Prologue
최종장인 마지막 프로젝트가 끝이 났다. 팀은 기존에 있었던 팀 그대로 진행하면서 그와 동시에 두개의 프로젝트를 진행하게 되었다. 기존에 존재하던 프로젝트는 총 네개의 프로젝트(OCR, IR, RS, AD)가 존재했었다. 그런 와중 우리 팀은 전부 과학 지식 질의응답 프로젝트를 선택하였고, 기존의 6명이 전부 같은 팀으로 신청하였다.
그러나 실제로 대회가 직접적으로 진행되려 할 때 쯤 제안이 들어왔다. 즉, 팀을 두 그룹으로 나누어 3인, 3인으로 IR과 AD를 나누어 진행하는 것이 어떻냐는 제안이었고 우리는 두가지 대회를 모두 참여하는 것으로 협의를 하여 진행하기로 하였고, 시작한지 얼마 되지 않아 추가로 한명의 팀원이 IR로 참여하였다.
이로써 4개의 카테고리로 나뉘어진 대회 중 2개의 대회를 시작하였다.
개요
1. 프로젝트 개요
A. 개요
A-1. IR
과학 지식에 관해 질문을 입력하면 과학 관련된 답을 내어주는 챗봇 시스템을 구축하는 통상 RAG를 진행하는 대회였다. 과학과 관련되지 않은 질문이 요청되었을 경우 시스템에 존재하지 않는다는 답과 함께 참조하는 문서가 없게끔 진행해야 한다. 과학과 관련없는 질문이 포함되었을 때 오히려 문서 참조를 하게 될 경우 스코어가 감소하는 경향이 있기 때문에 확실한 분류가 진행된 다음 참조 문서를 불러오게 하는 전략이 좋다고 한다.
A-2. AD
화학 공정에서 발생하는 이상 탐지를 감지하는 대회다. 공정에서 일부 요인으로 인해 이상치가 발생하기도 하며 이러한 이상치는 기계 작동에 치명적 결함을 입혀 막대한 손실을 야기할 수 있다. 이러한 이상치를 조기에 발견하여 바로 잡기 위해 진행하는 것을 목적으로 분석하는 대회였다.
B. 환경
팀구성 : 7인 1팀, 인당 3090ti서버를 VSCode와 SSH로 연결해서 사용, GPT team credit $
협업 환경 : Notion, Github
의사 소통 : Slack, Zoom, Offline Meeting
2. 프로젝트 팀 구성 및 역할
팀 구성
배정 받은 팀은 7인이었다. 두 가지 대회를 모두 참여하는 사람이 어느정도 있었기 때문에 한 가지 대회만 몰입하여 진행하기에는 시간적 여유가 받쳐주질 않았었다. 따라서 Upstage에서 제공해주었던 강의를 학습하고 내용을 공유하면서 실전 대회에서 각자 적용해 볼 수 있는 방법을 생각하여 적용하고 각자의 아이디어가 적용 되었을 때 어떠한 효과가 있는지에 대해 관찰일지를 노션에 작성하고 정기 회의를 통하여 내용을 공유하기로 하였다.
3. 프로젝트 수행 절차 및 방법
A. 팀 목표 설정
팀 목표는 두 가지 대회에서 가져갈 수 있는 모든 지식을 가져가고 각자 원하는 태스크의 차이가 존재했기 때문에 서로간의 목표를 얻어가는 선에서 각자의 목표를 수립해 가기로 정했었다. 그럼에도 한 팀으로써 최종적으로 한 작품을 만들어내기 위해 최소한의 정기적 회의를 통해 내용을 공유하고 개인적인 task를 융합하여 좀 더 고도화 된 방법론 및 분석을 진행하기로 하였다. 기본적으로 다음과 같은 목표를 설정하였다.
IR
1~2주차: 강의 내용을 이해하고 각자에게 설명할 수 있을 정도의 학습을 진행
3~4주차: GPT Credit을 활용해 BaseLine을 진행해보고 강의에서 학습하여 적용해 보고 싶었던 내용을 추가적으로 학습하여 모델 고도화 및 실험 적용
AD
1주차: 데이터 handling에관한 강의를 보고 대회 데이터에 적합하여 EDA적용하여 결과 보고
2주차: 각자의 모델을 선택하여 강의를 보면서 활용할 모델의 BaseLine을 생성
3주차: 모델의 고도화 진행 및 결과 해석 + 추가적인 EDA를 통한 피드백
4주차: Dash를 활용하여 대시보드 제작 및 모델 모듈화 & 파이토치 템플릿 적용
B. 프로젝트 사전기획
(1) Time-line 수립
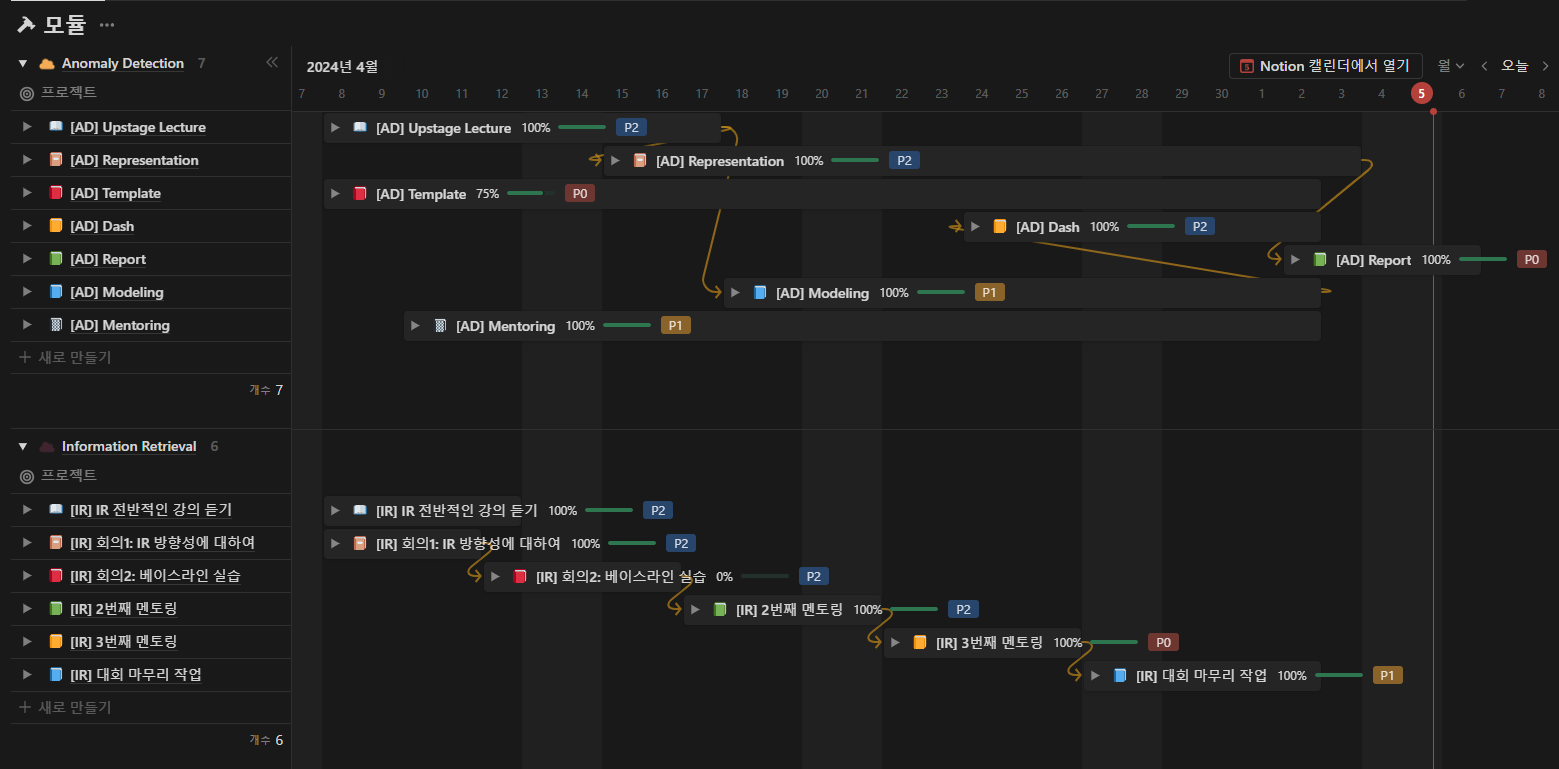
Notion을 활용하여 간트 차트 및 회의 기록을 진행하였다. IR과 AD 두가지 프로젝트를 동시 진행하기 위해 한눈에 볼 수 있는 페이지를 제작하였다. 해당 간트차트 링크를 참조하였다.
(2) 협업 문화
두가지 프로젝트를 동시에 진행하다 보니 각자 원하는 태스크에 대해 차이가 있을 수 밖에 없었다. 따라서 기본적인 규칙을 다음과 같이 정하고 진행하였다.
4. 수행 결과
IR
대회 시작이 4월 22일 부터 진행되었기 때문에 팀 결합에서 문제가 생겼었다. 따라서 대회를 진행할 때 어쩔 수 없이 각자 개인적으로 제출을 하되 회의나 토의활동을 무조건 팀 단위로 진행하였다. 주로 오전 10시에 회의를 진행하였으며 최종적으로 스코어가 가장 높았던 전략은 다음과 같다.
쿼리검색:hybrid retrieve
유사도: ko-sroberta-multitask
역색인: LMJelinekMerce
parameter: match boost 0.002
최종적으로 제출했던 score은 다음과 같다.
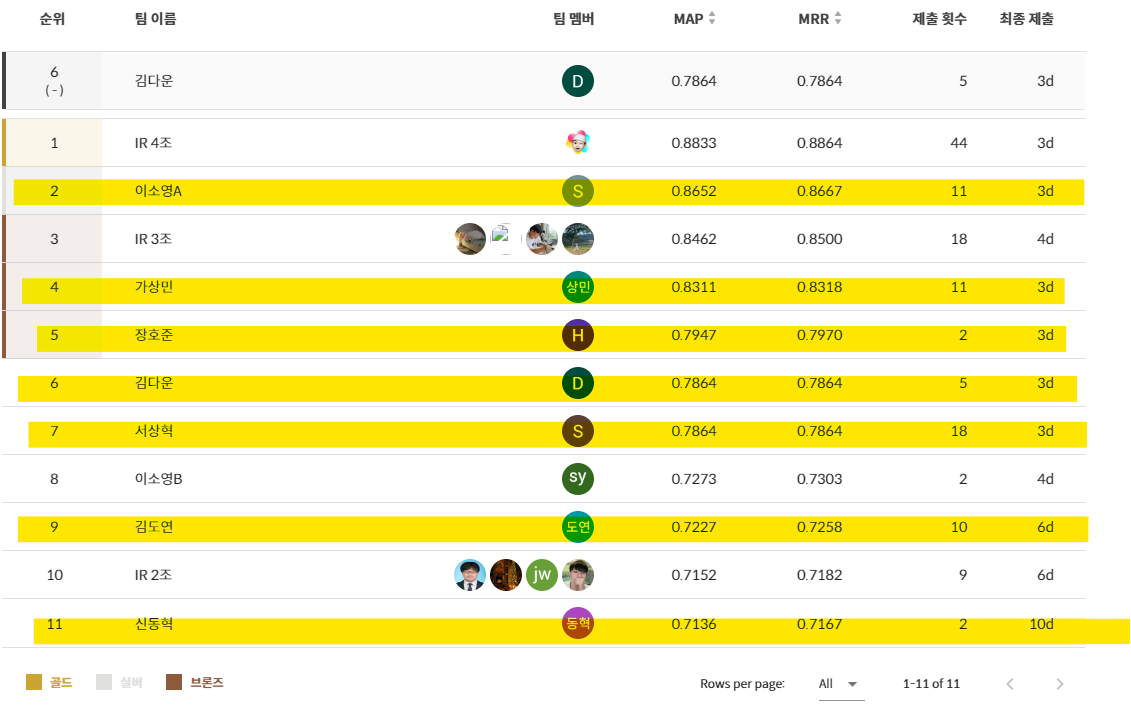
나 스스로의 전략은 강의 내용에서 나왔던 문서를 가져올 때 문서의 개수를 설정할 수 있다. 이 문서의 개수를 조절하였을 때 스코어의 변동성을 조절해 보는 전략이었다. 결과적으로 3개 서치보다는 7개의 서치가 성능이 오른 것을 확인 할 수 있었고, 스스로 진행 했던 프롬프트 엔지니어링은 오히려 성능을 저하하였다.
# RAG 구현에 필요한 Question Answering을 위한 LLM 프롬프트
persona_qa = """
## Role: 과학 상식 전문가
## Instructions
- 사용자가 대화를 통해 과학 지식에 관한 주제로 질문하면 search api를 호출할 수 있어야 한다.
- 과학에 관련된 카테고리는 물리, 화학, 생물, 지구과학 등 여러 분야가 있다.
- 각 분야에 맞춘 단어를 사용하여 대답을 생성하도록 한다.
- 과학 상식과 관련되지 않은 나머지 대화 메시지에는 적절한 대답을 생성한다.
"""
# original
# # RAG 구현에 필요한 Question Answering을 위한 LLM 프롬프트
# persona_qa = """
# ## Role: 과학 상식 전문가
# ## Instructions
# - 사용자의 이전 메시지 정보 및 주어진 Reference 정보를 활용하여 간결하게 답변을 생성한다.
# - 주어진 검색 결과 정보로 대답할 수 없는 경우는 정보가 부족해서 답을 할 수 없다고 대답한다.
# - 한국어로 답변을 생성한다.
# """이러한 원인은 애초에 데이터는 과학으로 분류가 되어있기 때문에 이를 데이터에서 부터 맞춰주지 않았기 때문에 오히려 추가한 문구가 방해를 일으켜 감소했을 것이라 판단된다. 이후엔 실험을 많이 하지 못했지만 추가적으로 실험을 적용해 본다면 데이터 구성을 변화시켜 주제를 세분화 하여 나타낼 수 있을 것 같다.
AD
데이터를 제일먼저 확인하였을 때 칼럼에 대한 정보가 보여지지 않았기 때문에 변수 이름 자체에서 얻을 수 있었던 단서가 희박했다. 따라서 최초로 데이터에 대해 확인하였을 때 변수끼리의 조합을 통해 어떠한 파생변수를 만들어 내는 과정을 진행 할 수 없다 판단하였다.
또한 데이터는 SimulateRun 단위로 sampling이 1번부터 n번까지 연속적으로 진행된 샘플이라 한다. 그러나 sample1과 sample2의 시간 간격이 다른 샘플의 간격과 일치하는지 확인할 수 없었고 따라서 시계열성이 존재한다 하더라도 고려하지 못한다 판단하였다.
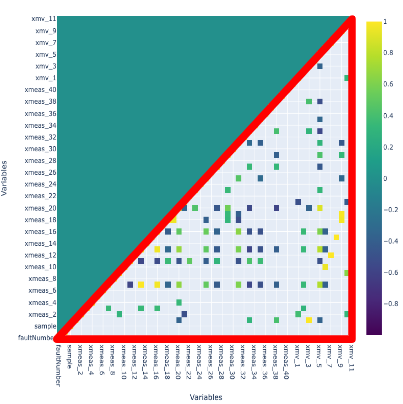
상관관계를 확인했을 때, 상관관계가 존재하는 변수가 있었다. 거의 1과 -1에 가까운 변수도 있었기 때문에 52개의 변수에서 차원을 축소하였을 때 관계가 있는 변수가 존재할 것이라 판단하였고 이를 위해 PCA를 진행하였다.

3차원으로 출력하였을 때 각 주성분에 가장 영향이 있는 변수를 찾아내기 위해 상관계수를 다시 확인한 결과 다음과 같은 변수가 도출되었다.
변수간의 관계를 특정할 수 없지만 직∙간접적으로 반영하여 군집을 형성할 수 있는 k-means 클러스터링 방법론을 활용하였다.
클러스터링 방법은 다음과 같은 순서로 작동할 수 있게 활용하였다.
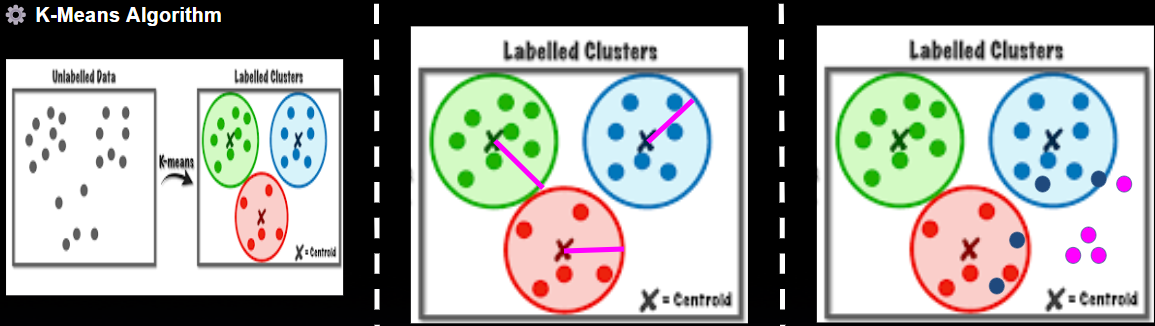
- train데이터를 활용해 elbow, silhouette방법을 활용해 최적의 k의 수를 구한다.
- Best k를 찾아 적합하여 최적의 center 좌표를 찾아낸다.
- 클러스터 안의 센터별 Euclide distance를 구하여 최장거리를 계산한다.
- test데이터와 각 center별 Euclide distance를 구하고 더 작은 거리를 갖는 클러스터를 선택하여 그 거리를 저장한다.
- train에서 계산했던 최장거리보다 크면 이상치, 크지 않으면 정상치로 판단한다.
- SimulateRun 단위로 1개라도 이상치가 된다면 모두를 이상치로 판단한다. 이상치가 하나도 없을땐 정상치로 판단한다.
이러한 알고리즘을 활용하여 다음과 같은 전략을 주로 시도하였다.
- 데이터의 단위를 맞추기 위해 StandardScaling을 적용하였다.
- PCA로 산출한 변수를 연장/적용 하여 모델에 대입하였다.
- 이상치를 만들 때 개수를 5, 10, 100으로 늘려보았다.
거리의 방법을 맨하탄, 마할라노비스와 같은 거리로 바꿔보았다.
결과적으로 나의 모델 중 StandardScaling을 적용한 k-means모델이 성능이 가장 좋게 산출되었다. PCA변수 적용과 이상치를 판단하는 개수를 증가시켰을 때 적용 할 수록 성능이 낮아지는 모습을 보였다. 이상치를 오히려 정상치로 판단하는 경우가 늘어나기 때문에 두가지 방법 모두 지양하기로 하였다.
k-means가 성능이 가장 좋았기 때문에 팀원중 AutoEncoder을 담당한 팀원이 latent value를 구성하는 칸에서 값을 직접 쓰지 않고 k-means로 군집을 적용하여 Decoding을 진행하는 과정을 대입하였을 때 또한 성능이 증가하였다고 확인하였다.
이와는 별개로 팀에서 시도했던 방법이 담긴 모델은 다음과 같다.
Isolation Forest + Optuna
One Class SVM
PCA for SVDD
Autoencoder + K-means
DBscan
KNN
Deep Robust One-Class Classification
AutoEncoder + LSTM
최종적으로 k-means, One Class SVM, PCA를 활용한 SVDD 세가지 모델을 앙상블한 모델이 성능이 가장 좋게 나왔다. 결과를 확인 했을 때 단순한 모델이 성능이 잘 나온 것을 확인했을 때 데이터의 관계가 복잡하지 않을 것이기 때문에 머신러닝 방법이 주로 성능이 좋게 나올 것이라는 의견을 담당해주신 멘토님께서 해주셨다. 따라서 전략적으로 선택한 모델이 가장 큰 의미를 가져오는 결과를 확인할 수 있었다.
k-means를 활용하여 적용시킨 DashBoard를 구성하였다. 구성은 다음과 같다.
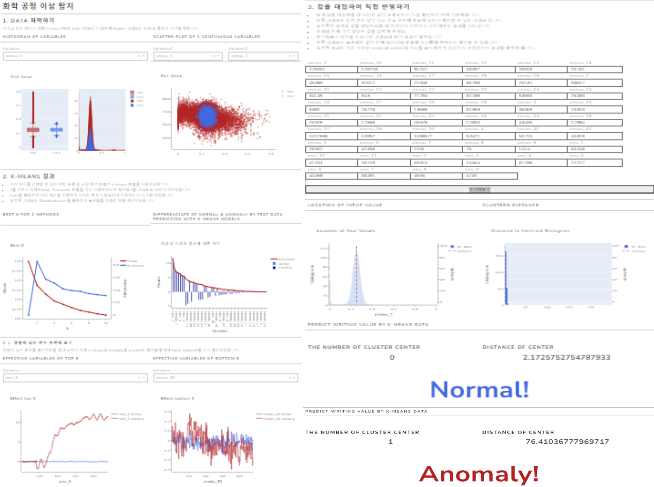
- 데이터 확인을 간단하게 하기 위해 boxplot, histogram, scatter plot을 변수 선택을 자유롭게 하고 그에따른 interactive 출력을 진행하였다.
- 최적의 k를 구할 때 활용했던 지표를 출력하였다.
- k-means에서 가장 영향이 있었던 변수를 크기 순으로 나열하였다.
- test data에서 이상과 정상으로 나타낸 변수들을 비교하였을 때 top5, bottom5를 확인할 수 있게 표시하였다.
- 실제로 값을 대입하여 그 값이 이상치인지 정상치인지 확인할 수 있도록 interactive하게 제작하였다.
최종적으로 다음과 같은 순위를 기록하였다.
5. 자체 평가
새로운 시도
- IR
- 프롬프트 엔지니어링에 대해 이해하고 직접 문장을 작성해 출력해 보았다.
- top k의 개수를 조절하여 성능을 비교하였다.
- Credit에 대해 이해하여 API를 불러오는 과정을 학습하였다.
- 간트차트를 활용하여 전반적인 일정에 대해 계획하고 공유하였다.
- AD
- 이상탐지의 배경에 대해 이해하고 이를 최대한 반영하기 위해 이상치 판단 임계값을 구성하였다.
- 이상탐지에 맞는 k-means알고리즘을 직접 구축하였다.
- 모델의 모듈화를 통해 정리하여 실질적으로 배포할 수 있게 구성하였다.
- Dash를 활용하여 직접 DashBoard를 구성하였다.
- 간트차트를 활용하여 전반적인 일정에 대해 계획하고 공유하였다.
좋은 변화
- IR
- RAG에 대한 전반적인 이해와 간단한 적용을 할 수 있게 되었다.
- 딥러닝에서의 데이터 관점에서 생각할 수 있게 되었다.
- AD
- 단계적 build up하는 방법을 다시한번 깨달을 수 있었다.
- 대회의 목적에 맞는 결과를 출력할 수 있게 되었다.
- 직접 알고리즘을 활용하여 구성하는 방법에 익숙해질 수 있었다.
잘 되지 않은 것
- IR
- 강의에서 나오지 않았던 다른 모델을 활용하는 방법이나 다른 방법을 융합하는 구성을 적용해보고 싶었으나 하지 못했다.
- 전반적으로 BaseLine에 대해 이해했지만 강의 내용에 맞춰 어떤 부분을 수정할지에 대해 어려움이 있었다.
- AD
- 실제로 배포 웹사이트를 구성하지 못했다.
- k-means에서 거리를 변화하여 알고리즘을 구성해보지 못했다. 적용했으면 더 재밌는 결과가 산출 되었을것 같다.
아쉬운 점
- 두가지 대회를 진행하면서 의견 통합과 빌드업이 팀 단위로 이루어지지 않은것 같고 소규모 단위로 이루어진것 같아 용두사미의 느낌을 받았다.
- 실제로 배포하여 활용할 수 있는 MLops를 적용해보지 못하였다.
- 회의를 진행하면서 이탈자가 점차 늘어나는 모습이 생겨 너무 아쉬웠다.
- 만들어둔 노션을 활용하는 경우가 점차 줄어들었다. 따라서 세부사항까지 공유할 수 있지 않았던 것이 너무 아쉽다.
배운점 및 시사점
- IR
- LLM 모델이 생각보다 많은 컨텐츠를 다룰 수 있다는 것을 깨달았다.
- RAG의 전반적인 과정에 대해 이해하면서 학습하였다.
- 다른 조의 발표를 보면서 항상 데이터 탐색이 중요하다는 것을 다시한번 깨달을 수 있었다.
- AD
- 도커 및 aws를 활용하여 배포 환경을 같게 만들어서 배포해야 하는 것을 다시 한번 깨달을 수 있었다.
- 분석 과정을 develop을 진행할 때 탄탄한 근거를 기반으로 분석을 나아가고 내가 의도한 대로 분석 결과가 잘 나오지 않았을 때 그 결과에 대해 원인을 분석할 줄 알아야 한다는 것을 배웠다.
프로젝트를 마치며
최종장인 Final project가 끝이 났다. 진행하면서 재밌게 분석하기도 하였고 알고리즘 구성을 스스로 진행하면서 시간 복잡도에 대해 계속해서 생각할 수 있어서 알고리즘 개발과도 잘 맞을 수 있다는 생각을 해보게 되었다.
그런데 이번에는 팀원의 단합을 보기 쉽지 않았으며 다들 각자의 사정이 있었지만 팀이 아니라 소규모 단위로 k-means처럼 군집화 된 결과물이 나온것 같아 너무 아쉬웠다. 사공이 많으면 배가 산으로 간다는 말이 이럴때 쓰일 수도 있을것 같다.
이번 경험의 아쉬움을 가져가면서 다른 프로젝트를 진행할 때 이러한 상황이 반복될 수도 있다 생각이 든다. 그때마다 아쉬워만 하지말고 이번에 느꼈던 감정을 생각하면서 결과까지 반복되지 않게 중간에 잡는 역할을 다시한번 생각해 보면서 이번 대회를 마무리하려 한다.
