.png)
이번 프로젝트에서 레스토랑 정보를 평균 점수로 filtering, sorting하는 업무를 맡았었다.
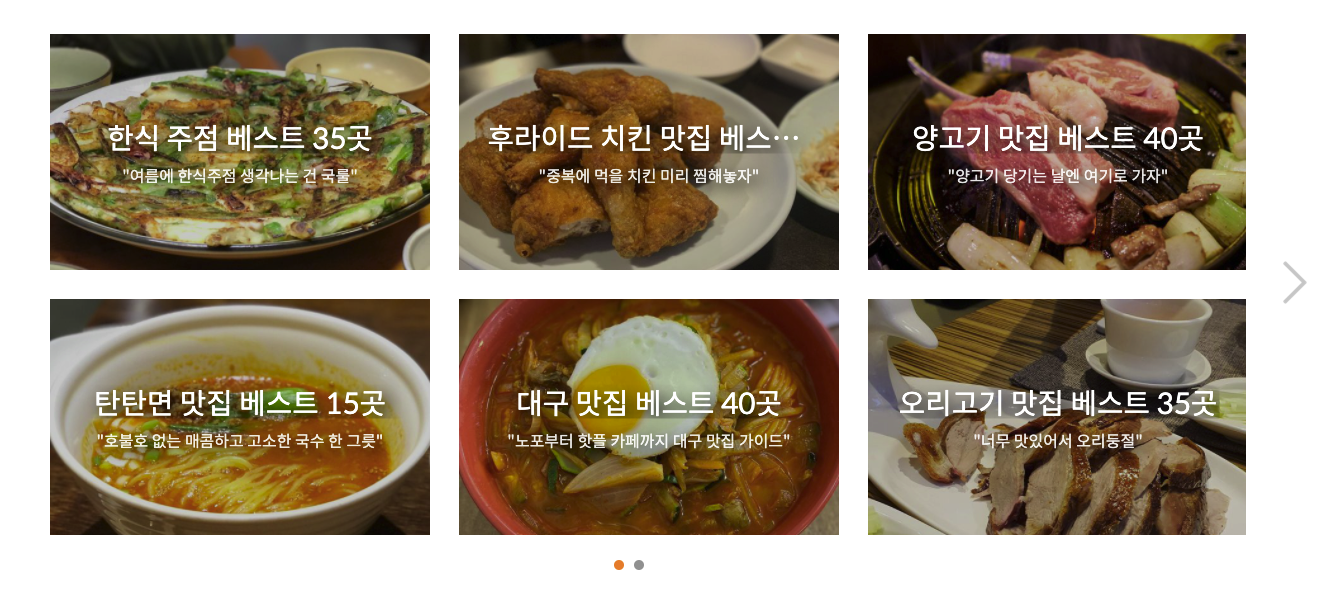
메인화면에 이렇게 서브카테고리 별로 컨텐츠가 나열되어 있고 이 컨텐츠를 누르면 아래와 같은 화면으로 넘어가게하는 코드를 작성했다.
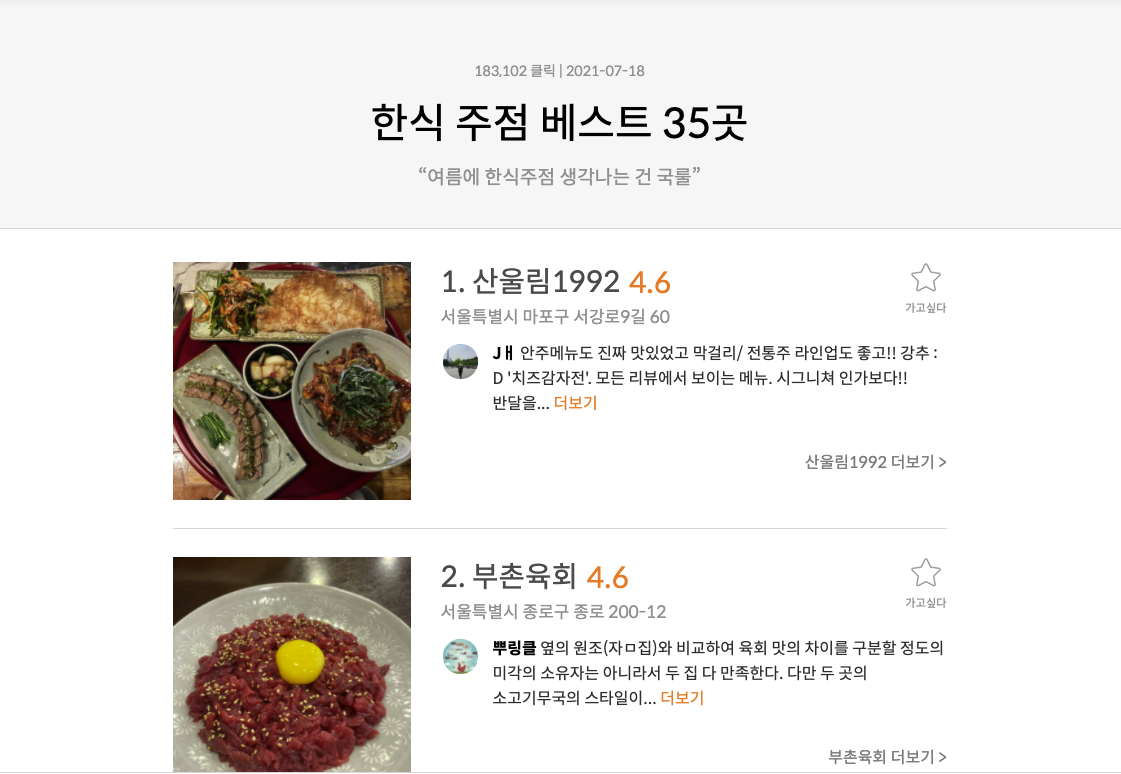
처음에는 아래와 같이 코드를 작성했다.
class RestaurantListView(View):
def get(self, request, sub_category_id):
try:
sub_categorys = SubCategory.objects.all()
sub_category_list = []
for sub_category in sub_categorys:
restaurants = sub_category.restaurants.all()
restaurant_list = []
for restaurant in restaurants:
restaurant_list.append({
"name" : restaurant.name,
"address" : restaurant.address,
"content" : restaurant.review_set.order_by('?')[0].content,
"profile_url" : restaurant.review_set.order_by('?')[0].user.profile_url,
"nickname" : restaurant.review_set.order_by('?')[0].user.nickname,
"image" : restaurant.foods.all()[0].images.all()[0].image_url,
"rating" : round(restaurant.review_set.all().aggregate(Avg('rating'))['rating__avg'], 1)
})
restaurant_list = sorted(restaurant_list, key=lambda x:x['rating'], reverse=True)
return JsonResponse({"message":"success", "result":restaurant_list}, status=200)
except KeyError:
return JsonResponse({"message":"KEY_ERROR"}, status=400)우선 subcategory의 모든 내용이 필요했다. 그래고 이 서브카테고리 별로 음식점 정보를 가져왔어야했기 때문에 2중 for문을 돌려 리스트를 뽑아내려고 했다.
sub_categorys = SubCategory.objects.all() sub_category_list = [] for sub_category in sub_categorys: restaurants = sub_category.restaurants.all()
근데 문제가 3가지가 있었다.
1. 페이지가 넘어가는 요청을 생각하지 않았다는 점
2. 2중 for문을 돌려 불필요한 쿼리의 반복 횟수를 늘렸다는 점
3. 필요없는 list를 생성했다는 점
그래서 아래와 같이 코드를 작성했다.
class RestaurantView(View):
def get(self, request):
try:
ordering = request.GET.get("ordering", None)
sub_category = int(request.GET.get("sub_category_id", None))
if sub_category:
restaurants = Restaurant.objects.filter(sub_category_id=sub_category).annotate(average_rating=Avg("review__rating")).order_by("-"+ordering)
else:
restaurants = Restaurant.objects.annotate(average_rating=Avg("review__rating")).order_by("-"+ordering)
restaurant_list = []
for restaurant in restaurants:
restaurant_list.append({
"name" : restaurant.name,
"address" : restaurant.address,
"content" : restaurant.review_set.order_by('?')[0].content,
"profile_url" : restaurant.review_set.order_by('?')[0].user.profile_url,
"nickname" : restaurant.review_set.order_by('?')[0].user.nickname,
"image" : restaurant.foods.all()[0].images.all()[0].image_url,
"rating" : round(restaurant.average_rating, 1),
"restaurant_id" : restaurant.id
})
return JsonResponse({"message":"success", "result":restaurant_list[:5]}, status=200)
except Restaurant.DoesNotExist:
return JsonResponse({"message":"RESTAURANT_NOT_EXIST"}, status=404)우선 request.get을 사용하여 사용자의 요청을 처리한다.
그리고 sub_category가 있으면 필러링을 거쳐 id에 맞는 정보를 제공해준다.
만약 없을 때는 그냥 요청을 평균순으로 제공해줬다.
근데 이 코드에도 많은 리펙토링이 필요하다는 것을 깨달았다. insight를 주신 병민 멘토님 감사합니다!👍
-
if, else 보다는 q 객체를 사용하는 것
이유 : filter, exclude, get 과 같은 조회함수와 함께 사용해서 복잡한 조건 검색을 효율적으로 할 수 있기 때문이다. -
검증을 거치지않고 뇌피셜로 코드를 작성한 점
restaurant.review_set.order_by('?')[0].content,
restaurant.review_set.order_by('?')[0].user.profile_url,
restaurant.review_set.order_by('?')[0].user.nickname,처음에 내가 이렇게 코드를 짠 이유는 레스토랑의 리뷰를 랜덤으로 가져오고 싶었다. 그리고 이 리뷰를 쓴 사람의 유저 정보를 매칭시켜 같이 가져오고 싶었다. 그것을 이어주는 것이 외래키이라고 생각했다.
하지만 조금만 생각해보면 이 생각이 완전 틀렸다는 것을 깨달을 수 있다. 댓글, 유저 사진, 닉네임이 다 랜덤으로 돌지않을까라는 재경님의 리뷰에 내가 완전 잘못 생각하고 있었구나라는 것을 깨달았다. 😅
- 사실 평균별로 필터링을 거쳐야하는 class가 하나 더 있었다. 똑같은 기능을 하는 코드가 있다면 2개의 class를 하나로 합쳐 프론트에게 json으로 전달했어야했는데, 2개의 코드를 합치려니 너무 헷갈렸다. 그래서 결국 합치는 리펙토링을 하지 못했다. 😰
몇 줄 안되는 코드이지만 이 안에서도 많은 리펙토링이 필요하다는 것을 깨달았다. 더욱 효율적이고 직관적인 코드를 짜기 위해 고민 또 고민을 해야겠다. 👍
