논문 및 이미지 출처 : http://boyangli.org/paper/Jiaxian-CVPR-2023-Img2LLM.pdf

Abstract
Large Language Modes (LLMs) 는 새로운 task 에 대한 zero-shot 일반화가 우수하지만 visual question-answering (VQA) zero-shot 에 활용하는데는 어려운 과제가 있다.
LLM 과 VQA 간의 modality disconnect 와 task disconnect 때문이며, multimodal data 를 End-to-End 학습을 하여 해소할 수 있지만, 유연함이 없고 계산 비용이 크다.
이를 해결하기 위해 저자는 Img2LLM 를 제안한다. LLM 이 end-to-end 학습 없이 zero-shot VQA task 를 수행할 수 있도록 plug-and-play module 로 LLM prompt 를 제공한다.
LLM-agnostic model 을 개발하여 이미지 내용을 exemplar question-answering 쌍으로 설명, 이는 효과적인 LLM prompt 로 입증된다.
Img2LLM 은 다음 benefit 을 제공한다.
- end-to-end training 에 의존한 방법보다 경쟁력있고 성능이 나음. 예로, VQAv2 에서 Flamingo 보다 5.6% 성능이 좋고, A-OKVQA 에서 few-shot 방법으로 최대 20% 까지 성능이 좋다.
- VQA 수행을 위해 LLM 을 넓은 범위로 유연하게 interface 로 연결
- end-to-end finetuning 으로 LLMs 를 specialize 할 필요성을 제거하고 고도의 specialized LLMs 를 사용자에게 제공하여, 비용을 줄인다.
코드는 https://github.com/salesforce/LAVIS/tree/main/projects/img2llm-vqa 에서 확인 가능하다.
1. Introduction
VQA 는 실세계 응용에 중요한 vision-language task 이다. 다양한 VQA 데이터셋이 제안됐으며, 몇몇은 이미지 인식이나 논리적 추론에 초점을 맞추었지만, 인간의 주석을 얻는 것은 비용적으로 비싸고 인간의 편향이 개입할 수도 있다. 이는 VQA 시스템이 새로운 답변 스타일과 질문 유형을 취약하게 만든다.
위 사항들로 인해 연구자들은 ground-truth question-answering annotation 을 필요로 하지 않는 zero-shot VQA 방법을 사용하여, 더 잘 일반화가 가능한 VQA 시스템을 구축하는 추세이다.
최근, LLMs 가 zero in-domain task 를 수행하고 논리적 추론 및 NLP task 의 commonsence knowledge 를 적용하는데 우수한 능력을 입증한다. 그 결과, 최근 approach 는 zero-shot VQA 에서 LLMs 활용한다.
하지만, VQA task 에 LLMs 를 적용하는 건 쉽지 않은데,
- vision 과 language 사이의 modality disconnect
- language modeling 과 question answering 사이의 task disconnect
때문이다.
일반으로 vision 과 language representation space 간의 align 을 위해 LLM 과 vision encoder 를 공통적으로 finetuning 하는데, 이는 계산 및 데이터 비용이 크다.
예로, Flamingo 는 수천 개의 TPU 로 수십억 개의 image-text 쌍을 finetuning 하는데 다가, finetuning 에 specialize 되며 vision encoder 와 LLM 사이에 상호의존성이 커진다.
또한 LLM 을 새 버전으로 업그레이드 한다면, 전체 모델을 비용이 큰 재학습을 수행해야 한다.
LLM 을 VQA 와 통합하는 end-to-end 대신, 본 논문에선 frozen off-the-shelf LLM 으로 구축한 modular VQA 를 제안한다. 이는 두 가지 이점이 있다.
- 배치 비용을 줄이고 간단함
- LLM 업그레이드가 간단
하지만 end-to-end training 없으면 modality disconnect 와 task disconnect 해결이 힘들다.
PICa 는 image 를 caption 으로 변환하여 훈련 데이터에서 예시 QA 쌍을 LLM 에게 prompt 로 제공한다. 하지만 주석된 훈련 데이터가 존재한다는 가정을 전제로 하여, 성능이 few-shot 선택에 민감하다.
이에 저자는 Img2LLM 을 제안한다. 이는 off-the-shelf LLMs 가 zero-shot VQA 을 수행할 수 있도록 하는 plug-and-play module 이다(규격품을 연결만하면 쉽게 사용할 수 있는 모듈).
Img2LLM 의 핵심은 vision-language model (예; BLIP) 과 question-generation model 을 활용하여 이미지 내용을 QA 쌍으로 변환하는 것이다.
이러한 예시 QA 쌍은 이미지 내용을 언어로 설명하여 modality connect 를, LLM 에게 QA task 시연하여 task disconnect 를 해결한다.
특히, 예시 QA 쌍은 test image 와 question 을 기반으로 구성되며, PICa 에서 필요한 similar few-shot 예제가 practical zero-shot 시나리오에서 항상 사용 가능하지 않으므로 사전에 제거한다.
오픈 소스인 OPT language model 을 적용했을 때, Img2LLM 은 비용이큰 end-to-end training 을 수행하는 방법들과 비교 가능하거나 우수한 zero-shot VQA 성능을 달성한다.
본 논문의 contribution 은 다음과 같다.
- 저자는 current image 와 질문을 기반으로 image 를 합성된 QA 쌍으로 변환하는 plug-and-play 모듈인 Img2LLM 을 제안. 이는 visual 과 language 간의 modality disconnect 와 language modeling 과 VQA 간의 task disconnect 를 연결해준다.
- Img2LLM 은 비용이 큰 end-to-end training 이나 특화된 QA 네트워크 없이 off-the-shelf LLM 이 zero-shot VQA 를 수행할 수 있게 한다. 그래서 낮은 비용과 유연한 모델 배치 및 간편한 LLM 업그레이드가 가능하다.
- 실험 결과, Img2LLM 이 적용된 OTP 모델이 end-to-end 로 학습된 모델과 비교 가능하거나 우수한 zero-shot VQA 성능을 달성한다. 예로, VQAv2 에서 Flamingo 보다 5.6% 우수하고, 많은 few-shot VQA 방법보다 우수하다.
2. Related Work
2.1 Recent Advances in VQA Method
VQA 는 이미지에 따라 자연어 question 에 대답하는 모델을 요구하는 multimodal 평가 벤치마크로 활발한 연구 초점이 되었다.
대규모 image-text pretraining 후 VQA 데이터셋의 finetuning 과 함께 지난 몇년간 빠른 성능 향상이 이루어졌다.
knowledge 기반 VQA 해결을 위해 최근 연구는 ConceptNet 이나 Wikipedia 같은 외부 지식을 포함하지만, 이러한 방법들은 복잡한 추론을 필요로 하는 question 에 대한 answer 이 여전히 어려움을 나타낸다.
2.2 LLM for Zero/Few-Shot VQA Tasks
LLMs 를 웹 규모의 말뭉치로 학습되어 자연어 이해와 추론에 강하다. task data 추론을 위해, LLMs 는 보통 autoregressively 하게 target token 을 생성한다.
구체적으론 prompt 및 task input 이 주어지면, LLM 은 target token 인 을 생성한다. 여기서 이며 는 모델 파라미터다.
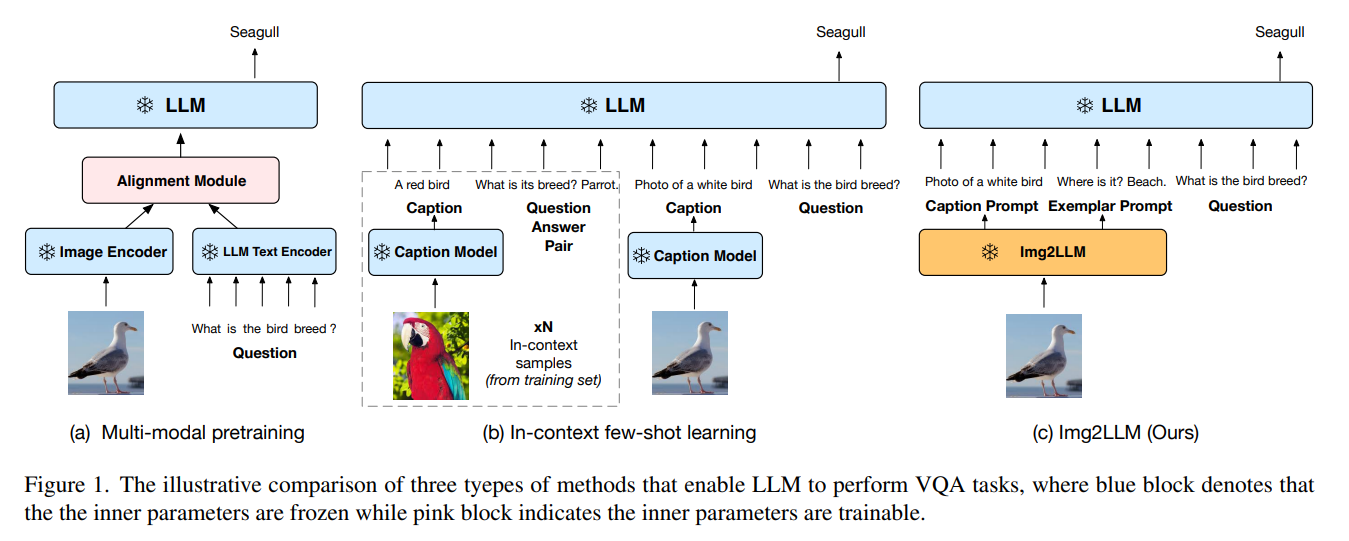
LLM 을 이용한 이전 VQA 방법은 주로 두 가지 범주인 multi-modal pretraining 과 language-mediated VQA 로 나뉜다.
Multi-modal pretraining
이 접근법은 Figure 1(a) 에서 보여주며, 추가적인 alignment module 을 훈련하여 visual 과 language embedding 을 align 한다.
LLMs 가 효율적으로 finetuning 하기엔 큰 것을 고려할 때, [Multimodal Few-Shot Learning with Frozen Language Models] 논문에서는 visual encoder 만을 finetuning 하는 것을 택하고, Flamingo 는 cross-modality 상호작용을 모델링하기 위해 추가적인 cross-attention layer 를 훈련한다. 그러나 이 패러다임엔 두 가지 단점이 있다.
- 계산 비효율적. visual backbone 과 LLM 을 동시에 정렬하기엔 계산 자원이 많이 필요하다.
- 치명적인 forgetting. align 단계가 LLMs 와 visual model 이 함께 훈련되면, LLMs 의 추론 능력에 해가 될 수 있다.
Language-mediated VQA
이 패러다임은 벡터화된 representation 대신, intermediate representation 으로 자연어를 사용하며, 비싼 pretraining 을 필요로 하지 않는다.
Figure 1(b) 처럼, 현재 이미지를 언어 설명으로 변환한 다음, 설명을 frozen LLM 에 입력한다.
few-shot 설정에서 PICa 는 image caption 을 생성하고, in-context exemplar 로 훈련 데이터 샘플을 선택하지만, exemplar 가 제외되면 성능이 크게 저하된다.
동시에 진행되는 zero-shot 방식으로 question 과 관련된 caption 을 생성한다. zero-shot 요구사항 때문에 in-context exemplar 를 제공할 수 없으며, in-context 학습의 이점을 누릴 수 없다.
결과적으로 이 접근법은 고성능 달성을 위해 QA 전용 LLM 인 UnifiedQAv2 에 의존한다.
3. Method
LLM 을 zero-shot VQA 에 효과적으로 활용하는데 주요 두 장애물이 있다.
- modality disconnection : LLMs 은 이미지를 처리하지 않으며 visual 정보를 LLMs 이 처리할 수 있도록 인코딩하는 것도 어렵다.
- task disconnection : LLMs 는 언어 모델링 task 에서 생성적 또는 노이즈 제거 목적으로 pretraining 한다.
LLMs 은 QA 이나 VQA task 의 특성을 알지 못하여 answer 를 생성할 때 contextual 정보르 활용하지 못하는 경우가 있다.
VQA 에서 modality disconnect 는 이미지를 dense vector 대신 intermediate language description 으로 변환한다. task disconnect 는 few-shot in-context exemplar 나 QA 에 직접 finetuning 된 LLM 을 사용하여 해결해야한다. 이는 zero-shot 설정에 일반적인 LLM 에서 task disconnection 을 어떻게 다룰지 분명하지 않다.
이에 저자는 새로운 zero-shot 기술인, 일반적인 LLM 의 task disconnect 를 해결하기 위해 Img2LLM 을 제안한다. 이는 image 관련 exemplar prompt 를 생성한다.
question 와 image 가 주어지면, 핵심은 current image 의 in-context exemplar 로써 합성된 QA 쌍을 생성할 수 있다. 이러한 exemplar 는 QA task 를 보여줄 뿐만 아니라 이미지 내용을 LLM 에 전달하여 question 에 대한 answering 생성하는 데도 기여한다.
Img2LLM 은 LLM-agnostic 이며, off-the-shelf LLMs 의 지식과 추론 능력을 활용해 zero-shot VQA 에 강력하면서 유연한 솔루션을 제공한다.
3.1 Answer Extraction
VQA image 에서 in-context learning 을 위해, 이미지 내용을 exemplar 로 통합하기 위해서, 저자는 먼저 합성된 question 에 대한 answering 으로 사용될 수 있는 단어를 찾는다.
question 관련 caption 생성 모듈을 사용해 여러 개의 caption 을 생성한다.
최근 논문을 따라, 명사구(고유명사 포함), 동사구, 형용사구, 숫자, '예' 와 '아니오' 같은 부울 타입의 단어를 answer 후보로 추출한다.
3.2 Question Generation
추출된 answer 후보 집합 로, 각 answer 후고군에 대한 특정 question 을 생성하기 위해 question generation network 를 직접 사용할 수 있다.
본 논문에서는 template 과 neural 기반의 question-generation 방법에서 실험한다.
zero-shot 요구사항을 위반하는 것을 피하기 위해, VQA 데이터에 접근이 없는 순전히 textual 기반으로 한다.
Template-based Question Generation
off-the-shelf parser 를 사용해, 각 answer 의 품사를 얻고, 각 POS 타입의 특정 question 템플릿을 설계한다.
예로,
- noun answer : "What object is being taken in this image?"
- verb answer : "What action is being taken in this image?"
Neural Question Generation
[All You May Need for VQA are Image Captions] 논문에 영감을 받아, textual QA 데이터셋에서 neural question 생성 모델을 훈련시킨다.
answer 로 question 을 생성하도록 pretrained T5-large 모델을 finetuning 한다.
모델의 input 은 "Answer: . Context: " 을 포함한다.
여기서 textual QA 데이터셋으로부터, 은 answer text 을, 은 context text 를 나타낸다.
추론 중에는, 을 추출된 answer 후보로, 는 해당 추출된 answer 로부터 생성된 caption 으로 교체된다.
모델은 5 가지 textual QA 데이터셋으로 finetuning 한다.
- SQuAD2.0
- MultiRC
- BookQA
- CommonsenseQA
- SocialIQA
위 question 생성 방법으로, 합성된 question-answer 쌍 을 얻는다. 이 쌍을 LLM in-context learning 의 exemplar 로 사용하며, 주어진 이미지 내용으로 QA task 를 수행하도록 가이드하고 language modeling 과 VQA 간의 task disconnect 를 연결해준다.

위 테이블로 exemplar QA 쌍의 효과를 보여준다.
저자는 exemplar QA prompt 가 caption prompt 보다 더 우수함을 관찰했다.
이는 exemplar QA 가 LLM pretraining 과 VQA task 간의 task disconnection 을 연결한다는 효과를 입증한다. 또한, exemplar prompt 가 이미지의 많은 내용을 설명하고 있어, modality disconnection 도 연결하는데 도움이 되며, 이에 caption 을 추가하는 것은 크게 새로운 정보를 제공하지 않으며 성능 향상이 제한적이다.
3.3 Question-relevant Caption Prompt
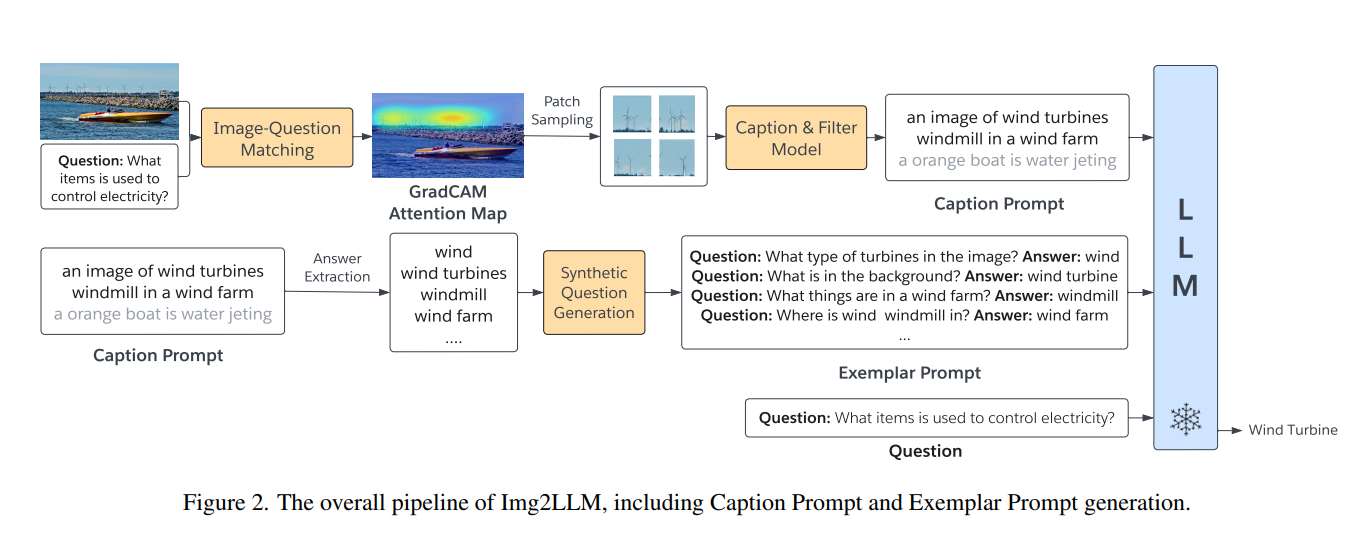
합성된 exemplar QA 쌍와 추가적으로, question-relevant image captions 를 LLM 에 제공한다.
저자는 question 이 이미지의 특정 객체나 지역을 묻지만 기존 네트워크로 생성된 일반적인 caption 은 관련 정보를 포함하지 않을 수 있는 것을 관찰했다.
위 Figure 2 에서 , question "What items are spinning in the blackground which can be used to control electricity?" 는 wind turbine 에만 관련있다. 그러나 전체 이미지에서 생성된 caption 은 salient orange boat 에 초점을 맞출 가능성이 높으며, LLM 은 question 에 대한 answer 정보가 없게 된다.
이 문제를 해결하기 위해 question 관련 이미지 부분에 대한 caption 을 생성하고, LLM 에게 이 prompt 에 포함시킨다.
이를 위해 저자는 BLIP 의 Image grounded Text Encoder (ITE) 를 사용하여 question 관련된 이미지 영역을 결정한다. ITE 는 image 와 textual question 쌍에 대한 유사도 점수 을 할당한다.
ITE 와 함께 GradCAM 이라는 feature-attribution 해석 기술을 사용하여 주어진 question 과 맞는 image 영역을 강조하는 coarse localisation map 을 생성한다.
간단히 말해, GradCAM 은 Transformer 의 croiss-attention score를 ITE 유사도 함수인 에 대한 gradient 와 결합하여 계산한다.
patch 관령성 을 얻은 후, 이와 비례하는 확률로 이미지 패치의 하위 집합을 샘플링한다. 그 후, top-k 샘플링으로 샘플링된 image patches 로 caption 을 생성한다.
의미있는 caption 을 생성하기 위해, 짧은 prompt "a picture of" 는 text encoder 에 입력한다. 개의 다양한 caption 을 생성하기 위해 이를 번 반복한다. 그리고 다른 caption 의 정확한 문자열이 아닌 caption 만 유지한다.
하지만, top-k 샘플링은 비결정적인 특성이 있어서, caption model 은 성능에 부정적인 영향을 미치는 노이즈 캡션을 생성할 수도 있다.
노이즈 캡션을 제거하기 위해, ITE 를 사용하여 생성된 캡션과 샘플링된 question 관련 이미지 패치 간의 유사도 점수를 계산한다. 그리고 매칭 점수 0.5 이하인 캡션들을 필터링한다.
위 과정으로, question 과 관련된, 다양한 및 깨끗한 합성 캡션을 얻을 수 있으며, visual 과 language 정보를 연결 역할을 제공한다.
3.4 Prompt Design
합성 question 관련 캡션과 question-answer 쌍으로, 저자는 instruction, caption 및 QA exemplar 를 연결하여 LLM 에 완전한 prompt 를 구성한다.
- Instruction text : "Please reason the answer of question according to the contexts"
- caption prompt : "Contexts: " 같은 형태
- QA exemplar : "Question: Answer: " 같은 형태
- current question 은 prompt 마지막 부분에 위치 시킴 : "Question: . Answer: ".
- answer 을 얻기 위해, LLM 에서 greedy decoding 을 수행하고, Flamingo 와 같이 무의미한 token 을 제거한다.
또한 LLM input 에는 최대 길이 제한이 있다 (예; OPT, GPT3 에선 2048). 따라서 prompt 구성을 위해 question 관련 캡션과 question-answer 쌍의 subset 선택이 필수적이다.
정보가 풍부한 prompt 선택을 위해, 저자는 100 개의 생성된 캡션에서 합성된 answer 후보의 빈도를 계산한다. 또한, 빈도가 가장 높은 30 개의 answer 후보를 선택하고 각각에 대해 한 개의 question 을 생성한다. 그리고, 빈도가 가장 낮은 30 개의 answer 와 각각을 포함하는 캡션 하나를 포함시킨다.
4. Experiment
다른 zero-shot 및 few-shot VQA 방법들과 비교한다. 그 후에, prompt patterns 및 caption selection 전략과 같은 설계 선택에 있어 ablation 연구를 수행한다.
4.1 Enviroment Setup
Datasets
- VQAv2 : 214,354 question, 107,394 test-dev
- OK-VQA : 5,046 test question
- A-OKVQA : 1,100 validation question, 6,700 test question
위 데이터셋에서 approach 를 평가한다.
Implementation details
question 관련 caption prompt 를 얻기 위해, BLIP 을 사용하여 caption 을생성하고 image-question 매칭을 수행한다.
question 관련 이미지 영역의 지역화를 위해, BLIP image-grounded text encoder 의 cross-attention layer 로부터 GradCAM 을 생성한다.
그런 다음, GradCAM 을 기반으로 이미지 패치를 샘플링하고, 이를 이용해 100 개의 question 관련 caption 을 얻는다.
LLMs 의 경우, 여러 다른 크기의 오픈 소스 OPT 모델을 주로 사용한다.
ablation study 는 다양한 다른 LLMs 를 실험하여 저자의 방법의 일반화 능력을 보여준다. 저자는 LLMs 를 사용하여 auto-regressively 한 answer 를 생성사며, answer list 나 훈련 샘플에 액세스 하지 않으므로 zero-shot VQA 를 용이하게 한다.
Competing methods
이전 VQA 와 비교하며 세 가지 카테고리로 나뉜다.
- PICa 와 같은 frozem LLM 을 사용한 Zero-shot method
- Flamingo, Frozen, VL-T5, Few VLM 및 VLKD 와 같은 multi modal pretraining 을 수행하는 Zero-shot mothod
- few-shot method 결과도 포함하며, PICa, FewVLM 및 ClipCap 결과가 포함된다.
위 방법들은 대규모의 vision-language 데이터셋이 필요하고 업데이트 비용이 많이 든다.
이 카테고리엔 VQA 나 WeaQA 도 결과로 포함하지만, 실제론 answer 후보에 접근할 수 없어 주의가 필요하다. 그러므로 이 결과에 대해선 주의하여 해석해야 한다.
4.2 Main Results

SOTA results on zero-shot evaluation with plug-in frozen LLMs
Img2LLM 은 zero-shot with frozen LLMs 인 PICa 보다 크게 능가 (OK-VQA 에서 45.6 대 17.7)
또한 PICa 는 frozen LLM 을 사용하지만 prompt 구성을 위해 훈련 샘플이 필요하지만 저자의 방법은 VQA 샘플에 접근하지 않고도 question-answer 을 생성하므로 zero-shot 요구사항도 충족
Scaling effect of LLMs and their emergent capabilities on VQA
LLMs parameter 를 6.7B 에서 175B 로 키웠을 때, VQA 에서 3-10 point 의 향상을 관찰했다.
이는 강력한 언어 모델이 qustion 을 더 잘 이해하고, 더 정확한 answer 을 주는데 도움이 된다는 것이다. 이 경향은 OK-VQA 및 A-OKVQA 에 명확하고 일관성 있으며, 이러한 데이터셋의 question 은 LLM 이 제공하는 상식적 추론과 외부 지식을 요구하기 때문이다. 이는 LLM 이 VQA 에 유익하다는 것을 뒷받침한다.
다른 흥미로운 점은 LLMs 스케일링이 크기가 클 때 명백하다는 것이다. 30B 이상에선 효과가 있지만, 작은 모델 (6.7B, 13B)에선 예측이 힘들었다.
Competitive performance with end-to-end pretraining and few-shot methods
Img2LLM 은 대부분의 end-to-end training 모델과 몇몇 few-shot 설정에서 평가된 모델보다 우수하다.
VQAv2 에서 저자의 방법은 500K TPU hour 과 십억 개 규모 데이터셋을 사용한 Flamingo 보다 5.6 point 이상 앞섰다.
A-OKVQA 에선 Img2LLM 이 최고의 결과이며 ClipClap 을 두 배 앞선다.
Img2LLM 은 대부분의 supervised model 보다 성능이 좋은데, 이는 zero 훈련 데이터를 사용하고 zero-shot setup 에서 평가되었는데도 불구하고 효과적임을 입증한다.
4.3 Experimental Results of Different LLMs

Img2LLM 을 OPT 와 다른 오픈 소스 LLM (GPT-J, GPT-Neo 및 BLOOM) 에서 성능 평가를 진행한다.
실험 결과 Img2LLM 은 zero-shot VQA task 수행에 있어 다양한 LLMs 가 가능하며, zero-shot PICa 및 Fozen 성능 만큼 도달했다.
이는 저자의 방법의 일반화 성능이 강하다는 것을 보여준다.
5. Limitation
- image caption 및 question-answer 생성에 추가 비용 발생
- 8XA100 기기에서 175B OPT 의 추론 시간에 비해 약 24.4% 의 추가 계산 요구
prompt 를 줄여 오버헤드를 줄일 수 있으며, 이는 정확성을 희생하고 속도를 얻겠다는 것이다. 특히, 저자의 방법은 Flamingo 의 경우인 500K TPU 시간 이상 소요되는 비싼 end-to-end multimodal representation 정렬을 피하는 것이다.
