[논문 리뷰] Federated Learning: Strategies for Improving Communication Efficiency - 2편
Federated_learning
Structured Update
Communication efficient update의 첫 번째 유형은 update 가 pre-specified structure 를 갖도록 제한하는 것이다. 논문에서는 이를 위한 두 가지 구조를 고려하는데, 각각 low rank 와 random mask 이다.
여기서 강조할 점은 우리가 이러한 구조의 update를 바로(directly) 학습한다는 것인데, 이는 추후에 다룰 sketched update 즉, 특정 구조에 대한 object로 general한 update 값을 근사(approximating)/스케치(sketching) 하는 방식과는 상반된다.
Low rank
저자는 고정된 숫자 에 대해, local model에 대한 매 update인 가 최대 의 rank를 갖는 low rank matrix가 되도록 한다. 그렇게 만들기 위해 우리는 를 두 행렬의 곱으로 표현해야 한다:
절차는 다음과 같다. 를 랜덤하게 생성한 다음 local training 단계에서는 상수로 취급한다. 즉, 오직 만 최적화 하는 것이다. 이때 주목할 점은 실제 구현에서 가 random seed의 형태로 압축될 수 있다는 것과 client는 오직 학습된 만 server로 보내면 된다는 것이다.
이러한 접근으로 통신 관점에서 만큼의 save가 가능하고, 각 round마다 각 client를 위한 새로운 matrix 가 독립적으로 생성된다.
한편 저자는 를 고정시키고 를 학습시키는 것이나 와 를 동시에 학습시키는 것도 해봤지만, 둘 다 좋은 성능을 내지는 못했다고 한다.
이 방법이 먹히는 것에 대한 직관적인 설명은 다음과 같다. 우리는 를 projection matrix, 를 reconstruction matrix라고 해석할 수 있다. 이 말인즉슨, 를 고정하고 를 최적화하는 행위는 "Random reconstruction이 주어진 상태에서, 어떤 projection이 가장 많은 정보를 복원할 수 있을 것인가?" 를 묻는 것과 비슷하다.
만약 reconstruction이 full-rank라면, 상위 개의 eigenvector를 span하여 space를 복원할 수 있는 projection이 (즉, rank가 ) 존재한다. ( 의 rank가 임을 기억하자)
하지만 만약 우리가 random하게 projection을 고정하고 reconstruction을 찾는다면, 운이 안 좋게도 중요한 subspace가 projection 될 수 있다. 바꿔말하면, 가능한 한 잘 적용되는 reconstruction이 없거나 이를 찾기 매우 어려울 것이라는 말이다. 따라서 를 고정시키고, 를 최적화 시키는 것이 합당하다.
(수학적으로 왜 그런지는 더 찾아봐야 할 것 같다.)
Random mask
미리 정해둔 random sparsity pattern (i.e., random mask)를 따르는 sparse matrix가 되도록 update 를 제한하는 방법이다. Random mask는 매 라운드마다 각 client들에 대해 독립적으로 생성된다.
위에서 서술한 low-rank 방법과 비슷하게, sparse pattern은 random seed를 이용하여 완전히 특정될 수 있으므로, seed와 함께 의 non-zero 성분 값만 보내주면 된다.
Sketched Update
Communication cost 문제를 해결하기 위한 두번째 유형의 update는 sketched 방법이다. 먼저, 별다른 제약 조건이 없이 local training 단계에서 를 전부 (full) 계산한다. 그 다음 update를 근사하거나 encoding 하여, server로 보내기 전 (손실을 감수한) 압축된 형태로 만든다. 이후 server는 aggregation을 진행하기 전에 update를 decode 한다.
이러한 sketching method들은 많은 domain들에 적용될 수 있는데, 저자는 sketch를 수행하기 위해 여러 tool들을 사용하여 실험을 진행했다. 한편, sketching은 상호 호환되는 특징이 있으며 동시에 (jointly) 사용할 수 있다.
Subsampling
각 client는 를 전송하는 것 대신, 값의 random subset으로 구성된 matrix 만을 통신한다. 그리고 server는 subsample 된 update들을 평균 취해 global update 를 만들어낸다. 이러한 방식이 가능한 이유는 sampled update의 평균이 실제 평균 값에 대한 unbiased estimator이기 때문이다. 이를 식으로 표현하면, 이다.
Random mask structured update와 비슷하게 mask는 매 라운드 각 client에 대해 독립적으로 randomize 되고, mask는 그 자체가 동기화된 seed의 형태로 저장 될 수 있다.
Probabilistic quantization
Update를 압축하는 또 다른 방식은 weight들을 quantizing 하는 것이다.
먼저, 각 scalar 값을 하나의 bit로 quantizing 하는 알고리즘의 설명은 다음과 같다. Update 에 대해 , 그리고 으로 두자. 이때 압축된 update 즉, 는 다음과 같이 만들어진다.
가 에 대한 unbiased estimator 임을 보이는 것은 어렵지 않고, 이 방식대로면 4 byte float에 비해 압축을 32배 더 잘 시킬 수 있다. (이에 대한 error 관련해서는 논문을 참고)
위에서 언급한 방식은 하나 이상의 bit로 압축시키는 예제에도 적용할 수 있다. 예를 들어 bit quantization을 생각해보자. 먼저, 구간 을 개의 interval로 분리한다. 그리고 가 와 사이의 구간에 속한다고 생각해보자. 그렇다면 이때의 quantization은 위의 예제에서 가 각각 로 대체되어 적용된다. 그렇다면, bit를 결정하는 parameter 는 accuracy와 communication cost 사이의 균형을 맞추기 위한 간단한 방법을 제시한다고 생각할 수 있다.
(그 외의 방법들은 논문을 참고)
Improving the quantization by structured random rotations
위에서 언급한 1-bit 및 multi-bit quantization 방식은 다른 dimension 간 scale이 거의 동일할 때 가장 잘 작동한다.
예를 들어보자. 만약 max 값이 1이고 min 값이 -1인데, 대부분의 값은 0일 경우 1-bit quantization 방식은 엄청 큰 error를 초래할 것이다. 저자는 이러한 문제를 quantization 하기 전에 에 random rotation을 적용하는 즉, 에 random orthogonal matrix를 곱하는 방식으로 해결했다. (다른 논문에 의하면 이러한 structured random rotation을 통해 quantization error를 만큼 줄일 수 있다고 한다. 이때 는 의 dimension 이다.)
이후 decoding 단계에서, server는 모든 update를 취합하기 전에 inverse rotation을 취해야 한다. 그런데 이때의 문제는 의 dimension 가 혹은 그 이상으로 커질 수 있다는 것이다. 즉, general rotation matrix를 만들고(), 적용시키는 것()이 계산적으로 너무 복잡하다. 따라서 논문에서는 Walsh-Hadamard matrix와 binary diagonal matrix를 곱한 형태의 structured rotation matrix를 사용하는데, 이를 통해 생성()과 적용()에 필요한 complexity를 낮출 수 있다. 참고로 해당 complexity는 FL에서 진행되는 local training과 비교하면 무시할 수 있는 수준이다.
Experiments
논문에서는 두 가지 task에 대해 FL을 사용하여 deep neural network (NN) 학습하는 실험을 진행했다.
첫 번째는 CNN을 기반으로 한 CIFAR-10 image classification task 이고, 두 번째는 recurrent network를 기반으로 public Reddit post data를 사용하는 보다 현실적인 word prediction task 이다.
한편 모든 실험에는 FedAvg 알고리즘을 사용한다. 매 round마다 동일한 확률로 random하게 여러 client들을 선택하고, 각 client는 local dataset을 이용하여 learning rate 의 SGD를 여러 epoch 동안 수행한다.
Sturctured update에서는 SGD가 제한된 space 안에서만 update 되도록 설정된다. 즉, low-rank update에서는 에 대한 항목들만, random-mask technique에서는 unmasked 항목들에 대해서만 update가 진행된다. 이렇게 update 된 model로부터, 우리는 각 layer 에 대한 update를 계산한다.
추가로, 모든 경우에 대해 저자는 learning rate range를 설정하여 best result를 내는 값을 찾는 실험을 진행했다.
Convolutional models on the CIFAR-10 Dataset
CIFAR-10 dataset의 training example 50,000 개는 100명의 client들에게 random하게 같은 개수만큼 나누어졌다. 실험에 사용한 model은 개의 parameter를 가졌으며, convolution layer로만 구성되어 있는데 SOTA는 아니어도 compression method를 검증하기에는 충분한 모델이다.
Model은 9개의 layer를 가지고 있는데, 상대적으로 parameter의 개수가 적은 처음과 마지막 layer를 제외한 7개의 layer로 compress를 진행했다. (나머지 두 layer는 포함해서 해도 효과가 별로 없었다, 7개의 layer가 지닌 parameter의 개수는 같다.)
실험 결과는 아래와 같다. 두 유형의 structured updates(low rank,random mask)를 비교한 결과이다.
CIFAR data에 대해 진행한 structured updates 그래프이다. 위의 가로줄이 low rank updates, 아래의 가로줄이 random mask updates 이다.
이때, mode가 25% 라는 말은 각각의 경우에 대해 다음과 같다.
- Low rank updates: Update의 rank를 full layer transformation rank의 25%로 설정하는 것.
- Random mask (or sketching) updates: 25%의 parameter들을 제외하고는 다 0으로 만드는 것.
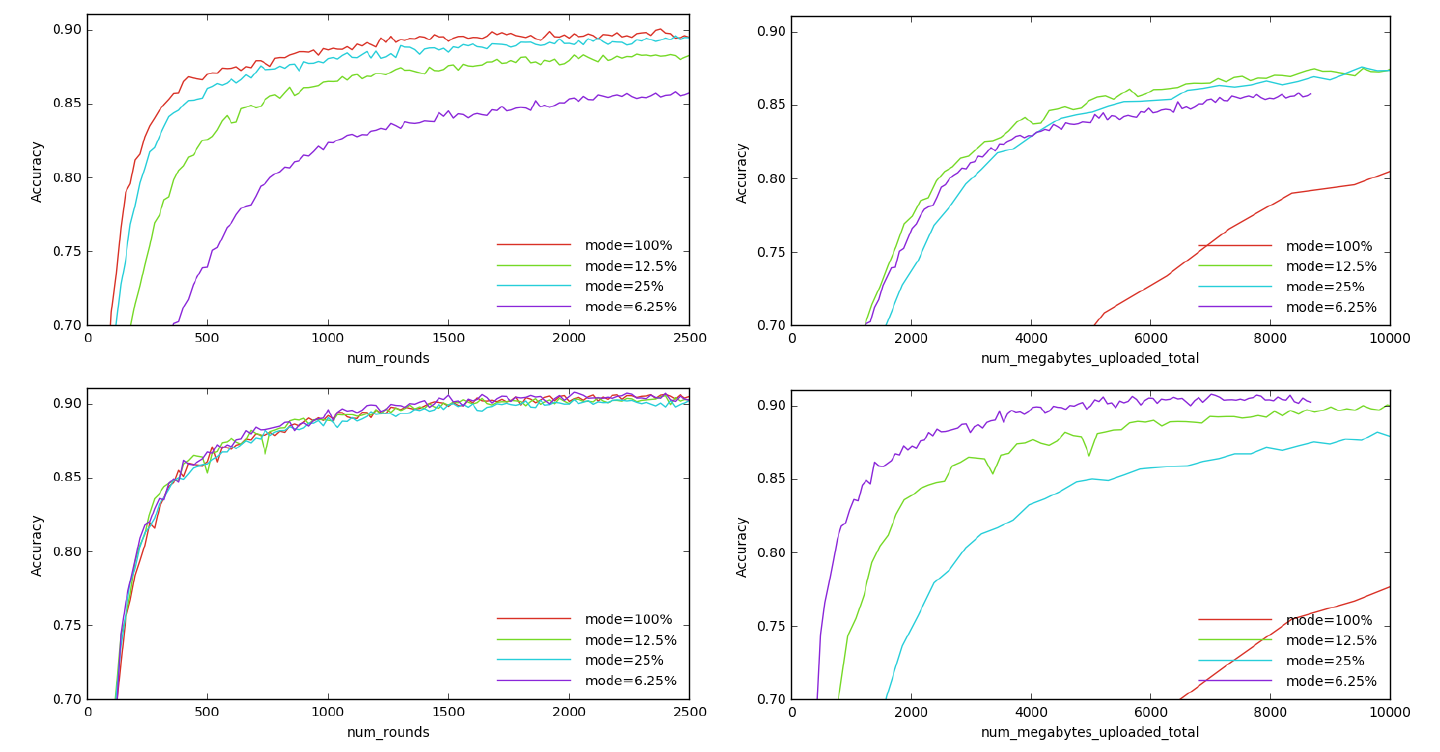
실험을 통해 random mask가 low rank 보다 훨씬 성능이 낫다는 것을 확인할 수 있다. 특히 round 횟수의 관점에서 random mask의 수렴 속도는 거의 영향이 없는 것으로 보인다.
LSTM next-word prediction on Reddit data
우선 논문을 참고하자. (추후 update 예정)
Reference
Konečný, Jakub, et al. "Federated learning: Strategies for improving communication efficiency." arXiv preprint arXiv:1610.05492 (2016).
