📝Today I learned
🚀 TIL 목차 🚀
1) API와 XML
- API
- XML
2) Open API로 '서울 열린데이터 광장' 데이터 수집하기
- 라이브러리 로드
- 인증키를 활용해 샘플 xml 링크 만들기
- requests로 xml 링크 결과 받아오기
- pandas로 결과 확인하기
3) 데이터 전처리하기
- 정보의 종류에 따른 데이터 프레임 분리
- FAQ_SEQNO와 LCODE 열의 데이터를 정수형으로 변경
- UPDATE_YMDHMS열의 데이터를 날짜형으로 변경
4) FAQ 내용 수집 연습하기
- url 만들기
- pandas로 url 결과 받아오기
- 특정내용 읽어오기
- 내용 수집 함수 만들기
- 목록과 내용 합치기
Open_API로 데이터 수집하기
1) API와 XML
🔹 API
: Application Programming Interface
: 서로 다른 소프트웨어끼리 서비스를 제공하기 위한 사양
: 서버에 정보를 요청하기 위한 방법
🔹 Open API
: 누구나 사용할 수 있도록 공개된 API
🔹 XML
: eXtensible Markup Language
: 인터넷 상에서 구조화된 데이터를 전송하기 위해 만들어진 형식
: 주로 다른 종류의 시스템, 특히 인터넷에 연결된 시스템끼리 데이터를 쉽게 주고 받을 수 있음
2) Open API로 '서울 열린데이터 광장' 데이터 수집하기
- '서울 열린데이터 광장'에서 수집할 페이지
: https://data.seoul.go.kr/dataList/OA-1127/S/1/datasetView.do
🔹 라이브러리 로드
import pandas as pd
import requests
from bs4 import BeautifulSoup as bs🖐 Pandas 버전 확인 🖐
📍 read_xml 사용을 위해선 pandas 1.3.5 이상의 버전을 사용해야하므로 필요한 경우 아래의 코드를 실행할 것!
#판다스 버전 확인
pd.__version__
# 최신 버전으로 판다스 업그레이드
!pip install --upgrade pandas🔹 인증키를 활용해 샘플 xml 링크 만들기
-
샘플 xml 링크 위치
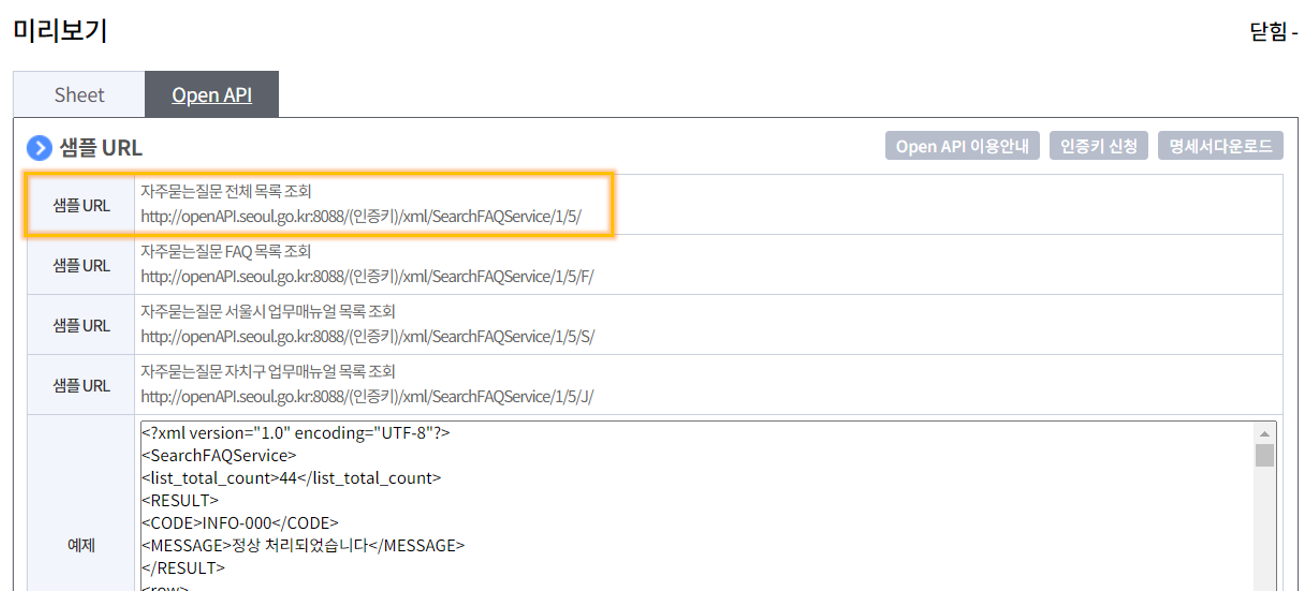
-
샘플 xml 링크: http://openapi.seoul.go.kr:8088/sample/xml/SearchFAQService/1/5/
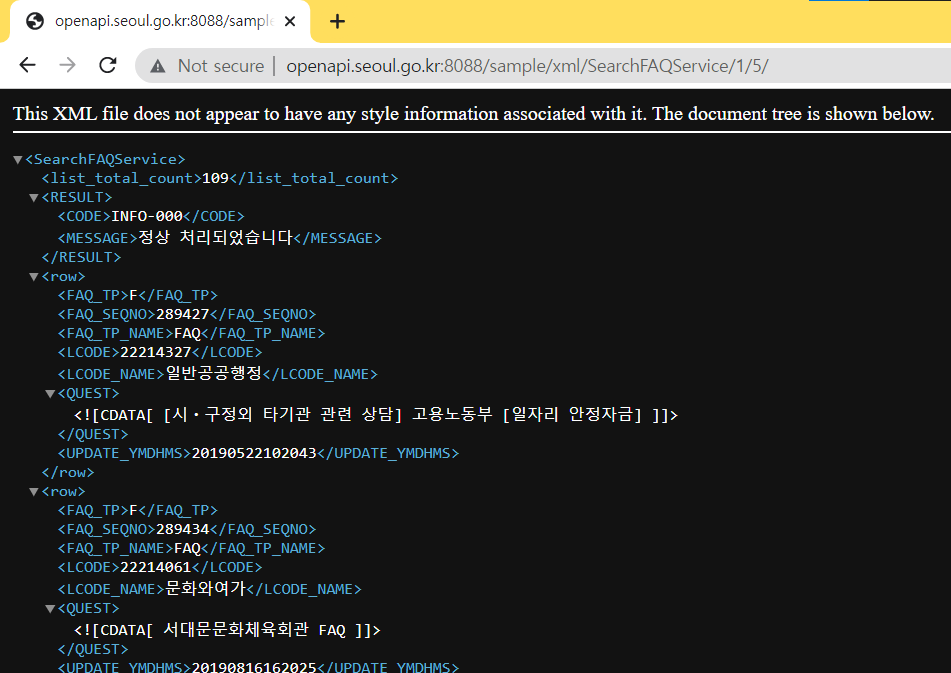
# 인증키(보안을 위해 비식별 처리하였습니다.)
auth_key = "##############################"
# 발급받은 인증키를 요청할 url에 담기
# 최대한 많은 데이터를 수집하기 위해 1부터 999페이지까지 수집하는 것으로 변경
faq_url = f"http://openAPI.seoul.go.kr:8088/{auth_key}/xml/SearchFAQService/1/999/F"🔹 requests로 xml 링크 결과 받아오기
result = requests.get(faq_url)
print(result.text)
🔹 pandas로 결과 확인하기
df_list_all = pd.read_xml(result.text)
df_list_all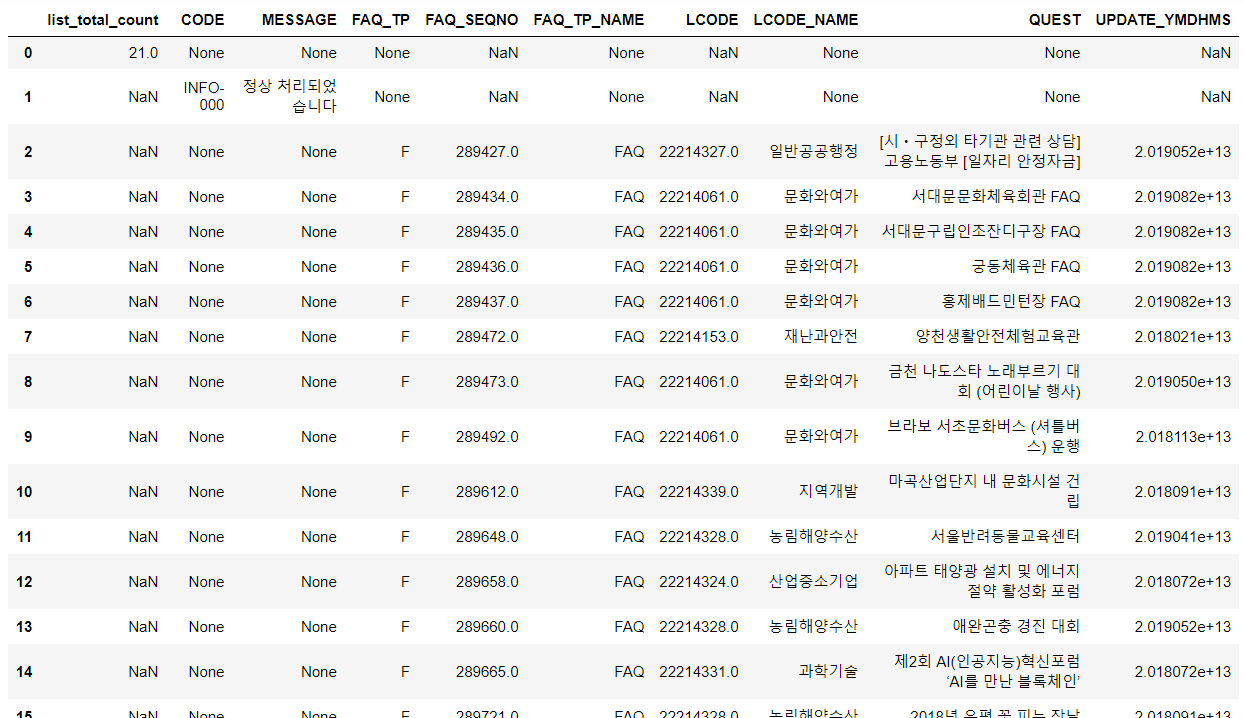
3) 데이터 전처리하기
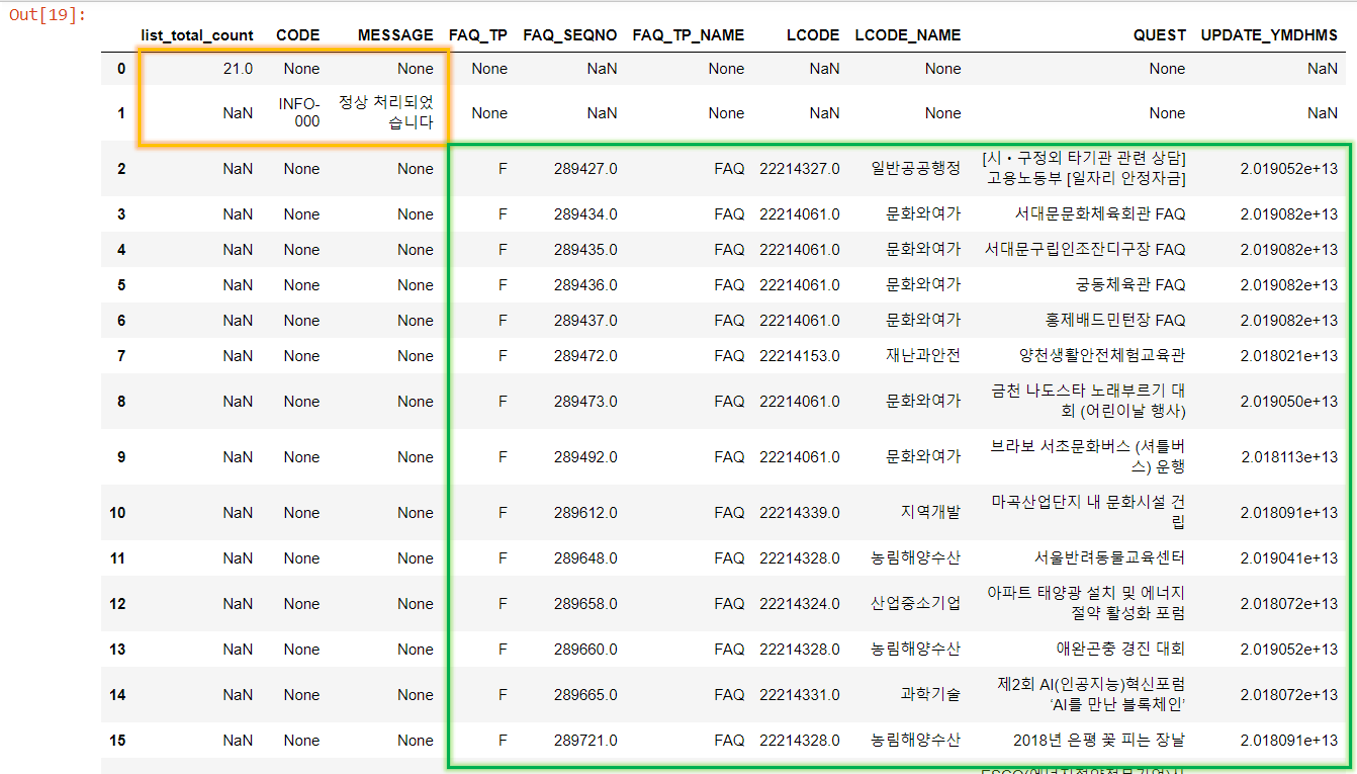
: 주황색 네모는 request에 대한 정보가 담겨있는 열
: 초록색 네모는 request 요청에 대한 내용이 담겨있는 열
=> 성질이 다른 열이 하나의 데이터 프레임에 담겨 결측치가 많이 생겼기에 데이터 프레임 분리 필요
🔹 정보의 종류에 따른 데이터 프레임 분리
df_list_status = df_list_all.iloc[:2, :3]
df_list_status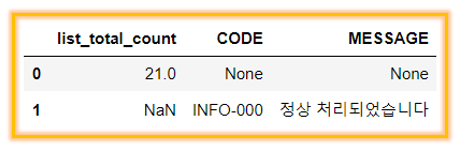
df_list_content = df_list_all.iloc[2:, 3:]
df_list_content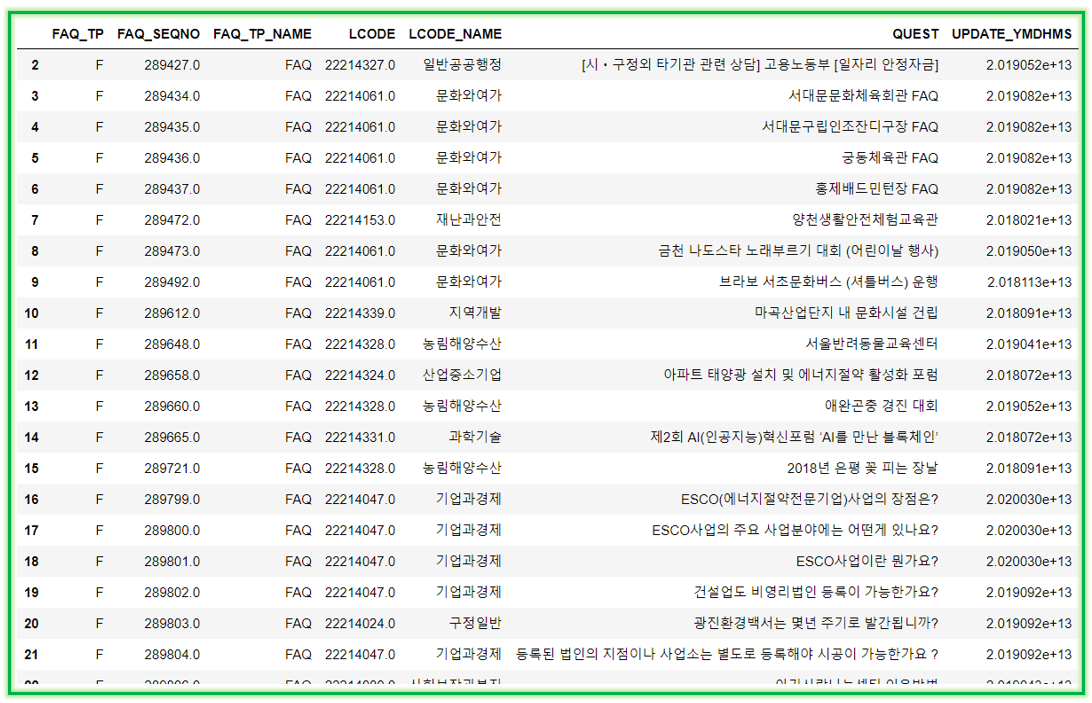
🔹 FAQ_SEQNO와 LCODE 열의 데이터를 정수형으로 변경
df_list_content = df_list_content.astype({'FAQ_SEQNO':'int', 'LCODE':'int'})
df_list_content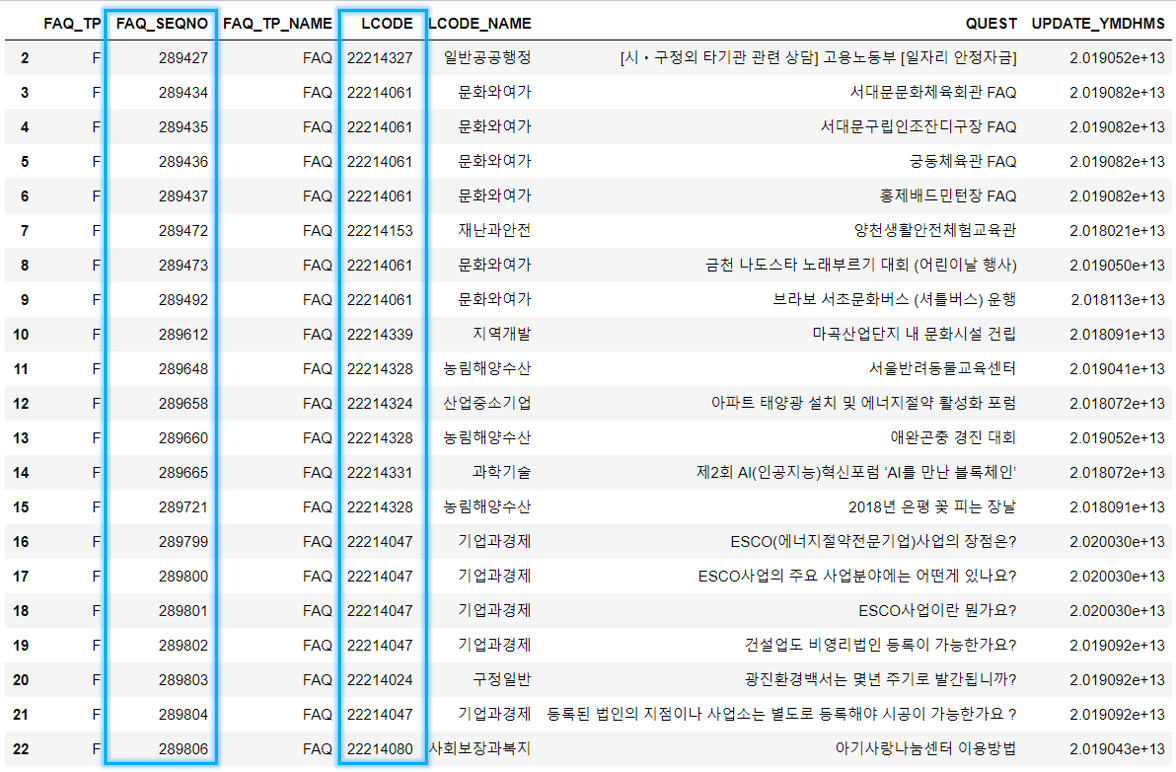
🔹 UPDATE_YMDHMS열의 데이터를 날짜형으로 변경
df_list_content["UPDATE_YMD"] = pd.to_datetime(df_list_content["UPDATE_YMDHMS"].astype(str).str[:14])
df_list_content- 13자리만 가져오기 위해 문자열로 변경 후 pd.to_datetime 매서드 적용
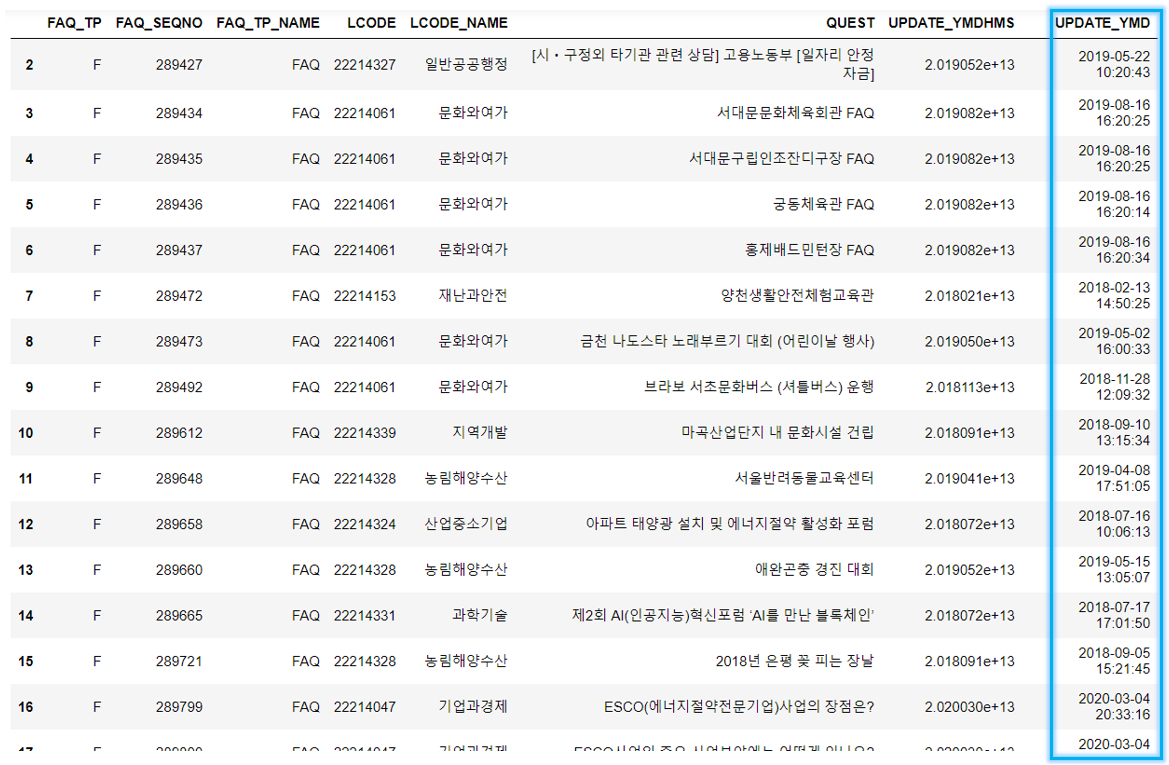
🔹 불필요한 UPDATE_YMDHMS열 삭제
df_list_content = df_list_content.drop(['UPDATE_YMDHMS'], axis=1)
df_list_content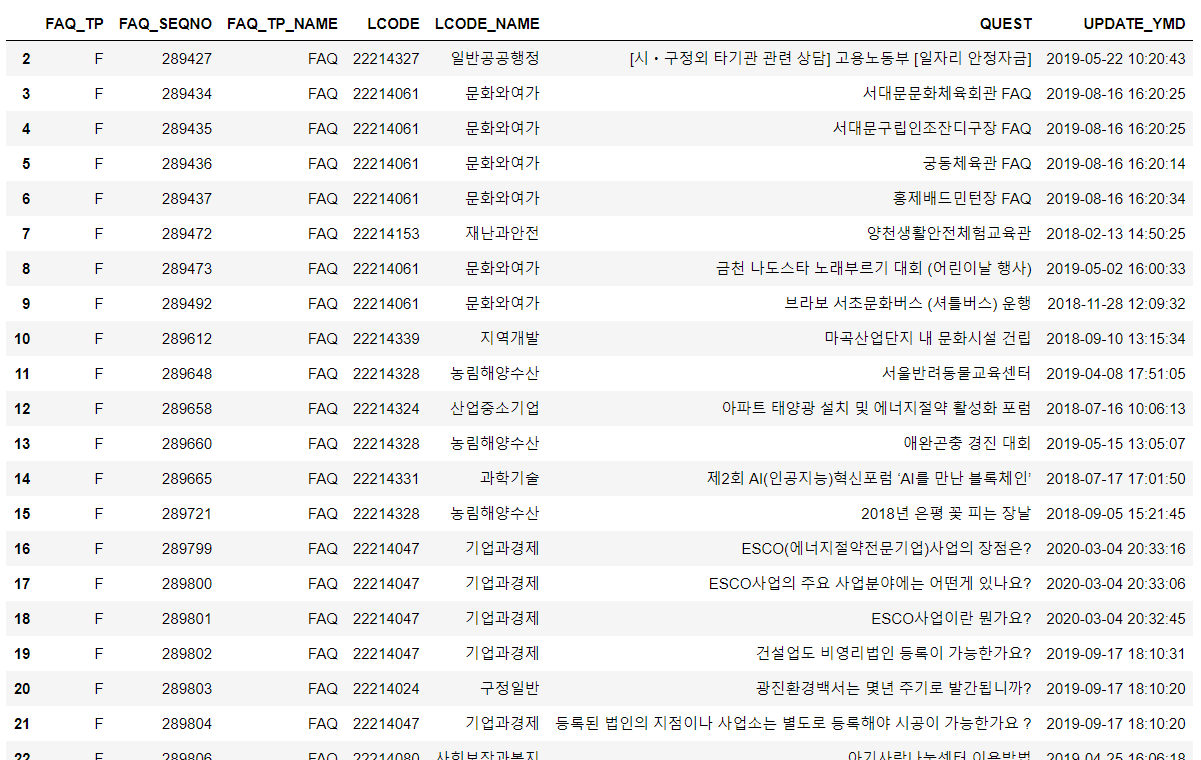
4) FAQ 내용 수집 연습하기
: 서버에서 제공하는 sample code를 통해 FAQ 개별 정보 불러오기
🔹 url 만들기
faq_no = 289435 # 내용 일련번호
detail_url = f"http://openapi.seoul.go.kr:8088/sample/xml/SearchDetailsFAQService/1/5/F/{faq_no}"🔹 pandas로 url 결과 받아오기
# 일련번호 289435 내용에 대한 결과
cont = pd.read_xml(detail_url)
cont
# cont의 마지막 행, 3열부터 끝열까지 정보 추출
cont.iloc[-1, 3:]
🔹 특정내용 읽어오기
df_list_content.head()
# df_list_content에서 0번째 행의 FAQ 내용을 불러오기
FAQ_TP = df_list_content.iloc[0]["FAQ_TP"]
FAQ_SEQNO = df_list_content.iloc[0]["FAQ_SEQNO"]
detail_url = f'http://openAPI.seoul.go.kr:8088/{auth_key}/xml/SearchDetailsFAQService/1/1/{FAQ_TP}/{FAQ_SEQNO}/'
result = pd.read_xml(detail_url)
display(result)
display(result.iloc[-1]["ANSWER"])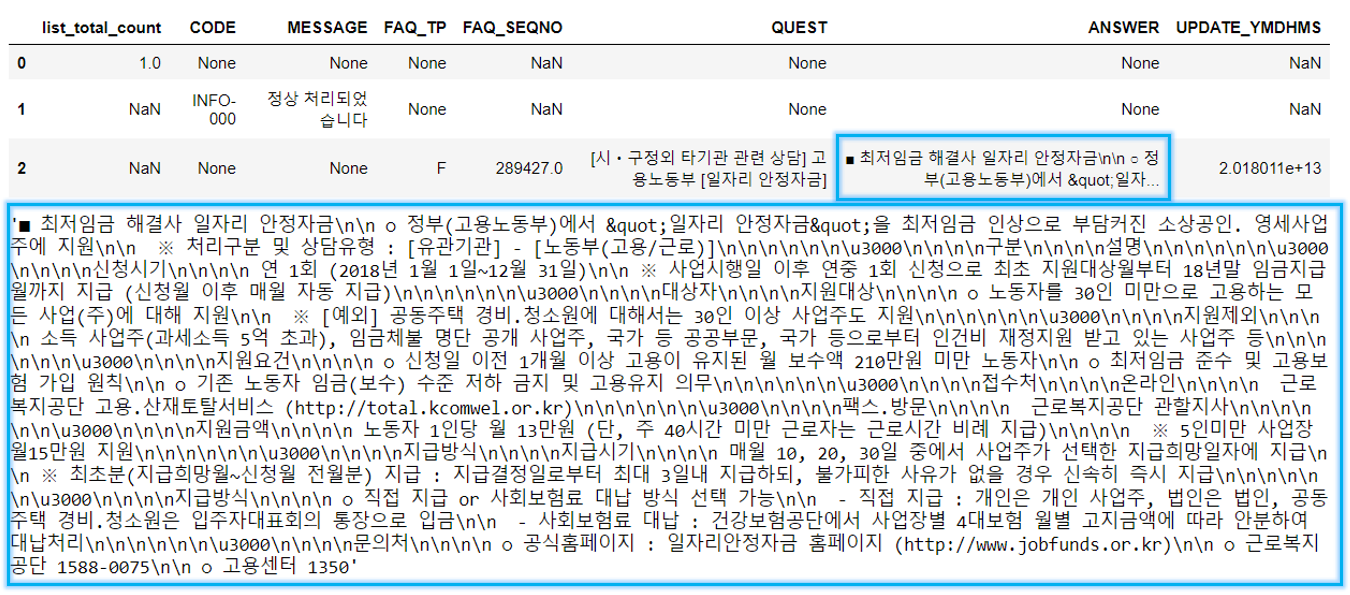
🔹 내용 수집 함수 만들기
def get_content(FAQ_SEQNO):
'''FAQ_SEQNO로 ANSWER를 반환하는 함수
'''
detail_url = f'http://openAPI.seoul.go.kr:8088/{auth_key}/xml/SearchDetailsFAQService/1/1/F/{FAQ_SEQNO}/'
result = pd.read_xml(detail_url)
answer = result.iloc[-1]["ANSWER"]
return answer- 함수 확인하기
# 함수가 잘 만들어졌는지 확인
# 결과값이 잘 나온다면 반복문 실행
get_content(289427)- 함수를 반복문에 적용하기
# map 함수를 사용하여 반복하기
# Series 타입의 데이터를 반복하려면 map 또는 apply 사용
df_list_content["ANSWER"] = df_list_content["FAQ_SEQNO"].map(get_content)
df_list_content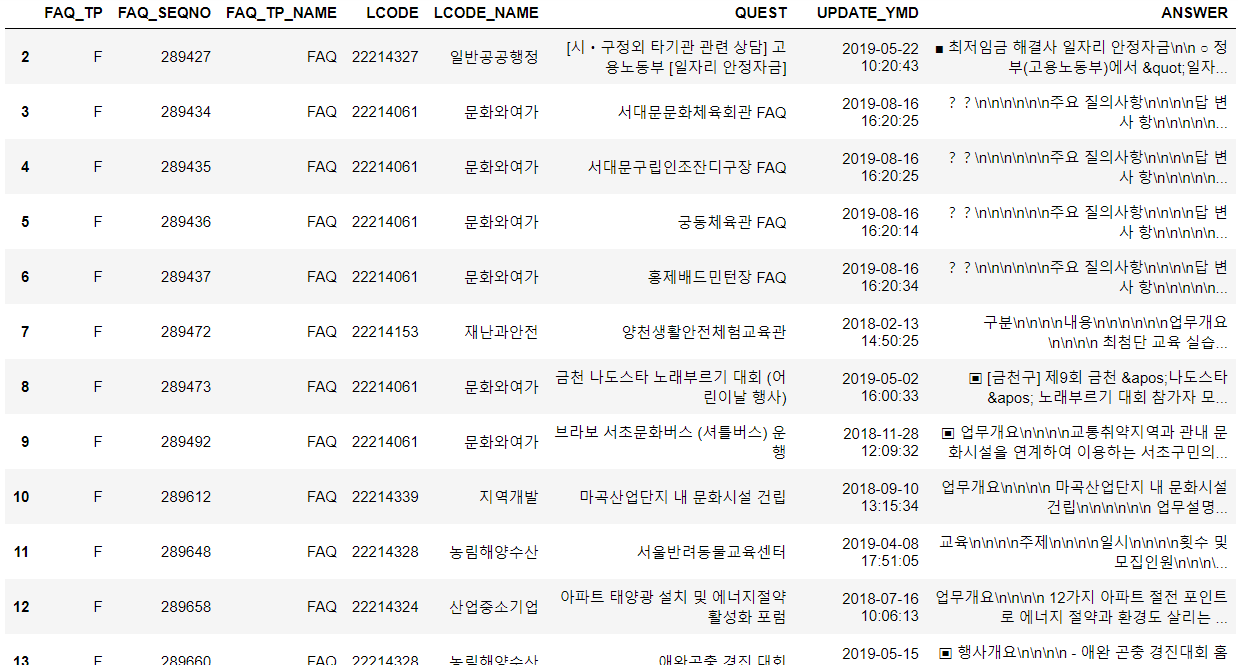
❗이것만은 외우고 자자 Top 3
📌 날짜형 데이터로 바꾸는 매서드는 pd.to_datetime
(참고: 판다스 공식문서 https://pandas.pydata.org/docs/reference/api/pandas.to_datetime.html#pandas.to_datetime)
📌 함수를 반복할 때 Series 타입에서만 가능한 매서드는 map, DataFrame 타입에서만 가능한 건 applymap, 둘 다 가능한 건 apply
📌 df에서 데이터 타입을 변경할 땐 astype
🌟데일리 피드백
1. 오늘의 칭찬&반성
너무 어려워서 복습하기 두려운 부분이었는데 천천히 배운 내용을 구조화하면서 공부하니 이해가 되었다. 무섭다고 포기하지 않고, 졸린 눈을 비비며 끝까지 포스팅을 완료하는 내가 자랑스럽다!
2. 내가 부족한 부분
슬슬 조금씩 공부 속도를 높이자. 마냥 책상에 오래 앉아있는 것은 비효율적인 공부라는 생각이 든다.
3. 내일의 목표
미니플젝 최대한 도전하기
