
다음의 가설이 참이라고 할 수 있는지 분석
가설: 이디야는 스타벅스 근처에 전략적으로 입점한다.
문제1
서울시의 스타벅스 매장의 이름과 주소, 구 이름을 pandas data frame으로 정리
1. 스타벅스 매장 위치 데이터 가져오기 - Selenium 접근
(1) selenium 및 필요한 모듈 설치
import pandas as pd
import numpy as np
import time
from selenium import webdriver(2) Chrome driver로 스타벅스 사이트 접속
url = 'https://www.starbucks.co.kr/store/store_map.do'
driver = webdriver.Chrome('../driver/chromedriver.exe')
driver.get(url)(3) 지역 검색 클릭
xpath_1 ='//*[@id="container"]/div/form/fieldset/div/section/article[1]/article/header[2]/h3/a'
some_tag_1 = driver.find_element_by_xpath(xpath_1)
some_tag_1.click()
time.sleep(1)(4) 지역 → 시도 정보 → 서울 클릭
xpath_2 = '//*[@id="container"]/div/form/fieldset/div/section/article[1]/article/article[2]/div[1]/div[2]/ul/li[1]/a'
some_tag_2 = driver.find_element_by_xpath(xpath_2)
some_tag_2.click()
time.sleep(1)(5) 지역 → 시도 정보 → 서울 → 전체 클릭
xpath_3 = '//*[@id="mCSB_2_container"]/ul/li[1]/a'
some_tag_3 = driver.find_element_by_xpath(xpath_3)
some_tag_3.click()
time.sleep(1)2. 스타벅스 매장 위치 데이터 가져오기 - BeautifulSoup 접근
(1) BeautifulSoup 이용해서 html로 읽기
from urllib.request import urlopen, Request
from bs4 import BeautifulSoup
# 서울 전체
req_starbucks = driver.page_source
soup_starbucks = BeautifulSoup(req_starbucks, "html.parser")(2) 매장 주소 확인
container = soup_starbucks.find('div', id = 'mCSB_3_container')
address = container.find_all('li')
print(address)
(3) for문을 이용한 매장 데이터 스크래핑
starbucks = []
for store in address:
store_name = store.find('strong').text
store_address = store.find('p').text.replace('1522-3232', '')
store_gu = store_address.split(' ')[1]
lat = store['data-lat']
lng = store['data-long']
final = {
'매장' : store_name,
'매장주소' : store_address,
'구' : store_gu,
'브랜드' : 'STARBUCKS',
'lat' : lat,
'lng' : lng
}
starbucks.append(final)
starbucks
3. 스타벅스 매장 위치 데이터 pandas data frame으로 정리 및 저장하기
starbucks_df = pd.DataFrame(starbucks)
starbucks_df.info()
starbucks_df.tail()
starbucks_df['구'].unique(), len(starbucks_df['구'].unique())
driver.quit()# 데이터 저장 및 확인
starbucks_df.to_csv('../data/EDA1_starbucks_data.csv', sep = ',', encoding = 'utf-8')
starbucks_df = pd.read_csv(
"../data/EDA1_starbucks_data.csv",
sep=",",
encoding = 'utf-8',
index_col = 0
)
starbucks_df.head(2)
문제2
서울시의 이디야 매장의 이름과 주소, 구 이름을 pandas data frame으로 정리
1. 이디야 매장 위치 데이터 가져오기 - Selenium 접근
(1) selenium 및 필요한 모듈 설치
import pandas as pd
import numpy as np
import time
from selenium import webdriver(2) Chrome driver로 이디야 사이트 접속
url_ediya = 'https://www.ediya.com/contents/find_store.html'
driver = webdriver.Chrome('../driver/chromedriver.exe')
driver.get(url_ediya)(3) 주소 검색 클릭
xpath_3 ='//*[@id="contentWrap"]/div[3]/div/div[1]/ul/li[2]/a'
some_tag_3 = driver.find_element_by_xpath(xpath_3)
some_tag_3.click()
time.sleep(1)2. 이디야 매장 위치 데이터 가져오기 - BeautifulSoup 접근
(1) for문을 이용한 이디야 매장 데이터 스크래핑
import time
from tqdm import tqdm_notebook
# 문제1에서 얻은 서울 소재 '구'를 가져와 gu_list에 저장
gu_list = starbucks_df['구'].unique()
ediya = []
for gu in tqdm_notebook(gu_list):
driver.find_element_by_xpath('//*[@id="keyword"]')
# 검색 초기화
driver.find_element_by_xpath('//*[@id="keyword"]').clear()
time.sleep(1)
# 검색어 입력
driver.find_element_by_xpath('//*[@id="keyword"]').send_keys('서울 {}'.format(gu))
time.sleep(1)
# 검색버튼 클릭
driver.find_element_by_xpath('//*[@id="keyword_div"]/form/button').click()
time.sleep(1)
# 서울시 구별 매장 데이터 스크래핑 - BeautifulSoup을 이용해서 html로 읽기
req_ediya = driver.page_source
soup_ediya = BeautifulSoup(req_ediya, "html.parser")
ul = soup_ediya.find('ul', id = 'placesList')
dl = ul.find_all('dl')
for i in dl:
store_name = i.find('dt').text.strip()
store_address = i.find('dd').text.strip()
store_gu = store_address.split(' ')[1]
final = {
'매장' : store_name,
'매장주소' : store_address,
'구' : store_gu,
'브랜드' : 'EDIYA'
}
ediya.append(final)
ediya3. 위도, 경도 데이터 추가하기
ediya_df = pd.DataFrame(ediya)
ediya_df.tail()
driver.quit()
# 위도, 경도 컬럼 추가
import googlemaps
gmaps_key = '___________' # 본인이 발급받은 key값 작성
gmaps = googlemaps.Client(key = gmaps_key)import numpy as np
ediya_df['lat'] = np.nan
ediya_df['lng'] = np.nan
ediya_df.head(2)
for idx, rows in tqdm_notebook(ediya_df.iterrows()):
tmp = gmaps.geocode(rows['매장주소'], language = 'ko')
if tmp:
lat = tmp[0].get('geometry')['location']['lat']
lng = tmp[0].get('geometry')['location']['lng']
ediya_df.loc[idx, 'lat'] = lat
ediya_df.loc[idx, 'lng'] = lng
else:
print(idx, rows['매장주소'])
위의 7개의 주소에 대해 error가 발생했으므로, 해당 주소들을 구글맵이 인식할 수 있도록 위도와 경도를 수정하여 입력해주었다.
# 구글지도에서 주소 검색 후 위도, 경도 직접 입력
ediya_df.loc[105, 'lat'] = 37.4796
ediya_df.loc[105, 'lng'] = 126.9529
ediya_df.loc[292, 'lat'] = 37.573
ediya_df.loc[292, 'lng'] = 126.9126
ediya_df.loc[359, 'lat'] = 37.6055
ediya_df.loc[359, 'lng'] = 127.0308
ediya_df.loc[374, 'lat'] = 37.4778
ediya_df.loc[374, 'lng'] = 127.125
ediya_df.loc[410, 'lat'] = 37.5154
ediya_df.loc[410, 'lng'] = 127.0948
ediya_df.loc[450, 'lat'] = 37.5197
ediya_df.loc[450, 'lng'] = 126.9391
ediya_df.loc[700, 'lat'] = 37.5866
ediya_df.loc[700, 'lng'] = 127.0955
ediya_df.info()
4. 이디야 매장 위치 데이터 저장 및 확인하기
ediya_df.to_csv('../data/EDA1_ediya_data.csv', sep = ',', encoding = 'utf-8')
ediya_df = pd.read_csv(
"../data/EDA1_ediya_data.csv",
sep=",",
encoding = 'utf-8',
index_col = 0
)
ediya_df.head(2)
문제3
문제1과 문제2의 결과를 가지고 이디야가 스타벅스 매장 근처에 전략적으로 입점하는지 분석.
예를 들어 모든 커피 매장의 주소에서 위도/경도 정보를 통해 물리적인 거리를 측정할 수도, 도로명 주소를 통해 단순히 유추할 수도, 혹은 folium으로 시각화 후 육안으로 확인할 수도 있음.
※ 분석한 결과를 markdown으로 설명할 것가설: 이디야는 스타벅스 근처에 전략적으로 입점한다.
1. 스타벅스, 이디야 매장 개수 파악
(1) 스타벅스 매장 개수 파악
# 서울시 전체 스타벅스 매장 개수
starbucks_df['브랜드'].value_counts()
# 구별 스타벅스 매장 개수
pivot_starbucks = starbucks_df.pivot_table(index='구', values='매장', aggfunc = len)
pivot_starbucks.head()
# 스타벅스 매장 상위 10개 구
pivot_starbucks.sort_values(by = '매장', ascending = False).head(10)
(2) 이디야 매장 개수 파악
# 서울시 전체 이디야 매장 개수
ediya_df['브랜드'].value_counts()
# 구별 이디야 매장 개수
pivot_ediya = ediya_df.pivot_table(index='구', values='매장', aggfunc = len)
pivot_ediya.head()
# 이디야 매장 상위 10개 구
pivot_ediya.sort_values(by = '매장', ascending = False).head(10)
스타벅스와 이디야의 서울시 소재 매장 개수를 파악한 결과,
스타벅스는 총 599개 매장, 이디야는 총 711개 매장을 운영하고 있음을 확인할 수 있었다.
스타벅스가 위치한 서울시의 상위 10개 구는 강남구, 중구, 서초구, 영등포구, 종로구, 마포구, 송파구, 강서구, 용산구 순이었고,
이디야가 위치한 서울시의 상위 10개 구는 강남구, 영등포구, 강서구, 송파구, 마포구, 종로구, 성북구, 중구, 노원구, 중랑구 순이었다.
이를 바탕으로 스타벅스와 이디야 모두 강남구에 가장 많은 매장이 있다는 것을 확인하였다.
또한, 스타벅스와 이디야가 위치한 상위 10개 구에는 7개의 구(강남구, 중구, 영등포구, 종로구, 마포구, 송파구, 강서구)가 중복되어 있는 것을 확인하였다.
이렇게 상위 10개 구만 보았을 때, 중복되는 구는 70%로 많기 때문에, 이디야 커피가 스타벅스 커피 매장 근처에 입점했다고 볼 수 있다.
하지만, 이와 같은 추측이 사실인지 아닌지 보다 정확하게 분석하기 위해 시각화를 통해 보고자 한다.
2. 시각화
(1) 스타벅스, 이디야 데이터 합치기
cafe = pd.concat([starbucks_df, ediya_df])
cafe.tail()
cafe.info()
(2) 시각화 1 - barplot
import matplotlib.pyplot as plt
import seaborn as sns
import platform
from matplotlib import font_manager, rc
%matplotlib inline
path = 'C:/Windows/Fonts/malgun.ttf'
if platform.system() == 'Darwin':
rc('font', family = 'Arial Unicode MS')
elif platform.system() == 'Windows':
font_name = font_manager.FontProperties(fname = path).get_name()
rc('font', family = font_name)
else:
print('Unknown system. sorry.')cafe_cnt = cafe.groupby(['구', '브랜드'])['매장'].count().reset_index(name = '매장개수')
cafe_cnt.head()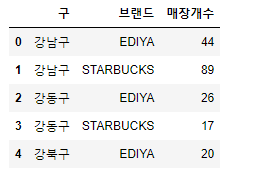
cafe["값"]=1
cafe_cnt2 = cafe.pivot_table(index="구", columns="브랜드", values='값', aggfunc=np.sum)
cafe_cnt2.head()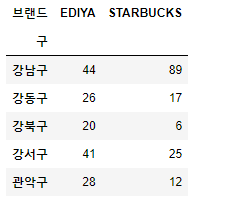
plt.figure(figsize = (20, 8))
sns.barplot(
data = cafe_cnt,
x = cafe_cnt['구'],
y = cafe_cnt['매장개수'],
hue = '브랜드',
palette = 'Set2'
)
plt.show()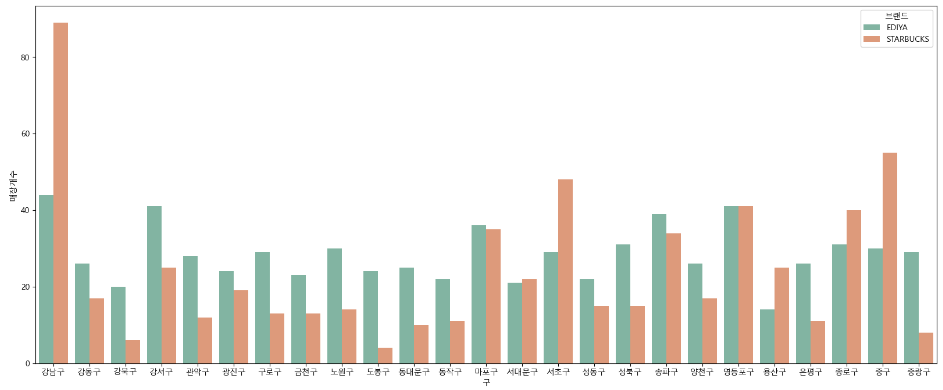
스타벅스는 강남구, 중구, 서초구, 영등포구 등 특정 구에 집중적으로 분포하고 있는 것을 확인할 수 있는데, 이 구들은 주로 회사가 밀집되어 있고, 유동인구가 많다는 특징이 있다.
반면, 이디야는 구별 큰 편차가 없이 고르게 분포되어 있다는 것을 확인할 수 있다.
강북구, 도봉구, 중랑구 등 몇 개의 구에서는 스타벅스 매장 수는 이디야의 매장 수보다 현저히 낮음을 확인 할 수 있다.
(3) 시각화 2 - folium: 지도 시각화 1
import folium
my_map = folium.Map(location = [37.5599, 126.9737], zoom_start = 11)
for idx, row in cafe.iterrows():
if row['브랜드'] == 'EDIYA':
folium.Marker(
location = [row['lat'], row['lng']],
tooltip = row['매장'],
icon = folium.Icon(
icon = 'coffee',
color = 'darkblue',
icon_color = 'white',
prefix = 'fa')
).add_to(my_map)
else:
folium.Marker(
location = [row['lat'], row['lng']],
tooltip = row['매장'],
icon = folium.Icon(
icon = 'star',
color = 'green',
icon_color = 'white',
prefix = 'fa')
).add_to(my_map)
my_map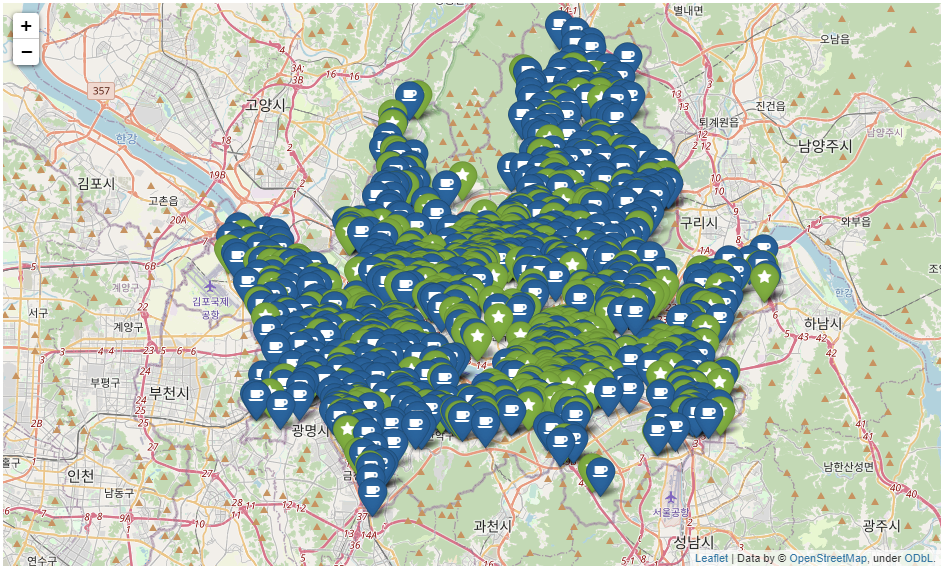
folium을 통해 지도 시각화를 한 결과이다.
해당 지도는 위도와 경도를 통해 생성되었지만, 육안 상으로 판단하기 어렵다.
따라서 다른 방법으로 지도 시각화를 해보고자 한다.
(4) 시각화 2 - folium: 지도 시각화 2
위의 folium.Marker를 이용한 지도 시각화에서는 운영 중인 매장 수가 많아 육안으로 판단하기 어렵다. 따라서 구별로 묶어 파악하기 쉽도록 시각화를 다시 해보고자 한다.
cafe_cnt2.head(2)
cafe_cnt2["lat"] = np.nan
cafe_cnt2["lng"] = np.nan
for idx, rows in cafe_cnt2.iterrows():
tmp = gmaps.geocode(idx, language='ko')
if tmp:
lat= tmp[0].get("geometry")["location"]["lat"]
lng= tmp[0].get("geometry")["location"]["lng"]
cafe_cnt2.loc[idx,"lat"]=lat
cafe_cnt2.loc[idx,"lng"]=lng
else:
print(idx)
cafe_cnt2.head()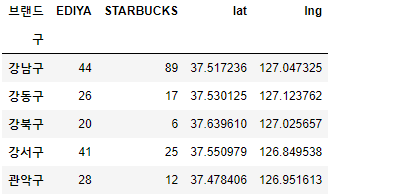
my_map2 = folium.Map(location = [37.5599, 126.9737], zoom_start = 11)
for idx, row in cafe_cnt2.iterrows():
folium.Circle(
location = [row['lat'], row['lng']],
radius = row['EDIYA'] * 50,
fill = True,
color = 'blue',
tooltip = idx,
).add_to(my_map2)
folium.Circle(
location = [row['lat'], row['lng']],
radius = row['STARBUCKS'] * 50,
fill = True,
color = 'red',
tooltip = idx,
).add_to(my_map2)
my_map2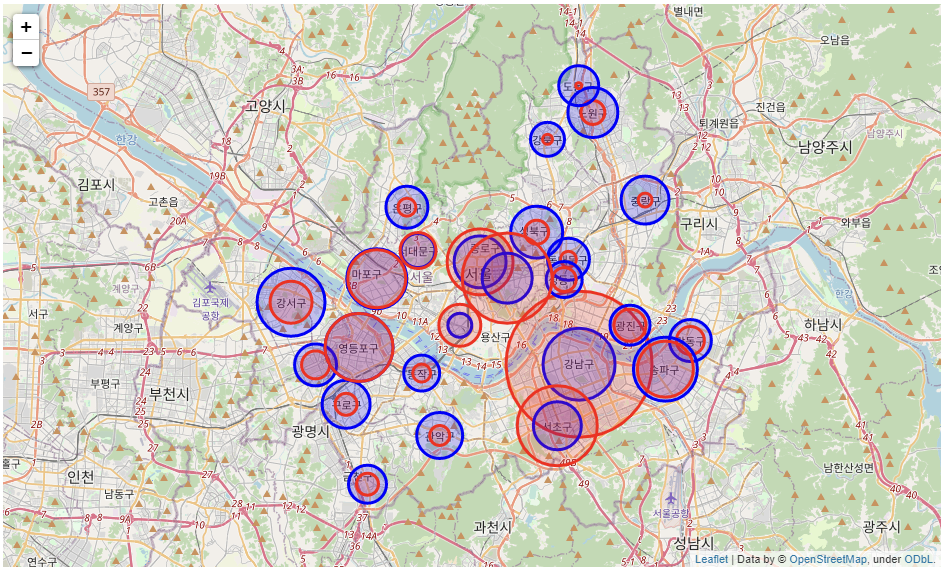
스타벅스는 빨간색, 이디야는 파란색으로 나타내었다.
스타벅스는 유동인구가 많은 강남구, 중구, 영등포구, 마포구 중심으로 원의 크기가 크지만 서울 외곽으로 갈수록 원의 크기가 급격히 작아졌다.
반면, 이디야는 고르게 분포되어 있는 것을 확인 할 수 있다.
<결론>
가설: 이디야는 스타벅스 근처에 전략적으로 입점한다.
barplot과 folium을 통해 분석한 결과,
이디야는 전반적으로 고르게 분포되어 있지만, 스타벅스는 유동인구가 많은 곳에 집중적으로 분포되어 있다는 것을 확인했다.
따라서 이디야는 스타벅스 근처에 전략적으로 입점한다는 가설은 타당하지 않는 것으로 보인다.
