데이터베이스
1. key
2. SQL
3. SQL Injection
4. SQL vs NoSql
5. 정규화
6. 인덱스 (Index)
7. 트랜잭션 (Transaction)
- 키란 ?
- 각 튜플을 고유하게 식별할 수 있는 하나 이상의 애트리뷰트의 모임
- 특정 튜플을 검색하거나, 다른 튜플들과 연관시킬 수 있도록 사용하는 목적
1-2. super key vs candidate key , composite key
- 수퍼키
- 특정 튜플을 고유하게 식별하는 하나의 애트리뷰트 or 애트리뷰트의 집합- 키의 조건이 만족되면서 최소성은 만족되지 않아도 됨
- 후보키
- 각 튜플을 고유하게 식별하는 최소한의 애트리뷰트들의 모임- 키의 조건과 최소성이 만족되어야함
- 복합키
- 두 개 이상의 애트리뷰트로 구성되는 후보 키- 후보키의 특성을 따름
1-3. 예제
| 신용카드 번호 | 이름 | 주민등록번호 |
|---|---|---|
| 1 | A | 123456-7890000 |
| 2 | B | 222222-2222222 |
| 3 | C | 333333-3333333 |
--> (신용카드번호), (주민등록번호) 애트리뷰트는 하나만으로 튜플을 고유식별할 수 있기 떄문에 수퍼키, 후보키 모두 가능
but (신용카드,이름)과 같은 애트리뷰트는 최소성에 의하여 수퍼키는 될 수 있지만 후보키가 될 수는 없음, (신용카드번호) 애트리뷰트만으로도 고유식별이 가능하기 때문
| 학번 | 과목번호 | 학점 |
|---|---|---|
| 1 | A1 | A |
| 1 | A2 | B+ |
| 2 | A2 | B+ |
| 2 | A3 | C |
--> 다음과 같은 경우는 하나의 애트리뷰트만으로는 후보키를 구성할 수 없다, (학번, 과목번호)와 같은 식으로 두 개 이상의 애트리뷰트가 있어야 후보키(복합키)가 가능함
1-4. primary key, surrogate key , alternate key
- 기본키
- 한 릴레이션에 후보 키가 두 개 이상 있으면 하나를 기본 키로 선정- 모든 튜플을 고유하게 식별해야하므로 null 값 , 중복 값을 허용하지 않음
- 기본 키는 자연스러운 키를 선정하는 것이 좋음 ( 위의 예시 테이블에서는 신용카드와 주민등록 번호 중 신용카드번호를 기본키로 하는 것이 더 자연스럽다 볼 수 있음 )
- 대리키
- 자연스러운 기본 키를 찾을 수 없을 때, 레코드 번호와 같이 릴레이션에 애트리뷰트를 추가한 키- 기본키를 이용한 수정, 삭제, 외래키 참조에만 효율적
- 자연 키를 대체하여 성능 향상
- 중요한 자료를 대체하여 보안상 이득
- 자연 키를 대체하여 성능 향상
- 기본키를 이용한 수정, 삭제, 외래키 참조에만 효율적
- 대체키
- 기본 키로 선정되지 않는 후보키 ( 위 테이블에서 (신용카드번호), (주민등록번호) 중 신용카드번호가 기본키가 된다면 주민등록번호는 대체 키
1-5. 외래 키
- 어떤 릴레이션의 기본 키를 참조하는 애트리뷰트
- 관계형 데이터베이스에서 릴레이션들 간의 관계를 나타내기 위해 사용
- 외래 키 이름은 대응되는 기본 키와 다른 이름을 가질 수 있음 하지만 참조되는 릴레이션의 기본키와 동일한 도메인을 가져야 함
- 외래 키의 유형
- SQL Injection
- 웹 사이트의 보안상 허점을 이용해 특정 SQL 쿼리 문을 전송하여 공격자가 원하는 데이터베이스의 중요한 정보를 가져오는 해킹 기법
- 클라이언트가 입력한 데이터를 제대로 필터링 하지 못하는 경우 발생
- 공격 난이도가 쉬운거에 비해 피해 규모가 큰 편
2-1. SQL Injection 진행 예시
- 각 클라이언트가 자격증 번호를 조회할 수 있는 시스템
- sql 진행은 doyeon 클라이언가 '자격증 번호 조회'를 클릭하여 doyeon 라는 이름이 웹 서버에 전송되고 db에 입력한 값과 일치하면 자격증 db를 출력
- blackhat 클라이언트는 doyeon 클라이언트의 자격증 번호를 조회하기 이해 sql문을 수정하지만 권한이 없어 자격증 정보를 가져올 수 없음
- ex ) ~/searchname?=doyeon url을 전송할 때 doyeon가 로그인되어 있으면 정상적으로 자격증 번호를 조회할 수 있지만 blackhat이 로그인 되어 있으면 자격증 번호를 조회할 수 없음
- 공격자인 blackhat은 url 뒤에 ' or '1'='1'을 넣어줘서 항상 참이 되게 만들어 자격증 번호를 조회해 옴
2-2. 해킹 사례
- 여기어때 해킹
-> 링크텍스트
2017년 3월, 유명한 숙박앱인 '여기 어때'가 해킹을 당함. 대량의 고객 정보와 고객의 투숙정보가 해커에게 유출되었으며 이 중 수천명에게 '모텔서 즐거우셨나요?'라는 식의 협박성의 민망한 문자가 전송되었다고 함
기사에 따르면, 이 사건은 보안이 허술한 특정 웹 페이지를 대상으로 SQL 인젝션 공격을 시도해서 관리자 세션을 탈취하고 이 정보로 관리 페이지에 위장 로그인하여 고객의 개인정보를 유출했다고 함
- 뽐뿌
-> 링크텍스트
2-3. SQL Injection 종류와 공격 방법
1) Error based SQL Injection - 논리적 에러를 이용한 SQL Injection
- 2-1 예시의 기법으로 해당 기법을 sql 인젝션에 대한 기본을 설명하는게 일반적
- ex) 정상 접근 : select from client where name='doyeon' and password='1234'
SQL 인젝션 : select from client where name='doyeon' and password='or'1'='1'
'or'1'='1' - 다음과 같이 항상 참인 결과를 반환해서 로그인에 성공하게 함
2) UNION based SQL Injection = UNION 명령어를 이용한 SQL Injection
- SQL UNION이란 여러개의 SQL문을 합쳐 하나의 SQL문으로 만들어주는 방법
- UNION과 UNION ALL로 나뉘는데 중복 값을 제외하고 안하고의 차이
- ex) UNION 예시 : select name from Aclass union select name from Bclass; 하게 된다면 A클래스와 B클래스 이름들이 합쳐져 출력 됨, UNION으로 합쳐지는 두 테이블은 컬럼 갯수가 일치해야만 오류가 나지 않음
- 외부 입력 : ID / test' UNION SELECT 1,1 --
PW / anything - 실행 쿼리 : select * from users where id = 'test' UNION select 1,1 -- and PW='anything'
- 쿼리가 실행되면 users 테이블에 등록된 id와 pw 목록을 전부 조회할 수 있게 됨
3) Blind SQL Injection - Boolean based Blind SQL Injection
- SQL vs NoSQL
- sql은 StructuredQueryLanguage 약자로 그 자체가 db가 아님
- sql은 관계형 데이터베이스 관리 시스템(RDBMS)의 데이터를 관리하기 위해 설계된 특수 목적의 ㅡ로그래밍 언어라고 위키백과에서 설명
- sql db, nosql db라고 표현해야 정확 ( but 나는 SQL , NoSQL - sql이 아니다 x No에스큐엘 o ㅋㅋ 로 정리하겠음 )
- MySql과 같은 sql 혹은 mongoDB같은 NoSql , Node.js에 익숙한 사람은 NoSQL이 더 좋다는 생각을 갖기도 한다고 함 ( 일단 나는 익숙하지 않기 때문에 NoSQL과 낯가립니다 )
3-1. SQL ( 관계형 데이터베이스 )
- SQL은 '구조화된 쿼리 언어'의 약자 ( 데이터베이스 자체를 나타내는 것이 아닌, 특정 유형의 데이터베이스와 상호 작용하는 쿼리 언어 )
- SQL을 사용하면 관계형 데이터베이스 관리시스템에서 데이터를 저장, 수정, 삭제 및 검색을 할 수 있음
** 관계형 데이터 베이스 특징 : 정해진 엄격한 데이터 스키마 (== structure)를 따라 데이터 베이스 테이블에 저장, 데이터는 관계를 통해서 연결된 여러개의 테이블에 분산 됨
1) 엄격한 스키마
- 데이터는 테이블에 레코드로 저장되며, 각 테이블에는 명확하게 정의된 구조가 있음
( 구조란 어떤 데이터가 테이블에 들어가고 어떤 데이터가 그렇지 않을지를 정의하는 필드 집합을 가르킴 ) - 구조는 필드의 이름과 데이터 유형으로 정의
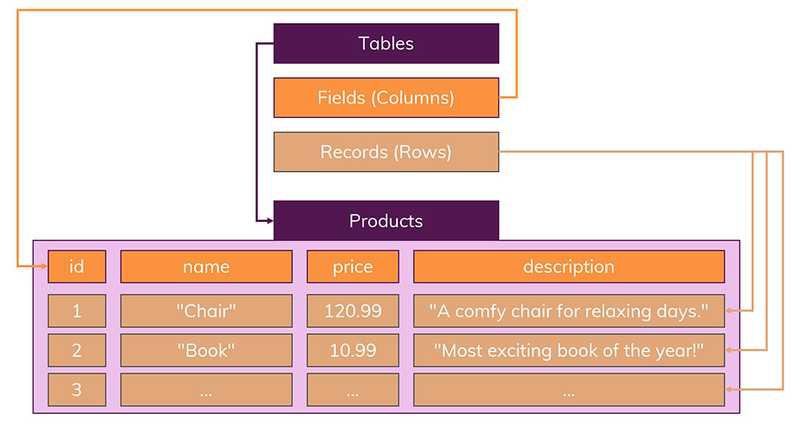
- 관계형 데이터 베이스에서는 스키마를 준수하지 않는 레코드를 추가할 수 없음 ( 더 많은 필드를 얻고 싶은 경우 다른 테이블을 선택해야 함 ex ) 위 테이블에 없는 유통기한이라는 새로운 필드 내용을 추가하고 싶다면 스키마를 고치지 않는 이상 필드를 추가할 수 없음 )
2) 관계
- 데이터들을 여러개의 테이블에 나누어서 데이터들의 중복을 피할 수 있음
- ex) 만약 사용자가 구입한 상품들을 나타내기 위해서는 User(사용자), Products(상품), Order(주문한 상품) 같이 여러 테이블을 만들어야하지만, 각각의 테이블들은 다른 테이블에 저장되지 않은 데이터만을 가지고 있음 ( 중복 데이터가 없음 )
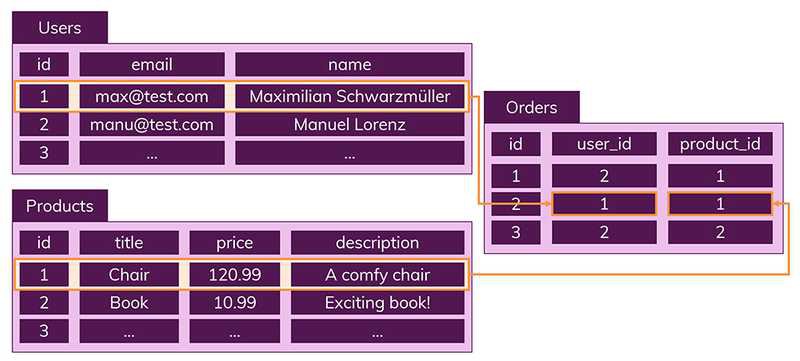
- 이러한 구조는 하나의 테이블에서 중복 없이 하나의 데이터만을 관리하기 때문에 다른 테이블에서 부정확한 데이터를 다룰 위험이 없음
3) 장점
- 명확하게 정의된 스키마, 데이터 무결성 보장
- 관계는 각 데이터를 중복 없이 한번만 저장됨
4) 단점
- 상대적으로 덜 유연하다 볼 수 있음 ( 데이터 스키마는 사전에 계획되고 알려져야하기 때문에 나중에 수정하기가 번거롭거나 불가능할 수 있음 )
- 관계를 맺고 있기 때문에 JOIN문이 많은 매우 복잡한 쿼리가 만들어질 수 있음
- 수평적 확장이 어렵고, 대체로 수직적 확장만 가 ( 처리할 수 있는 처리량과 관련해서 보았을 때 성장 한계에 직면할 수 있다 볼 수 있음 )
3-2. NoSQL
- 이름을 보고 관계형 데이터 베이스와는 다른 접근 방식을 가짐을 알 수 있음
1) '스키마'와 '관계' 없음
- NoSQL은 레코드를 문서라고 부름 ( 단순한 이름 차이가 아닌 관계형데이터베이스에서는 정해진 스키마를 따르지 않으면 데이터를 추가할 수 없지만, NoSQL에서는 다른 구조의 데이터를 같은 컬렉션(= SQL에서의 테이블)에 추가할 수 있다는 의미 )
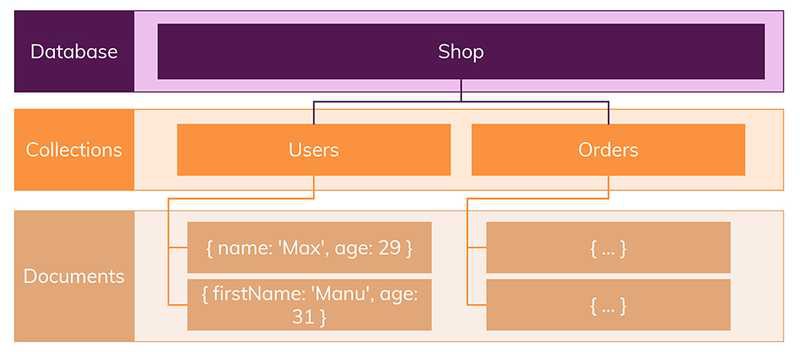
- 스키마에 대해서는 신경을 접어두어도 됨 ( 일반적으로 관련 데이터를 동일한 컬렉션에 넣음, 관계형 데이터베이스처럼 여러 테이블에 나누어 담지 않음 )
- ex) 주문상품(Order)이 있는 경우, 일반적인 정보를 모두 포함한 데이터를 Order에 포함해서 한꺼번에 저장, 관계형 데이터베이스에서 사용했던 Users나 Products 정보 또한 Orders에 포함해서 한번에 저장)
- 따라서 여러 테이블/ 콜렉션에 조인할 필요 없이 이미 필요한 모든 것을 갖춘 문서를 작성하게 됨 ( NoSQL데이터베이스는 조인이라는 개념이 존재하지 않음, 만약 조인을 하고 싶으면 직접 해당 외래키를 검색하여 사용할 순 있지만 일반적인 방법이라고 할 순 없음 )
- 컬렉션을 통해 데이터를 복제하여 각 컬렉션 일부분에 속하는 데이터를 정확하게 산출하도록 함
- 문서는 JSON 데이터와 비슷한 형태를 띄고 있음
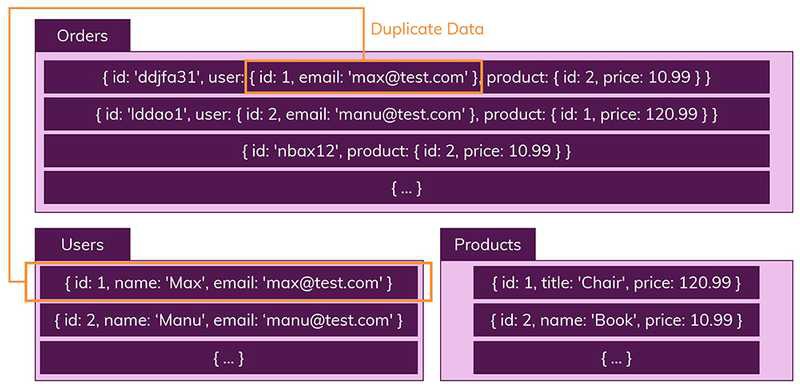
- 데이터가 중복되기 때문에 불안정한 측면이 있음
- ( ex ) 컬렉션 b에서는 데이터를 수정하지 않았는데 컬렉션 A에서만 데이터를 업데이트하게 되면 상이한 같은 데이터를 저장해야하지만 저장된 데이터 내용이 다르게 업데이트 될 수 있음 )
- 특정 데이터를 같이 사용하는 모든 컬렉션에서 똑같은 데이터 업데이트가 수행되도록 해야함
--> 그럼에도 해당 방식의 장점은 복잡하고 ( 구조적으로 얽혀있는 ) 속도가 느릴 수 있는 조인을 사용할 필요가 없다는 점 ( 필요한 모든 데이터가 이미 하나의 컬렉션 안에 저장되어 있기 때문에 자주 변경되지 않는 데이터일 수록 더 큰 강점을 갖음
2) 장점
- 스키마가 없기 때문에 더 유연함 ( 언제든 저장된 데이터를 조정하고 새로운 '필드'를 추가할 수 있음 )
- 데이터는 애플리케이션이 필요로 하는 형식으로 저장됨 ( 데이터를 읽어오는 속도가 빨라짐 )
- 수직 및 수평 확장이 가능하므로 데이터베이스가 애플리케이션에서 발생시키는 모든 읽기/ 쓰기 요청을 처리할 수 있음
3) 단점
- 유연성 때문에 데이터 구조 결정을 하지 못하고 미루게 될 수 있음
- 데이터 중복은 여러 컬렉션과 문서가 여러 개의 레코드가 변경된 경우 업데이트를 다 해줘야함 ( sql 처럼 하나의 테이블에 하나의 레코드가 아니기 때문 )
- 데이터가 여러 컬렉션에 중복되어 있기 때문에 수정(update)를 해야하는 경우 모든 컬렉션에서 수행해야 함을 의미 ( sql은 중복된 데이터가 없기 때문에 한번만 수행하면 됨 )
3-3. 수직적(Verical) & 수평적(Horizontal) 확장(Scaling)
- 두 종류의 데이터베이스를 비교할 때 봐야할 또 하나의 중요한 개념 '확장' ( 데이터베이스의 서버 확장성 )
1) 수직적 확장
- 단순히 데이터베이스 서버의 성능을 향상시키는 것 ( ex) CPU를 업그레이드 하는 방식 )
2) 수평적 확장 - 더 많은 서버가 추가되고 더 데이터베이스가 전체적으로 분산됨을 의미 ( --> 하나의 데이터베이스에서 작동하지만 여러 호스트에서 작동됨을 의미 )
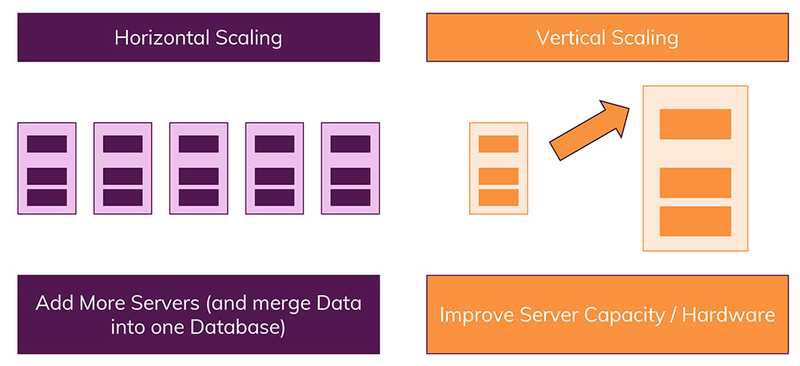
- 이러한 차이가 있는 이유는 '데이터가 저장되는 방식' 때문
- 관계형 데이터베이스는 일반적으로 수직적 확장만을 지원
- 수평적 확장은 NoSQL 데이터베이스에서만 가능
- 관계형 데이터베이스는 샤딩(Sharding)의 개념이 있긴 하지만 특정 제한이 있으며 구현하기 대체로 어려워 사용하지 않는 편
- NoSQL은 기본적인 지원으로 여러 서버에서 데이터베이스를 쉽게 분리 가능
3-4. SQL , NoSQL 선택
1) SQL이 사용되면 좋은 경우
- 관계를 맺고 있는 데이터가 자주 변경되는 애플리케이션일 경우
- 변경될 여지가 없고 명확한 스키마가 사용자와 데이터에게 중요한 경우
2) NoSQL이 사용되면 좋은 경우
- 정확한 데이터 구조를 알 수 없거나 변경/확장 될 수 있는 경우
- 읽기(read)처리를 자주하지만, 데이터를 자주 변경(update)하지 않는 경우
- 데이터베이스를 수평으로 확장해야하는 경우 ( == 방대한 양의 데이터를 다뤄야하는 경우 )
--> 상황에 맞게 선택하면 됨, sql의 경우 요구사항을 만족시키고 복잡한 join문을 만들지 않거나 nosql의 경우 중복 데이터를 줄이고 설계를 한다거나 하는 방식으로 단점은 어느정도 중화(?) 가능하므로 장점 위주로 보자 .~! 익숙한 것 사용하자 .~! 라는 결론이 나버렸다 .. 스읍 ..
3-5. Property
1) SQL - ACID properties
- ACID(db의 Transaction이 안전하게 수행된다는 것을 보장하기 위한 특징) 특성을 따름
- Atomicity(원자성) : 트랜잭션의 작업이 부분적으로 실행되거나 중단되지 않는 것을 보장하는 것
- Consistency(일관성) : 미리 정의된 규칙에서만 수정이 가능한 특성을 의미
- Isolation(고립성) : 트랜잭션 수행시 다른 트랜잭션의 작업이 끼어들지 못하도록 보장하는 것
- Durability(영구성) : 성공적으로 수행된 트랜잭션은 영원히 반영이 되는 것을 의미
** 트랜잭션 : 여러 작업들을 하나로 묶은 단위
2) NoSQL - CAP theorem
- CAP( 분산 시스템에서는 CAP 세가지 속성을 모두 만족하는 것은 불가능하며, 오직 두가지만 만족할 수 있다는 것으로 정의 ) 이론을 따름
- Consistency (일관성) : 모든 요청은 최신 데이터 또는 에러를 응답받음 (DB가 3개로 분산되었다고 가정할 때, 하나의 특정 DB의 데이터가 수정되면 나머지 2개의 DB에서도 수정된 데이터를 응답받아야 함)
- Availability (가용성) : 모든 요청은 정상 응답을 받음 (특정 DB가 장애가 나도 서비스가 가능해야 함)
- Partitions Tolerance (분리 내구성) : DB간 통신이 실패하는 경우라도 시스템은 정상 동작 함
