 입력으로 받아 다양한 변형을 적용한다
- 데이터 다양성을 확보하고 모델의 성능을 향상시킬 수 있다
def data_augment(image): p_rotate = tf.random.uniform([], 0, 1.0, dtype=tf.float32) p_spatial = tf.random.uniform([], 0, 1.0, dtype=tf.float32) p_crop = tf.random.uniform([], 0, 1.0, dtype=tf.float32)if p_crop > .5: image = tf.image.resize(image, [286, 286]) image = tf.image.random_crop(image, size=[256, 256, 3]) if p_crop > .9: image = tf.image.resize(image, [300, 300]) image = tf.image.random_crop(image, size=[256, 256, 3])
- p_rotate, p_spatial, p_crop 0부터 1까지의 난수를 생성하여 데이터 증강을 적용할 확률을 정의
- if p_crop > .5: 이미지 크롭(crop)을 적용할 확률이 0.5보다 큰 경우
-- 1) 이미지 크기를 286x286으로 변경한 후 256x256 크기로 무작위로 크롭
-- 2) 크롭을 다시 적용할 확률이 0.9보다 큰 경우 이미지 크기를 300x300으로 변경하고 256x256 크기로 무작위로 크롭if p_rotate > .9: image = tf.image.rot90(image, k=3) # rotate 270º elif p_rotate > .7: image = tf.image.rot90(image, k=2) # rotate 180º elif p_rotate > .5: image = tf.image.rot90(image, k=1) # rotate 90º
- if p_rotate > .9: 이미지 회전을 270도 (3*90도) 적용할 확률이 0.9보다 큰 경우, 이미지를 270도 회전
- elif p_rotate > .7: 이미지 회전을 180도 (2*90도) 적용할 확률이 0.7보다 큰 경우, 이미지를 180도 회전
- elif p_rotate > .5: 이미지 회전을 90도 (1*90도) 적용할 확률이 0.5보다 큰 경우, 이미지를 90도 회전
if p_spatial > .6: image = tf.image.random_flip_left_right(image) image = tf.image.random_flip_up_down(image) if p_spatial > .9: image = tf.image.transpose(image) return image
- if p_spatial > .6: 이미지 좌우 및 상하 반전을 적용할 확률이 0.6보다 큰 경우
-- 1) 이미지를 무작위로 좌우 반전
-- 2) 이미지를 무작위로 상하 반전
-- 3) 좌우 및 상하 반전을 다시 적용할 확률이 0.9보다 큰 경우 이미지를 전치(transpose)시킴
AUTOTUNE 값을 정의
AUTOTUNE = tf.data.experimental.AUTOTUNE
- TensorFlow가 최적의 병렬 실행 수를 자동으로 선택
TFRecord 파일에서 데이터를 로드하고 처리하기 위한 데이터셋을 만드는 함수
def load_dataset(filenames, labeled=True, ordered=False): dataset = tf.data.TFRecordDataset(filenames) dataset = dataset.map(read_tfrecord, num_parallel_calls=AUTOTUNE) return dataset
Monet 스타일 이미지와 Photo 스타일 이미지에 대한 데이터셋을 생성하고 배치 크기를 설정
BATCHSIZE = 1 monet_ds = load_dataset(MONET_FILENAMES, labeled=True).batch(BATCHSIZE, drop_remainder=True) photo_ds = load_dataset(PHOTO_FILENAMES, labeled=True).batch(BATCHSIZE, drop_remainder=True)
GAN (Generative Adversarial Network) 모델을 학습하기 위한 데이터셋을 생성하는 함수
def get_gan_dataset(monet_files, photo_files, augment=None, repeat=True, shuffle=True, batch_size=1): monet_ds = load_dataset(monet_files) photo_ds = load_dataset(photo_files) if augment: monet_ds = monet_ds.map(augment, num_parallel_calls=AUTO) photo_ds = photo_ds.map(augment, num_parallel_calls=AUTO) if repeat: monet_ds = monet_ds.repeat() photo_ds = photo_ds.repeat() if shuffle: monet_ds = monet_ds.shuffle(2048) photo_ds = photo_ds.shuffle(2048) monet_ds = monet_ds.batch(batch_size, drop_remainder=True) photo_ds = photo_ds.batch(batch_size, drop_remainder=True) monet_ds = monet_ds.cache() photo_ds = photo_ds.cache() monet_ds = monet_ds.prefetch(AUTO) photo_ds = photo_ds.prefetch(AUTO) gan_ds = tf.data.Dataset.zip((monet_ds, photo_ds)) return gan_ds
- Monet 스타일 이미지와 Photo 스타일 이미지에 대한 데이터셋을 준비하고, 데이터 증강, 반복, 섞기, 배치 처리 등의 데이터 전처리 단계를 적용
GAN 학습 데이터셋 생성, 데이터셋에서 한 번의 반복을 수행한 후 예제 이미지를 가져오는 작업
full_dataset = get_gan_dataset(MONET_FILENAMES, PHOTO_FILENAMES, augment=data_augment, repeat=True, shuffle=True, batch_size=BATCH_SIZE) example_monet , example_photo = next(iter(full_dataset))
데이터셋에서 이미지를 가져와 시각화하는 함수
def view_image(ds, nrows=1, ncols=5): ds_iter = iter(ds) fig = plt.figure(figsize=(25, nrows * 5.05 )) # figsize with Width, Height for i in range(ncols * nrows): image = next(ds_iter) image = image.numpy() ax = fig.add_subplot(nrows, ncols, i+1, xticks=[], yticks=[]) ax.imshow(image[0] * 0.5 + .5) # rescale the data in [0, 1] for display
- 주어진 데이터셋에서 이미지를 추출하고 이를 시각화하여 데이터셋의 이미지 샘플을 확인


다운샘플링 레이어를 생성하는 함수
OUTPUT_CHANNELS = 3def downsample(filters, size, apply_instancenorm=True): initializer = tf.random_normal_initializer(0., 0.02) gamma_init = keras.initializers.RandomNormal(mean=0.0, stddev=0.02) result = keras.Sequential() result.add(layers.Conv2D(filters, size, strides=2, padding='same', kernel_initializer=initializer, use_bias=False)) if apply_instancenorm: result.add(tfa.layers.InstanceNormalization(gamma_initializer=gamma_init)) result.add(layers.LeakyReLU()) return result
- 다운샘플링이란 컨볼루션 신경망(Convolutional Neural Network, CNN)에서 사용되는 레이어 중 하나로, 입력 데이터의 공간 해상도(이미지 크기)를 줄이고 특징 맵의 깊이(채널 수)를 증가시키는 역할을 함
- 다운샘플링 레이어는 GAN 모델에서 이미지를 처리하고 특징을 추출
업샘플링 레이어를 생성하는 함수
def upsample(filters, size, apply_dropout=False): initializer = tf.random_normal_initializer(0., 0.02) gamma_init = keras.initializers.RandomNormal(mean=0.0, stddev=0.02) result = keras.Sequential() result.add(layers.Conv2DTranspose(filters, size, strides=2, padding='same', kernel_initializer=initializer, use_bias=False)) result.add(tfa.layers.InstanceNormalization(gamma_initializer=gamma_init)) if apply_dropout: result.add(layers.Dropout(0.5)) result.add(layers.ReLU()) return result
- 업샘플링이란 입력 데이터의 공간 해상도(이미지 크기)를 증가시키고, 특징 맵의 깊이(채널 수)를 줄이는 과정
- 업샘플링 레이어는 입력 이미지를 키우고 더 많은 세부 정보를 추가하여 더 고해상도의 출력 이미지를 생성하는 데 도움을 준다
GAN의 생성자 모델을 정의하는 함수인 Generator
def Generator(): inputs = layers.Input(shape=[256,256,3])down_stack = [ downsample(64, 4, apply_instancenorm=False), # (bs, 128, 128, 64) downsample(128, 4), # (bs, 64, 64, 128) downsample(256, 4), # (bs, 32, 32, 256) downsample(512, 4), # (bs, 16, 16, 512) downsample(512, 4), # (bs, 8, 8, 512) downsample(512, 4), # (bs, 4, 4, 512) downsample(512, 4), # (bs, 2, 2, 512) downsample(512, 4), # (bs, 1, 1, 512) ]up_stack = [ upsample(512, 4, apply_dropout=True), # (bs, 2, 2, 1024) upsample(512, 4, apply_dropout=True), # (bs, 4, 4, 1024) upsample(512, 4, apply_dropout=True), # (bs, 8, 8, 1024) upsample(512, 4), # (bs, 16, 16, 1024) upsample(256, 4), # (bs, 32, 32, 512) upsample(128, 4), # (bs, 64, 64, 256) upsample(64, 4), # (bs, 128, 128, 128) ]initializer = tf.random_normal_initializer(0., 0.02) last = layers.Conv2DTranspose(OUTPUT_CHANNELS, 4, strides=2, padding='same', kernel_initializer=initializer, activation='tanh') # (bs, 256, 256, 3) x = inputs skips = []for down in down_stack: x = down(x) skips.append(x)skips = reversed(skips[:-1])for up, skip in zip(up_stack, skips): x = up(x) x = layers.Concatenate()([x, skip])x = last(x)return keras.Model(inputs=inputs, outputs=x)
- 저수준의 이미지 특징을 이용하여 고품질 이미지를 생성하는 역할을 한다
- 훈련 데이터와 비슷한 이미지를 생성하도록 학습한다
- GAN은 생성자와 판별자라는 두 개의 네트워크로 구성되며, 생성자는 이미지를 생성하고 판별자는 생성된 이미지가 실제 데이터와 얼마나 유사한지 판별한다
GAN의 판별자 모델을 정의하는 함수인 Discriminator
def Discriminator(): initializer = tf.random_normal_initializer(0., 0.02) gamma_init = keras.initializers.RandomNormal(mean=0.0, stddev=0.02) inp = layers.Input(shape=[256, 256, 3], name='input_image') x = inp down1 = downsample(64, 4, False)(x) # (bs, 128, 128, 64) down2 = downsample(128, 4)(down1) # (bs, 64, 64, 128) down3 = downsample(256, 4)(down2) # (bs, 32, 32, 256) zero_pad1 = layers.ZeroPadding2D()(down3) # (bs, 34, 34, 256) conv = layers.Conv2D(512, 4, strides=1, kernel_initializer=initializer, use_bias=False)(zero_pad1) # (bs, 31, 31, 512) norm1 = tfa.layers.InstanceNormalization(gamma_initializer=gamma_init)(conv) leaky_relu = layers.LeakyReLU()(norm1) zero_pad2 = layers.ZeroPadding2D()(leaky_relu) # (bs, 33, 33, 512) last = layers.Conv2D(1, 4, strides=1, kernel_initializer=initializer)(zero_pad2) # (bs, 30, 30, 1) return tf.keras.Model(inputs=inp, outputs=last)
- 판별자 모델은 생성된 이미지가 실제 이미지와 얼마나 유사한지를 판별하는 역할을 한다
- 판별자 모델은 생성된 이미지와 실제 이미지 간의 차이를 감지하여 학습하며, 생성자 모델은 이러한 차이를 줄이도록 학습한다
- GAN의 핵심 아이디어는 생성자와 판별자가 서로 경쟁하면서 모델이 점차적으로 더 나은 이미지를 생성하도록 하는 것이다
분산 훈련을 활용하는 TPU환경에서 GAN 모델을 생성
- strategy.scope()는 TPU 환경에서 모델을 정의하고 학습하기 위한 컨텍스트를 설정
with strategy.scope(): monet_generator = Generator() photo_generator = Generator() monet_discriminator = Discriminator() photo_discriminator = Discriminator()
- strategy.scope() 내에서 모델을 생성하면, 모델의 가중치 업데이트와 학습 프로세스가 TPU로 병렬처리되므로 학습 과정이 효율적으로 수행된다
Monet 스타일로 변환된 이미지를 생성하고, 원본 사진과 Monet 스타일 이미지를 시각적으로 비교
to_monet = monet_generator(example_photo) plt.subplot(1, 2, 1) plt.title("Original Photo") plt.imshow(example_photo[0] * 0.5 + 0.5) plt.subplot(1, 2, 2) plt.title("Monet-esque Photo") plt.imshow(to_monet[0] * 0.5 + 0.5) plt.show()
CycleGAN 모델을 정의하고 훈련
class CycleGan(keras.Model): def __init__( self, monet_generator, photo_generator, monet_discriminator, photo_discriminator, lambda_cycle=10, ): super(CycleGan, self).__init__() self.m_gen = monet_generator self.p_gen = photo_generator self.m_disc = monet_discriminator self.p_disc = photo_discriminator self.lambda_cycle = lambda_cycledef compile( self, m_gen_optimizer, p_gen_optimizer, m_disc_optimizer, p_disc_optimizer, gen_loss_fn, disc_loss_fn, cycle_loss_fn, identity_loss_fn ): super(CycleGan, self).compile() self.m_gen_optimizer = m_gen_optimizer self.p_gen_optimizer = p_gen_optimizer self.m_disc_optimizer = m_disc_optimizer self.p_disc_optimizer = p_disc_optimizer self.gen_loss_fn = gen_loss_fn self.disc_loss_fn = disc_loss_fn self.cycle_loss_fn = cycle_loss_fn self.identity_loss_fn = identity_loss_fndef train_step(self, batch_data): real_monet, real_photo = batch_datawith tf.GradientTape(persistent=True) as tape: # photo to monet back to photo fake_monet = self.m_gen(real_photo, training=True) cycled_photo = self.p_gen(fake_monet, training=True)# monet to photo back to monet fake_photo = self.p_gen(real_monet, training=True) cycled_monet = self.m_gen(fake_photo, training=True)# generating itself same_monet = self.m_gen(real_monet, training=True) same_photo = self.p_gen(real_photo, training=True)# discriminator used to check, inputing real images disc_real_monet = self.m_disc(real_monet, training=True) disc_real_photo = self.p_disc(real_photo, training=True)# discriminator used to check, inputing fake images disc_fake_monet = self.m_disc(fake_monet, training=True) disc_fake_photo = self.p_disc(fake_photo, training=True)# evaluates generator loss monet_gen_loss = self.gen_loss_fn(disc_fake_monet) photo_gen_loss = self.gen_loss_fn(disc_fake_photo)# evaluates total cycle consistency loss total_cycle_loss = self.cycle_loss_fn(real_monet, cycled_monet, self.lambda_cycle) + self.cycle_loss_fn(real_photo, cycled_photo, self.lambda_cycle)# evaluates total generator loss total_monet_gen_loss = monet_gen_loss + total_cycle_loss + self.identity_loss_fn(real_monet, same_monet, self.lambda_cycle) total_photo_gen_loss = photo_gen_loss + total_cycle_loss + self.identity_loss_fn(real_photo, same_photo, self.lambda_cycle)# evaluates discriminator loss monet_disc_loss = self.disc_loss_fn(disc_real_monet, disc_fake_monet) photo_disc_loss = self.disc_loss_fn(disc_real_photo, disc_fake_photo)# Calculate the gradients for generator and discriminator monet_generator_gradients = tape.gradient(total_monet_gen_loss, self.m_gen.trainable_variables) photo_generator_gradients = tape.gradient(total_photo_gen_loss, self.p_gen.trainable_variables) monet_discriminator_gradients = tape.gradient(monet_disc_loss, self.m_disc.trainable_variables) photo_discriminator_gradients = tape.gradient(photo_disc_loss, self.p_disc.trainable_variables)# Apply the gradients to the optimizer self.m_gen_optimizer.apply_gradients(zip(monet_generator_gradients, self.m_gen.trainable_variables)) self.p_gen_optimizer.apply_gradients(zip(photo_generator_gradients, self.p_gen.trainable_variables)) self.m_disc_optimizer.apply_gradients(zip(monet_discriminator_gradients, self.m_disc.trainable_variables)) self.p_disc_optimizer.apply_gradients(zip(photo_discriminator_gradients, self.p_disc.trainable_variables))return { "monet_gen_loss": total_monet_gen_loss, "photo_gen_loss": total_photo_gen_loss, "monet_disc_loss": monet_disc_loss, "photo_disc_loss": photo_disc_loss }
- CycleGAN은 두 도메인 간의 이미지 변환을 수행하는 GAN 모델
- TPU를 활용하여 모델을 훈련
- 과정
-- 1) 입력 이미지를 생성자 모델을 통해 변환
-- 2) 생성자가 생성한 이미지를 다시 원래 도메인으로 변환하여 사이클 일관성을 검사
-- 3) 원래 이미지와 생성자가 생성한 이미지를 이용하여 동일성 손실을 계산
-- 4) 판별자 모델을 사용하여 실제 이미지와 생성자가 생성한 이미지를 판별하고, 이를 통해 생성자 손실을 계산
-- 5) 경사 하강법을 사용하여 생성자 및 판별자의 가중치를 업데이트
-- 6) 각 손실과 업데이트된 가중치를 반환
(Monet 스타일로 변환된 이미지와 원본 이미지 간의 일관성을 유지하고 원본 이미지와 동일한 스타일을 가진 이미지를 생성하도록 학습)
GAN 모델에서 사용되는 손실 함수들을 정의
- (손실 함수들은 GAN 모델의 훈련 중에 사용되어 생성자와 판별자의 손실을 계산하고, 모델이 원하는 이미지 변환을 수행하도록 학습한다)
with strategy.scope(): def discriminator_loss(real, generated): real_loss = losses.BinaryCrossentropy(from_logits=True, reduction=losses.Reduction.NONE)(tf.ones_like(real), real) generated_loss = losses.BinaryCrossentropy(from_logits=True, reduction=losses.Reduction.NONE)(tf.zeros_like(generated), generated) total_disc_loss = real_loss + generated_loss return total_disc_loss * 0.5
- discriminator_loss는 판별자 손실 함수로, 생성된 이미지와 실제 이미지 간의 차이를 측정
- real_loss 실제 이미지에 대한 손실
- generated_loss 생성된 이미지에 대한 손실
def generator_loss(generated): return losses.BinaryCrossentropy(from_logits=True, reduction=losses.Reduction.NONE)(tf.ones_like(generated), generated)
- generator_loss는 생성자 손실 함수로, 생성된 이미지가 실제 이미지와 얼마나 유사한지 측정
- 생성된 이미지에 대한 손실을 반환
with strategy.scope(): def calc_cycle_loss(real_image, cycled_image, LAMBDA): loss1 = tf.reduce_mean(tf.abs(real_image - cycled_image)) return LAMBDA * loss1
- calc_cycle_loss는 사이클 일관성 손실 함수로, 원본 이미지와 이를 변환한 이미지 사이의 차이를 측정
- LAMBDA는 가중치 매개변수로 사용되며, 일관성 손실에 대한 가중치를 조절
- 두 이미지 간의 차이에 가중치를 곱한 손실을 반환
with strategy.scope(): def identity_loss(real_image, same_image, LAMBDA): loss = tf.reduce_mean(tf.abs(real_image - same_image)) return LAMBDA * 0.5 * loss
- identity_loss는 동일성 손실 함수로, 원본 이미지와 동일한 이미지에 대한 차이를 측정
- 이미지 간의 차이에 가중치를 곱한 후 0.5를 곱하여 반환
CycleGAN 모델의 생성자와 판별자에 대한 옵티마이저를 설정
- 옵티마이저는 모델의 가중치 업데이트를 관리하고 학습을 수행하는 데 중요한 역할을 한다
with strategy.scope(): monet_generator_optimizer = tf.keras.optimizers.Adam(2e-4, beta_1=0.5) photo_generator_optimizer = tf.keras.optimizers.Adam(2e-4, beta_1=0.5) monet_discriminator_optimizer = tf.keras.optimizers.Adam(2e-4, beta_1=0.5) photo_discriminator_optimizer = tf.keras.optimizers.Adam(2e-4, beta_1=0.5)
CycleGAN 모델을 설정하고 컴파일
with strategy.scope(): cycle_gan_model = CycleGan( monet_generator, photo_generator, monet_discriminator, photo_discriminator ) cycle_gan_model.compile( m_gen_optimizer = monet_generator_optimizer, p_gen_optimizer = photo_generator_optimizer, m_disc_optimizer = monet_discriminator_optimizer, p_disc_optimizer = photo_discriminator_optimizer, gen_loss_fn = generator_loss, disc_loss_fn = discriminator_loss, cycle_loss_fn = calc_cycle_loss, identity_loss_fn = identity_loss )
- Monet 스타일로 이미지를 생성하고 사진 스타일로 이미지를 생성하며, 판별자를 사용하여 생성된 이미지를 평가하고 훈련한다
CycleGAN 모델을 실제로 훈련
cycle_gan_model.fit( full_dataset, epochs=EPOCHS_NUM, steps_per_epoch=(max(n_monet_samples, n_photo_samples)//BATCH_SIZE), )
훈련된 CycleGAN 모델을 사용하여 입력 이미지에서 생성된 이미지를 표시하는 함수
def display_generated_samples(ds, model, n_samples): ds_iter = iter(ds) for n_sample in range(n_samples): example_sample = next(ds_iter) generated_sample = model.predict(example_sample) plt.subplot(121) plt.title("Input image") plt.imshow(example_sample[0] * 0.5 + 0.5) plt.axis('off') plt.subplot(122) plt.title("Generated image") plt.imshow(generated_sample[0] * 0.5 + 0.5) plt.axis('off') plt.show()display_generated_samples(load_dataset(PHOTO_FILENAMES).batch(1), monet_generator, 7)

주어진 입력 데이터셋에서 이미지를 생성하고 그 이미지를 저장하는 함수
import PIL def predict_and_save(input_ds, generator_model, output_path): i = 1 for img in input_ds: prediction = generator_model(img, training=False)[0].numpy() prediction = (prediction * 127.5 + 127.5).astype(np.uint8) im = PIL.Image.fromarray(prediction) im.save(f'{output_path}{str(i)}.jpg') i += 1
- 입력 데이터셋에서 이미지를 하나씩 가져와서 generator_model을 사용하여 해당 이미지의 예측을 생성한다
- 예측된 이미지를 원래 범위로 다시 스케일하고 이미지 파일로 저장한다
- 이미지는 연속된 번호를 가진 파일 이름으로 저장된다
디렉토리를 생성하고 이미지를 생성 및 저장
import os os.makedirs('../images/') predict_and_save(load_dataset(PHOTO_FILENAMES).batch(1), monet_generator, '../images/')
이미지 디렉토리를 압축하고 생성된 이미지 샘플의 수를 출력
import shutil shutil.make_archive('/content/drive/MyDrive/Final_project/data/', 'zip', '../images') print(f"Number of generated samples: {len([name for name in os.listdir('/content/drive/MyDrive/Final_project/data/') if os.path.isfile(os.path.join('/content/drive/MyDrive/Final_project/data/', name))])}")
