📝Today I learned
🚀 TIL 목차 🚀
1) Pandas로 api 정보 추출하기
- 라이브러리 불러오기
- url 설정(api) network > Headers > 복사
- pandas로 json 데이터 요청하기
- 요청한 json 데이터를 df로 만들기
2) requests로 api 정보 추출하기
- reqeusts로 HTTP 요청하기
- response를 JSON 타입으로 받기
- JSON 데이터에서 원하는 정보 찾기
- 원하는 정보를 df로 만들기
- 데이터 확인하기
3) 오늘날짜로 파일명 정하고 저장
JSON 타입 API 정보 웹 스크래핑
1) Pandas로 api 정보 추출하기
🔹 라이브러리 불러오기
import pandas as pd # 데이터 분석
import numpy as np # 수치계산
import requests # http 요청🔹 url 설정하기
url = "https://finance.naver.com/api/sise/etfItemList.nhn?etfType=0&targetColumn=market_sum&sortOrder=desc"
print(url)- url 찾는법
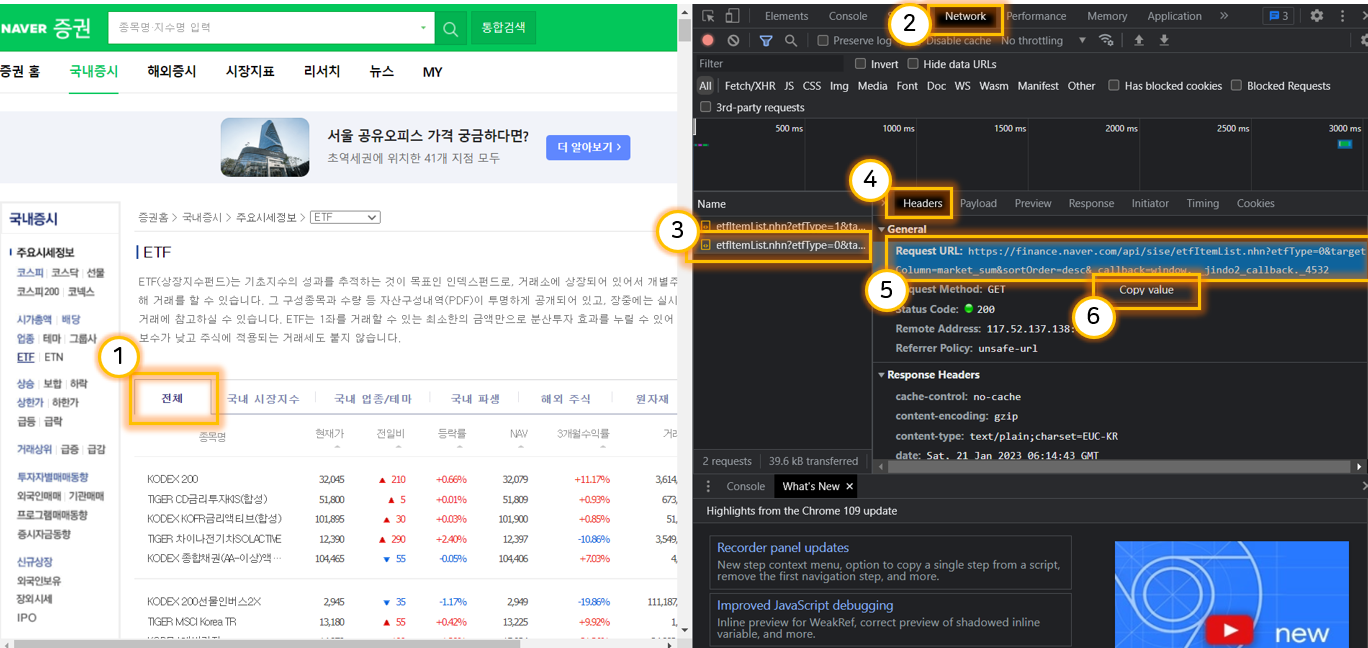
- 얻으려는 정보를 마우스 우클릭 > 검사(Inspect) 클릭
- Network 탭 클릭
- 얻으려는 정보에서 '전체', '국내시장지수' 등 탭 클릭하면 그에 해당하는 3번 목록이 나타남. 그 목록 클릭
- Headers 탭 클릭(기본적으로 나타나기 때문에 별도 클릭 필요 없을 수도 있음)
- 'Request URL' 우클릭
- '복사하기' 클릭
- url을 클릭하면 아래와 같은 화면이 나옴
🔹 Pandas로 JSON 데이터 요청하기
display(pd.read_json(url, encoding="cp949"))
display(pd.read_json(url, encoding="cp949").loc["etfItemList", "result"]) # "etfItemList" 행, "result" 열의 데이터 추출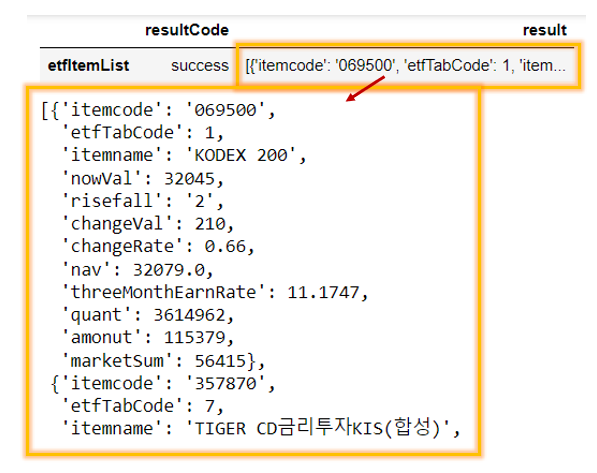
🔹 요청한 JSON 데이터를 df로 만들기
result = pd.read_json(url, encoding="cp949").loc["etfItemList", "result"]
pd.DataFrame(result).head()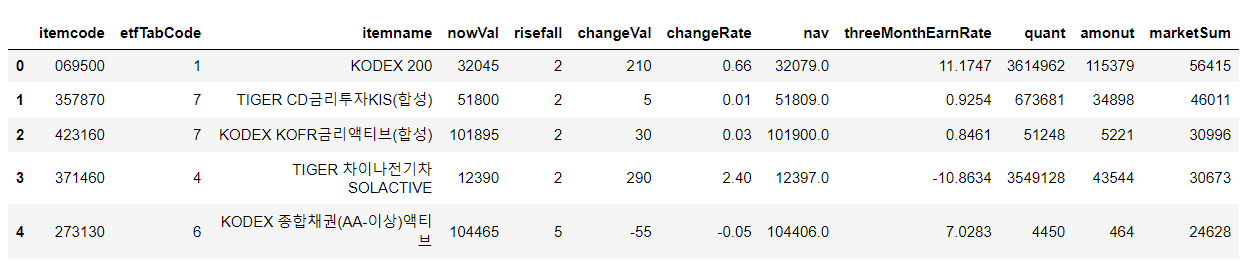
=> 결론: API를 통한 데이터 수집이 이렇게 쉽습니다!!!
2) requests로 api 정보 추출하기
🔹 reqeusts로 HTTP 요청하기
response = requests.get(url)
response.status_code # '200'이 나온다면 요청 성공🔹 response를 JSON 타입으로 받기
etf_json = response.json()
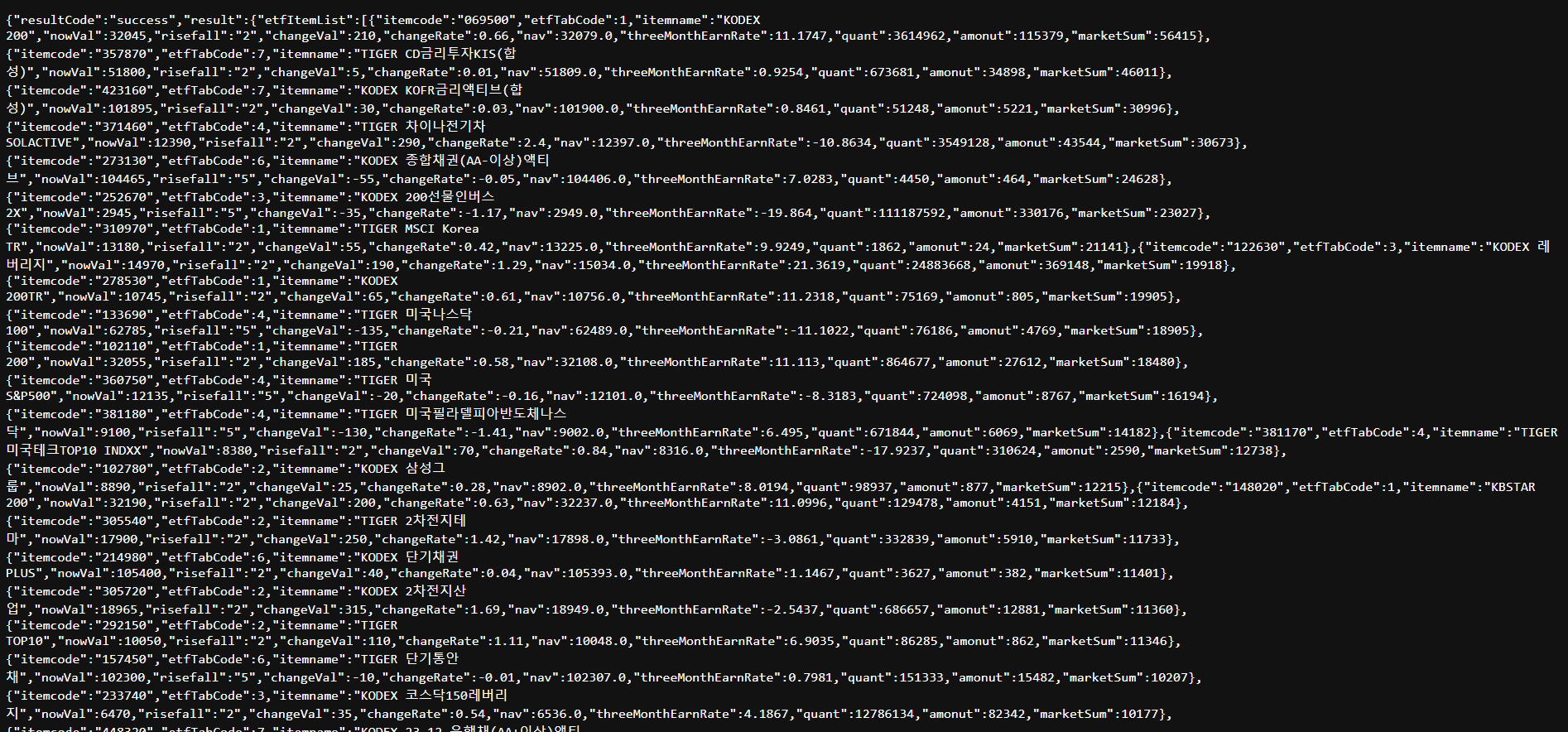
etf_json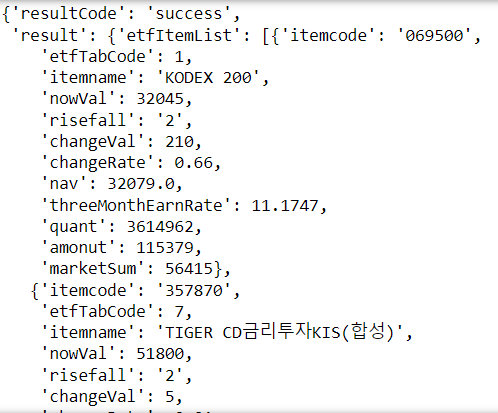
type(etf_json) # dict: 결과값에서 중괄호와 대괄호가 많이 나와 헷갈려서 타입을 출력해보았다. etf_json의 타입은 딕셔너리! key 값은 'resultCode'와 'result'이다.
여기서 'result' key 값의 value 값은 다시 딕셔너리 형태이고, 그 안의 'etfItemList'라는 key 값의 value 값은 리스트이다. 그 리스트 안에 또 딕셔너리가 있다..!
🔹 JSON 데이터에서 원하는 정보 찾기
etfItemList = etf_json["result"]
etfItemList
# type(etfItemList) # dictionary
etfItemList = etf_json["result"]["etfItemList"]
# 위에서 Pandas를 통해 구한
# pd.read_json(url, encoding="cp949").loc["etfItemList", "result"]
# 위의 코드와 동일한 결과를 출력
# type(etfItemList) == list
etfItemList
=> 마치 러시안 인형처럼 딕셔너리 key값 2번 입력하여 최종적으로 리스트 출력! 이 리스트의 요소들은 딕셔너리로 구성되어 있음.
🔹 원하는 정보를 df로 만들기
df = pd.DataFrame(etfItemList)
df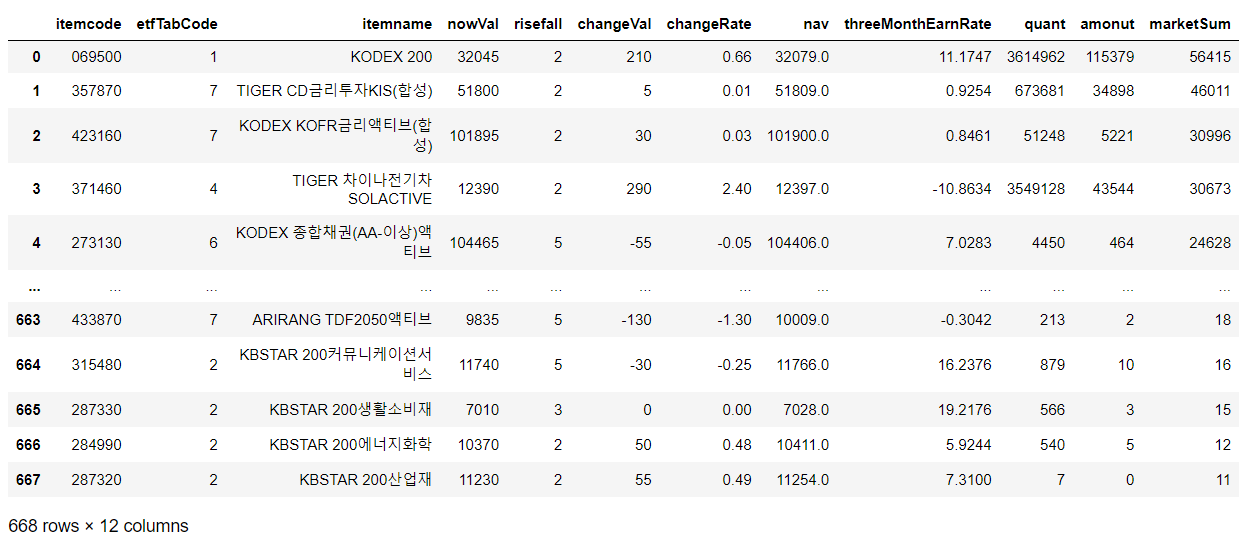
🔹 데이터 확인하기
df.info() # df의 전반적인 정보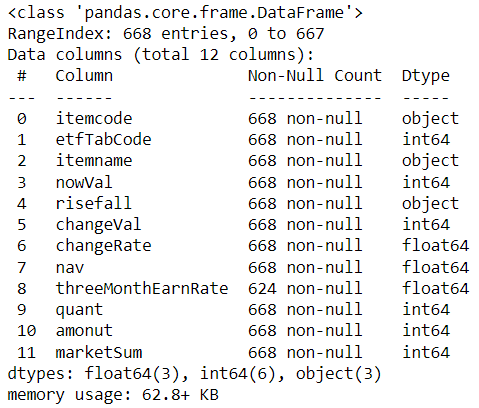
display(df.describe())
display(df.describe(include="O"))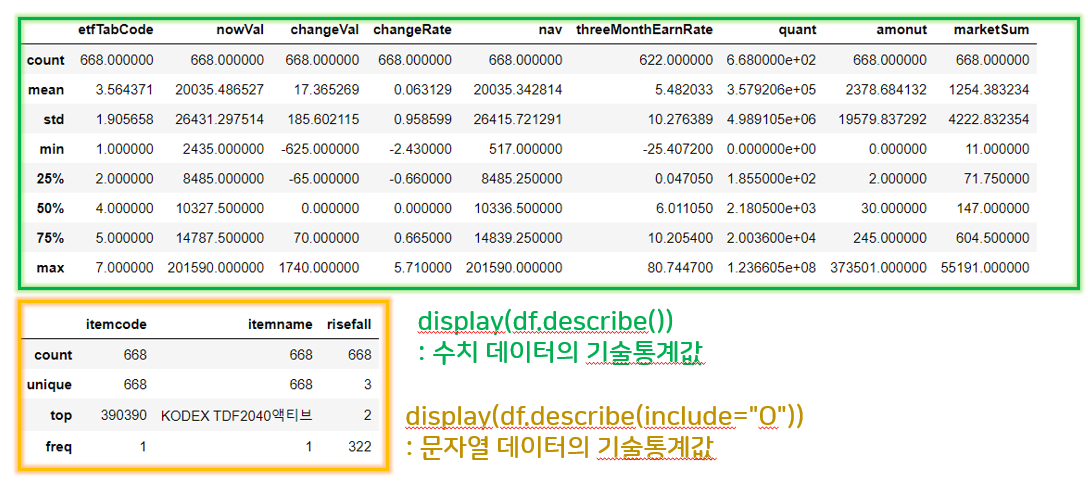
# 오늘(23-01-21) 가장 크게 오른 종목
df[df["changeRate"] == df["changeRate"].max()]
# 시가 총액 상위 5개 종목
df.nlargest(5, "marketSum", keep="first")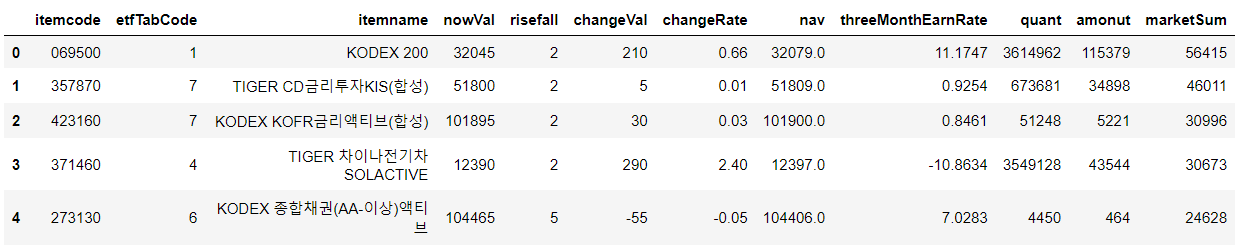
- nlargest : Return the first n rows ordered by columns in descending order.
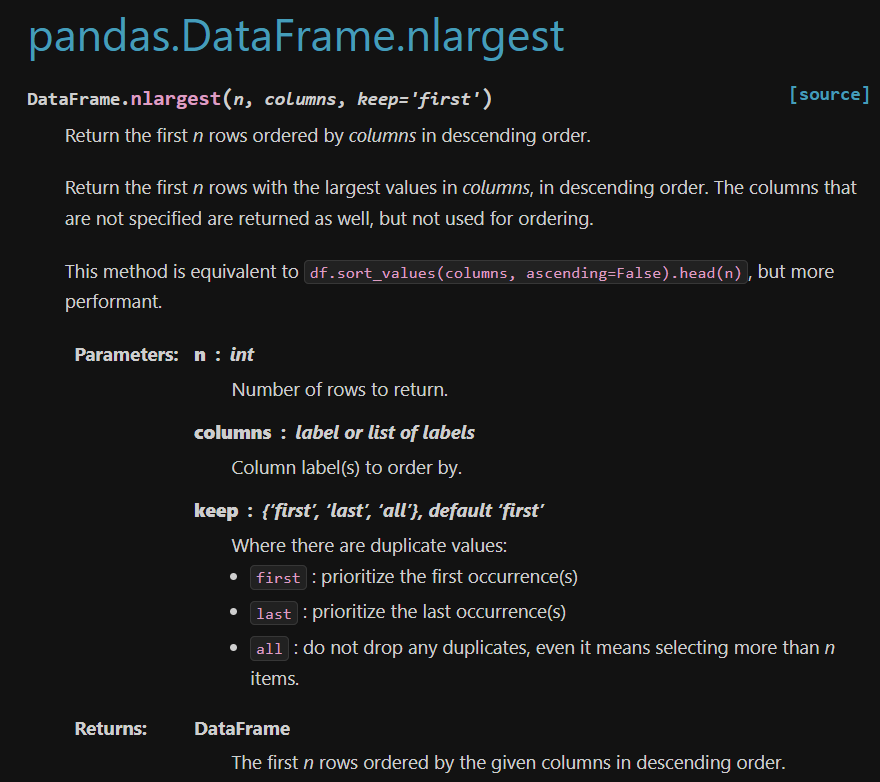
(참고: pandas nlargest document https://pandas.pydata.org/docs/reference/api/pandas.DataFrame.nlargest.html)
3) 파일로 저장하고 불러오기
🔹 오늘 날짜 구하기
: 데이터를 수집하고 저장할 때마다 "수집 날짜"를 파일명으로 정하면 편하니까!
from datetime import datetime
today_date = datetime.today().strftime("%Y-%m-%d")
today_date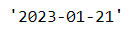
🔹 파일명 만들기
file_name = f"etf-{today_date}.csv"
file_name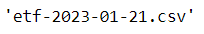
🔹 파일로 저장 및 불러오기
df.to_csv(f"data/{file_name}", index=False)
# data 폴더 안에 저장하도록 경로 지정pd.read_csv(file_name, dtype={"itemcode": "object"})
# 종목코드에서 숫자 맨 앞의 0이 지워지는 현상을 막기 위해
# dtype={"itemcode": "object"} 로 타입을 지정하면 문자형태로 읽어옴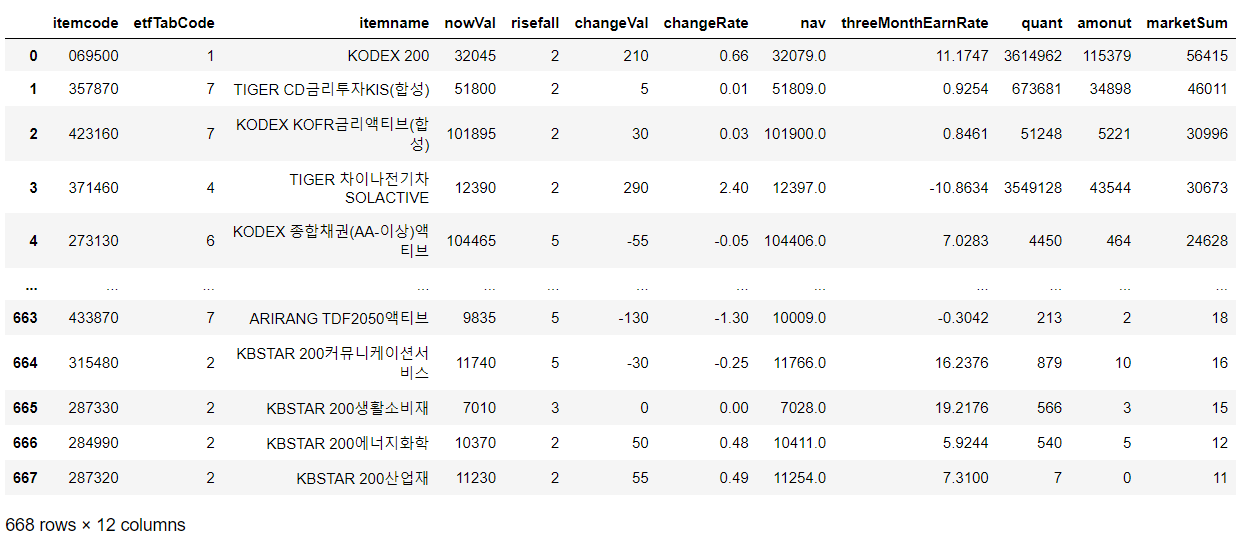
특별편) 내가 아직도 헷갈리는 것들 모음집.zip
🔹 df에서 행과 열 조회하기
# 행 조회하기 => loc활용
# 대괄호가 하나면 '시리즈', 두 개면 '데이터프레임'타입으로 결과값 출력
# 1. 문자열 행명 인덱스가 없는 경우
# 1-1. 하나의 행 추출
df.loc[숫자] #series
df.loc[[숫자]] #dataframe
# 1-2. 여러 행 추출
df.loc[숫자:숫자] #dataframe
df.loc[[숫자, 숫자]] #dataframe
# 2. 행명 인덱스가 있는 경우
# 2-1. 하나의 행 추출
df.loc['행명(인덱스명)'] #series
df.loc[['행명(인덱스명)']] #dataframe
# 2-2. 여러 행 추출
df.loc['행명(인덱스명)1':'행명(인덱스명)2'] #dataframe
df.loc[['행명(인덱스명)1', '행명(인덱스명)2']] #dataframe# 열 조회하기
# 1. 하나의 열 추출
df['열명'] #series
df[['열명']] #dataframe
# 2. 여러 열 추출
df[['열명1','열명2']] #dataframe# 행과 열 조회하기
df.loc['행명', '열명']
df.loc[['행명1','행명2'], ['열명1','열명2']](참고 링크: pandas loc document
https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.DataFrame.loc.html)
🔹 dictionary 타입을 인덱싱하기
: 딕셔너리를 키값(key) 으로 인덱싱함!!
Dic['Key명']❗이것만은 외우고 자자 Top 3
📌 API 정보 추출하는 방법 2가지 : pd.read_json, response.json()
📌 상위 n개 값 구하기 : df.nlargest(n, columns, keep='first')
📌 오늘 날짜 구하기 : datetime.today().strftime("%Y-%m-%d")
🌟데일리 피드백
1. 오늘의 칭찬&반성
와 진짜 너무 어려웠다. 지금까지 들었던 수업 중에서 최고 어려웠다. 거의 중간에 정신을 놓은 순간이 많았는데... 분명 그랬는데.. 그래서 더 복습을 천천히 했다. 시간이 엄청 오래 걸리긴 했지만 다시 보니 그렇게 어려운 내용이 아니었다. 아무리 어려운 내용이라도 카테고리를 나눠서 내가 지금 뭘 배우고 있는지 항상 생각하고 공부를 하면 그렇게 어렵지 않다. 천천히 복습하길 잘했다.
2. 내가 부족한 부분
df에서 행과 열을 조회하는 것이 아직 너무 헷갈린다. 대괄호를 몇 번써야 하는지, loc를 써야하는지, iloc를 써야하는지, 인덱스명이 있을 때와 없을 때 차이가 있는지 등등... 얼른 규칙을 찾아서 머리에 딱 집어넣어야겠다.
3. 내일의 목표
미니 프로젝트 일단 한 개부터 도전하기
