Running PintOS
We've supplied a program for conveniently running Pintos in a simulator, called pintos. In the simplest case, you can invoke pintos as pintos argument.... Each argument is passed to the Pintos kernel for it to act on. Try it out. First cd into the newly created build directory. Then issue the command pintos run alarm-multiple, which passes the arguments run alarm-multiple to the Pintos kernel. In these arguments, run instructs the kernel to run a test and alarm-multiple is the test to run. Pintos boots and runs the alarm-multiple test program, which outputs a few screenfuls of text.
You can log serial output to a file by redirecting at the command line, e.g. pintos -- run alarm-multiple > logfile. The pintos program offers several options for configuring the qemu or the virtual hardware. If you specify any options, they must precede the commands passed to the Pintos kernel and be separated from them by --, so that the whole command looks like pintos option... -- argument.... Invoke pintos without any arguments to see a list of available options. Options includes: how you want VM output to be displayed: use -v to turn off the VGA display, or -s to suppress serial input from stdin and output to stdout. The Pintos kernel has commands and options other than run. These are not very interesting for now, but you can see a list of them using -h, e.g. pintos -h.
시작하기 전에..
1. threads 파일에서source ./activate한 후 build 파일에 들어가기
(맨 처음에 ~/.bashrc에 추가해줬다)
2.pintos -- run \{테스트명}으로 실행
3. 사용중인 프로세스 확인하기ps -f
4.pintos -- -q run alarm-multiple
Alarm Clock
devices/timer.c에 있는 timer_sleep()을 busy wait이 아닌 방식으로 다시 구현한다.
Although a working implementation is provided, it busy waits, that is, it spins in a loop checking the current time and calling thread_yield() until enough time has gone by. Reimplement it to avoid busy waiting.
Suspends execution of the calling thread until time has advanced by at least x timer ticks. Unless the system is otherwise idle, the thread need not wake up after exactly x ticks. Just put it on the ready queue after they have waited for the right amount of time.
busy waiting(busy-looping, spinning)이 꼭 나쁘기만 한 것인지? 어떤 상황에 쓰이면 좋은지?
- 의도적으로 타임 딜레이를 만들고 싶을 때 사용
- SMP 시스템에서 스핀락을 구현할 때 사용
단점- 프로세서가 다른 작업을 할 수 있는 시간이 쓸모없는 데 쓰인다.
low level 프로그래밍에서 쓰이는 경우가 있지만, 실질적인 interrupt 기반 하드웨어 프로세싱에선 쓸모가없다. 하드웨어에 자주 access 하지 않으면 더욱 그렇다.
스레드를 재우고 👉 자는 스레드는 자고있는 스레드 리스트에 추가해 👉 얌전히 자다가 👉 깰 시간이 되면 깨서 일하도록 해 준다.
sleep_list()대기중인 스레드의 리스트를 하나 만들어준다block()으로 대기상태로 들어간 스레드들을 일어날 시간이 되면unblock(), sleeping 리스트에서 제거해주며 ready 리스트에 추가해준다.
Priority Scheduling
When a thread is added to the ready list that has a higher priority than the currently running thread, the current thread should immediately yield the processor to the new thread.
One issue with priority scheduling is "priority inversion". Consider high, medium, and low priority threads H, M, and L, respectively. If H needs to wait for L (for instance, for a lock held by L), and M is on the ready list, then H will never get the CPU because the low priority thread will not get any CPU time. A partial fix for this problem is for H to "donate" its priority to L while L is holding the lock, then recall the donation once L releases (and thus H acquires) the lock.
Implement priority donation. You will need to account for all different situations in which priority donation is required. Be sure to handle multiple donations, in which multiple priorities are donated to a single thread. You must also handle nested donation: if H is waiting on a lock that M holds and M is waiting on a lock that L holds, then both M and L should be boosted to H's priority.
대기하다가 일하러 온 스레드, 새로 생성되서 일 하러 온 스레드, 어떻게 관리해야할까? 천천히 흐름을 보면서 생각해본다. 스레드가 일을 하러 나왔을 때 지금 일하고 있는 스레드보다 우선도가 높다면 프로세서를 선점할 수 있도록 해 준다.
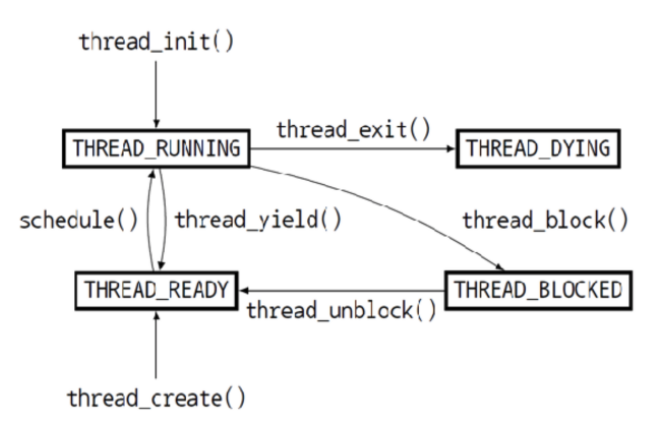
thread_create() 새로 추가된 스레드가 실행 중인 스레드보다 높은 경우 CPU를 선점하도록 하기 위해 수정 해 준다.
test_max_priority()
compare_priority() 두 스레드를 비교해 전자가 높다면 True, else False를 반환하는 콜백 함수를 만들어준다.(내림차순) list_insert_ordered에 사용된다.
thread_unblock() 스레드가 ready_list에 들어올 때 적절한 순서로 들어 올 수 있도록 수정 해 준다.
thread_yield() 우선순위를 반영해 리스트 내 적당한 위치에 자리하게 해 준다.
thread_set_priority() 스레드의 우선도를 변경 할 수 있도록 해주는 함수다. 우선도가 변경 된 후에 정리 될 수 있도록 수정해준다.
Synchronization
Semaphore(세마포어)
동시에 서로 다른 프로세스 혹은 스레드가 공유 자원에 접근하면 충돌이 발생하기 때문에 이를 막아줘야 한다. 이 공유 데이터가 존재하는 영역을 critical section(임계 구역)이라고 하며, 하나의 스레드가 여기에 들어와 작업하고 있으면 다른 스레드들은 줄 서서 기다리고 있어야 한다. 이를 해결하기 위해 추상화한 개념이 세마포어(semaphore)이다. 세마포어는 추상 자료형(ADT)으로, 정수 형태(non-negative) 변수이며 두 가지 연산 : P연산(세마포어 변수 값을 획득)과 V연산(세마포어를 다 쓰고 반납)으로 접근이 가능하다.
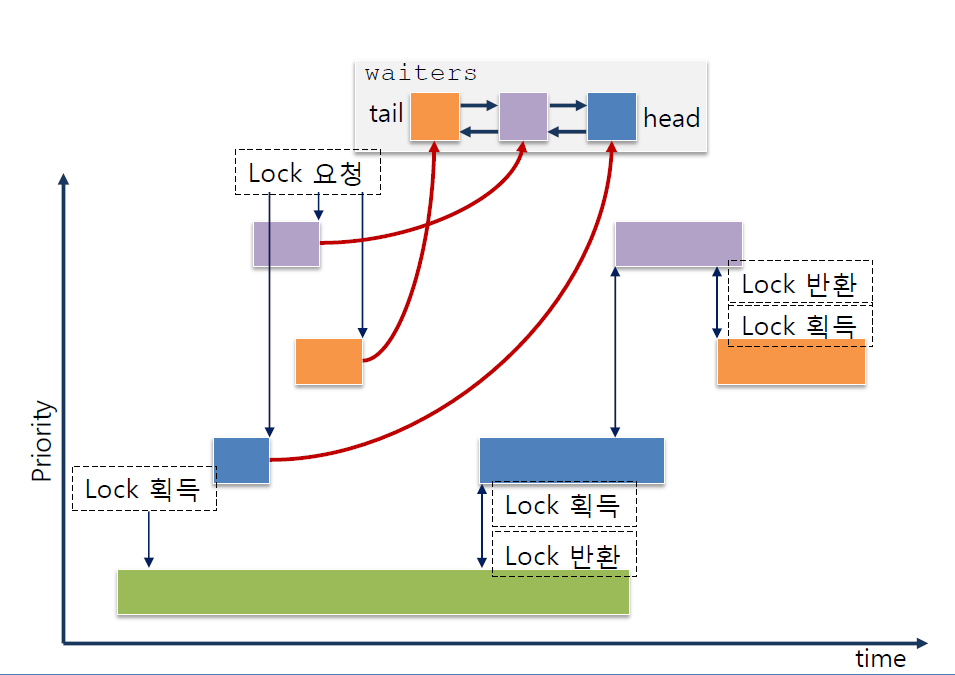
위의 스케줄링 방식은 우선도를 무시하고 waiters list에 삽입되는 순서대로 lock을 획득하는 FIFO 방식으로 구현되어있다.
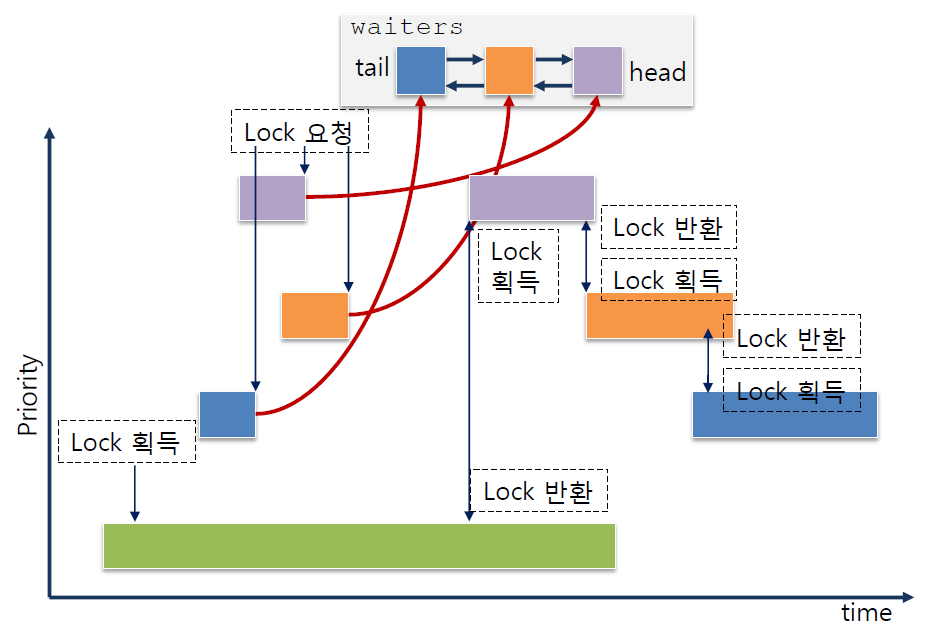
기존의 FIFO 방식을 바꾸기 위해 함수들을 추가하고 수정해준다.
sema_down()(V연산)을 통해 semaphore를 요청하면 waiters 리스트가 우선순위로 정렬 되도록 수정한다. 스레드의 우선도가 아닌, 세마포어 두 개를 받아 해당 세마포어를 품고(?)있는 스레드를 가져와 그 스레드의 우선도에 접근해야 한다. 콜백 함수를 따로 만들어준다.sema_up()waiters 리스트에 있는 스레드의 우선순위가 변경됐을 경우를 고려해 우선도 기준 내림차순 정렬하기 위해list_sort를 추가 해 준다.cond_wait()wait 리스트에 스레드를 대기시키는 함수다. 우선순위를 기반으로 줄을 세워주기로 수정해야 하니list_insert_ordered로 바꿔준다. 이때, 줄 서 있는 요소는 semaphore elem이니 위에서 만든 세마포어 대상 비교 함수를 사용해준다.cond_signal()waiters 리스트를 정렬하고 리스트 맨 앞에있는(우선도 가장 높은) 스레드에 대해 sema_up()을 해준다.
Priority Donation
Priority Inversion Problem 우선도가 높은 스레드가 우선도가 낮은 스레드를 기다리는 현상
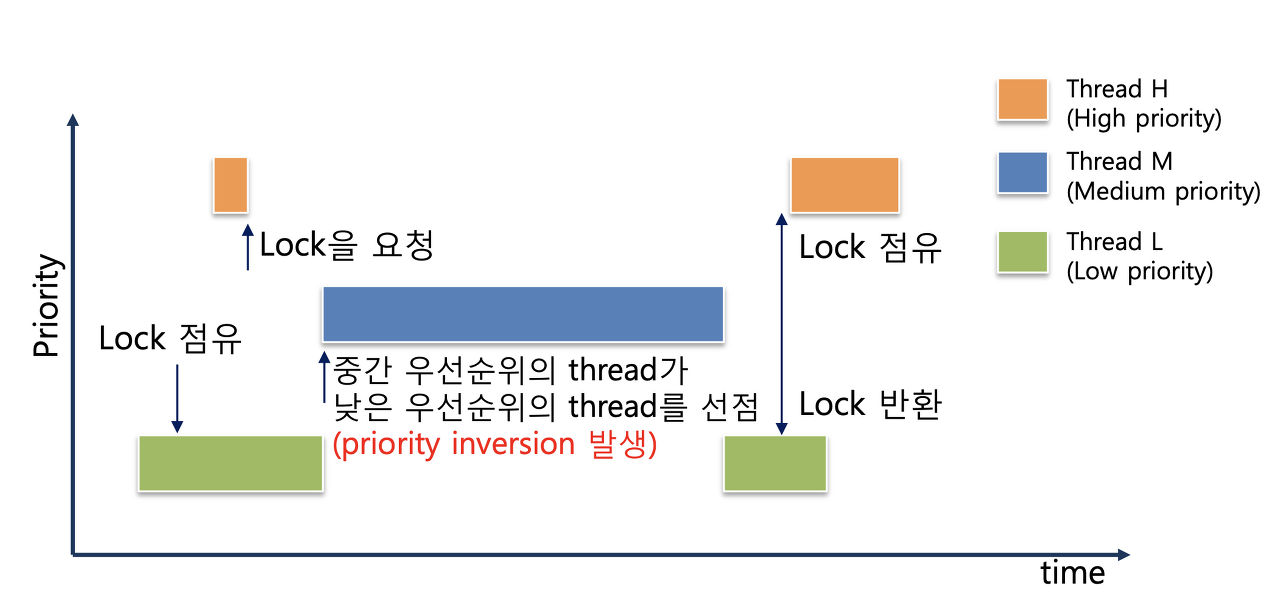
H: High - 우선도 높음
M: Mid - 우선도 중간
L: Low - 우선도 낮음
세개의 스레드가 있고, L이 프로세서와 공유자원을 선점하고 있다고 가정하자.
1. 위에서 priority 기반으로 프로세서를 선점하는 기능을 추가했기에 H가 온다면 프로세서를 선점하게 되고 L은 ready리스트로 밀려나게 된다. 하지만 프로세서와 별개로 공유자원에 대한 접근 권한은 아직 L에게 있다. 따라서 H는 공유자원을 쓰기 위해 waiters 리스트에 들어가게 된다.
- M이 출현해 L과 우선도를 비교해 프로세서를 점유하게 되는데, M은 L과 다른 공유자원을 쓴다. 따라서 M은 L처럼 waiters 리스트에 밀려가지도 않고 작업을 문제없이 수행하게 된다.
이와 같은 상황들이 반복돼 가장 우선도가 높은 스레드가 작업을 하지 못하는(starve) 상황이 발생 할 수도 있게 된다. 이런 상황은 Priority Donation으로 해결 할 수 있다.
H가 Lock을 요청할 때 L에게 자신의 우선도를 빌려주는 것이다. 그러면 L은 M에게 밀리지 않고 작업을 완료 할 수 있으며, 작업이 끝나면 H가 뒤를 이어 프로세서를 점유해 작업을 진행 할 수 있다.
Multiple Donation
Multiple Donation은 말 그대로 도네이션이 여러 번 발생하는것을 말한다. 이번에는 하나의 스레드가 두 개의 공유 자원에 접근하기 위해 Lock A, Lock B 라는 두가지 Lock을 점유해야 하는 상황이라고 가정해보자. L이 Lock A를, M이 Lock B를 각각 요청할 때, L은 자신이 가지고 있는 Lock을 요청한 모든 스레드에게 우선도를 기부받고, 이 중 가장 높은 L의 우선도가 같아진다.

Nested Donation
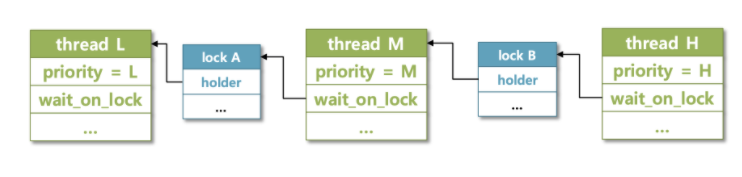
Nested Donation은 도미노처럼 H,M,L이 서로 연이어 우선도를 기부하고, 받는 경우이다.
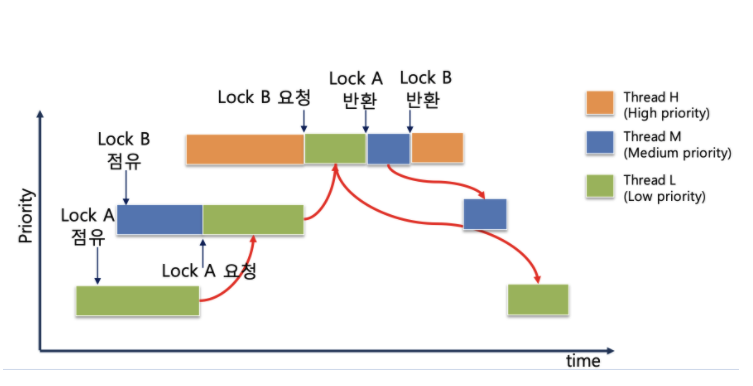
- L 스레드가 Lock A를 점유하고 작업을 하던 도중 M스레드가 온다.
- M 스레드의 우선도가 더 높고, 다른 Lock을 점유하고있으니 CPU는 M이 선점한다.
- M이 Lock A를 요청하면 M이 L에게 우선도를 줘 L->priority == M->priority가 된다.
- Lock A는 L이 잡고있었으니 프로세서는 L이 점유하고 L이 작업을 시도한다.
- H가 들어온다. H는 프로세서를 가지고 작업을 하다가 Lock B를 요청하는데, Lock B는 M이 잡고있었고 M은 Lock A를 기다리고 있던 상황이라 L이 Lock A를 반환해야 상황이 종료된다.
- 이 경우, M과 L 둘다 H와 동등한 우선도를 가지게 된다.
struct thread스레드 구조체에 해당 스레드가 어떤 lock을 점유하고있는지 물고 있을 수 있도록 변수를 만들어준다.- 그리고 스레드마다 자신에게 우선도를 기부한 스레드들을 추적 할 수 있도록 donors 리스트와 donation_elem을 만들어준다.
lock_acquire()만약 현재 필요한 lock을 다른 스레드가 점유하고 있다면 우선도를 기부해 선점당하지 않고 작업을 빠르게 마무리 지을 수 있도록 해 준다.donate_priority()lock을 점유하고 있는 스레드에게 우선도를 기부하는 함수인데, nested donation이 필요한 경우가 생길 수 있으니, 위에 있는 그림 처럼 H는 M에게, M은 H와 동등해진 우선도를 L에게 줘 L이 우선적으로 작업을 마무리하고 나올 수 있도록 해 줘야한다.lock_release()sema_up()을 하면서 lock을 놓으면, 자신에게 우선도를 기부한 스레드들의 리스트를 비워주어야 한다.
Q & A
Q. intr_context()에 대해
A.
- intr_context() 함수는 외부 interrupt가 활성/비활성 되었는지 확인 하는 함수가 아니라, 현재 일반 코드를 실행 중인지 아니면 interrupt handler를 실행 중인지 확인하는 함수다.
- PintOS는 하나의 interrupt handler가 실행 중일 때는 interrupt가 자동으로 꺼져서 다른 interrupt handler가 실행되지 않도록 설계되었습니다. 따라서 interrupt handler 안에서는 interrupt를 다시 켜면 안 되고,
intr_enable()함수 안에ASSERT (!intr_context ())문이 있는 것입니다.- 잠들어 있는 스레드를 깨우는 일은 timer interrupt의 interrupt handler 안에서 수행됩니다. 그러므로
thread_awake()혹은 다른 interrupt handler 코드에서intr_enable()을 해서는 안 되고,intr_disable()을 할 이유가 없습니다(이미 interrupt가 disable되어 있으므로).- interrupt를 자동으로 끄고 켜는 기능은 직접 코드로 구현되어 있지 않고, 하드웨어가 담당합니다. 인터럽트가 발생할 경우 CPU에서 자동으로 Interrupt Flag를 clear하게 됩니다.
Q. 새로운 소스파일을 추가했을 때 Makefile을 수정하는 방법
A. .c 파일을 추가하려면targets.mk을 수정해야 한다.dir_SRC에 새로운 파일을 추가해주고 make를 실행해준다.
Q. lock이 풀리면 어떤 스레드가 다음으로 들어가야하나?
A. lock이 풀리면, 해당 lock을 기다리고 있던 우선도가 가장 높은 스레드가 unblock 되어 ready리스트에 들어가야 한다. 그리고 프로세서는 ready 리스트 중에서 가장 우선도가 높은 스레드를 골라 작업을 시킨다.
Review
많은 양의 파일과 코드를 살펴봤다. 서로 얽히고 얽힌 레퍼런스들을 파고들어가야해서 처음엔 정말 어질어질했다. 무작정 파일을 열어보지 말고 먼저 디렉토리의 구조를 파악하고, 어떤 파일들이 있는지 확인하는 순으로 차근차근 접근 해야 한다는 것을 느꼈다. 특히 Pintos 처럼 많은 파일이 있는 경우에!
코치님과 지난 몇주간 했던 프로젝트에 대해 대화를 했는데, 잘 설명을 하지 못했다. 현재 풀어가고있는 문제 뿐만 아니라 최근에 해결했던 문제들도 한번씩 복기하는게 좋을 것 같다. 복습이 될 뿐만 아니라 현재 풀고있는 문제에 대한 단서를 얻을수도 있지 않을까?
바로 코드로 작성 할 수 있게 명확하게 말하는 방식(?)에 대해 고민 해 봤다.
권영진 교수님의 강의 키워드들
- mmap, map size, map anonymous/ private
- ABSTRACTION (abstraction of address space, storage)
- Buffer cache - problems - consistency; atomicity & durability
- Isolation
- Page Fault handler, Demand Paging
- Demand Paging
- Hierarchical Page table
- fsync와 crash consistency
- Radix tree와 RB트리가 쓰이지 않을 이유
- 존 아우스터하우트 교수의 Philosophy of software design 이라는 동영상을 찾아보았다.
