
Multi-GPU
- 다중 GPU에 학습을 분산하는 두 가지 방법: 모델을 나누기 vs 데이터를 나누기
Model parallel
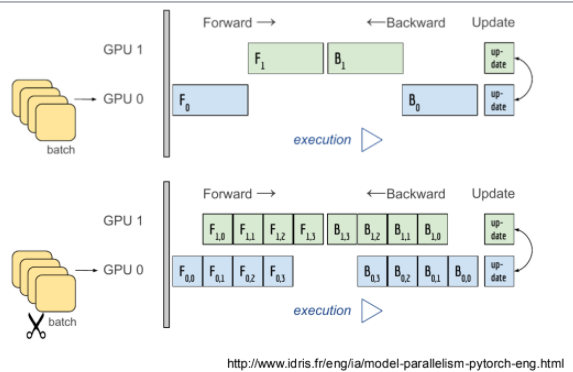
class ModelParallelResNet50(ResNet):
def __init__(self, *args, **kwargs):
super(ModelParallelResNet50, self).__init__(Bottleneck, [3, 4, 6, 3], num_classes=num_classes, *args, **kwargs)
self.seq1 = nn.Sequential(
self.conv1, self.bn1, self.relu, self.maxpool, self.layer1, self.layer2).to('cuda:0') # cuda 0
self.seq2 = nn.Sequential(
self.layer3, self.layer4, self.avgpool).to('cuda:1') # cuda 1
self.fc.to('cuda:1')
def forward(self, x): # 두 모델을 다시 연결
x = self.seq2(self.seq1(x).to('cuda:1'))
return self.fc(x.view(x.size(0), -1))Data parallel
- 데이터를 나눠 GPU에 할당후 결과의 평균을 취하는 것
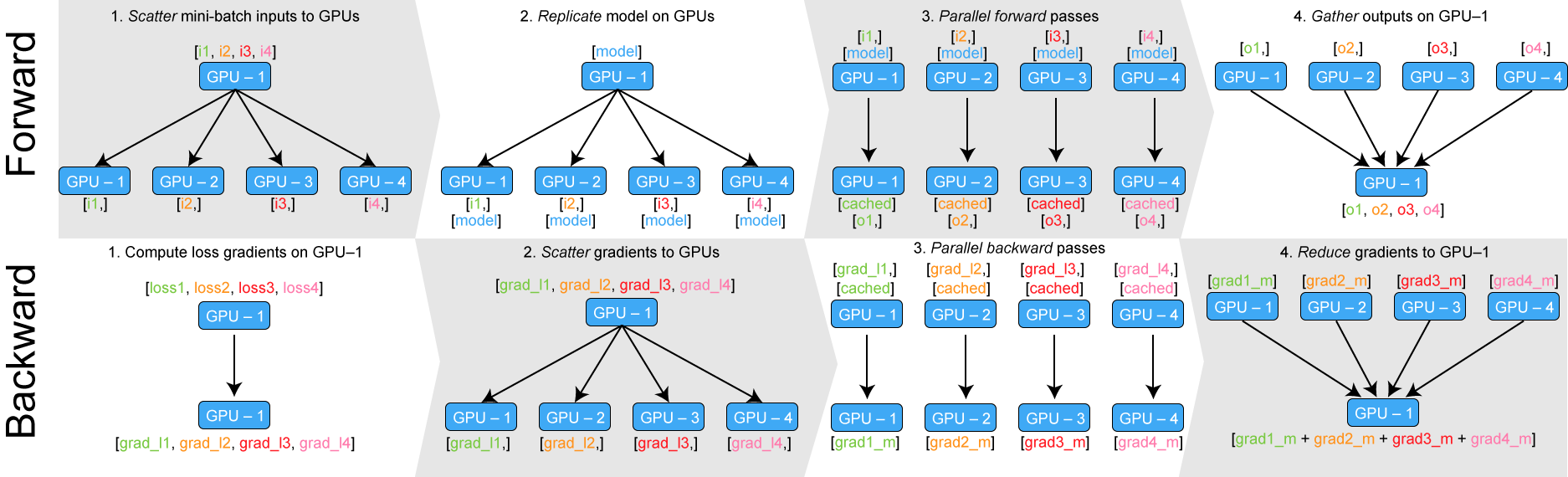
- PyTorch에서는 다음과 같은 두 가지 방식을 제공
DataParallel- 단순히 데이터를 분배한후 평균을 취함(병목현상 등으로 인해 GPU불균형 문제가 발생할 수 있음)

- 단순히 데이터를 분배한후 평균을 취함(병목현상 등으로 인해 GPU불균형 문제가 발생할 수 있음)
DistributedDataParallel- 각 CPU마다 process를 생성하여 개별 GPU에 할당
- 개별적으로 연산의 평균을 냄(중앙GPU로 모으는 작업이 없음)



AI Engineer : Lv 0