Python Library - Pandas(7)

본 게시물은 코드프레소의 code.PRESS-UP 체험단 과정을 담은 게시물입니다.
해당 게시물 수강강좌 :
파이썬으로 배우는 데이터 분석 : Pandas
Pandas 라이브러리로 데이터 분석 시작하기
지난 포스팅에서는 DataFrame의 인덱스를 설정하는 set_index()에 대해서 알아보았습니다.
이번 포스팅에서는 본격적으로 데이터 조회를 위한 인덱싱을 알아보겠습니다.
시작하기 앞서 예제에서 사용할 데이터를 가져옵시다.
해당 데이터들은 KOSIS국가통계포털에서 찾을 수 있었던 2020년 6월 행정구역별 인구수입니다.
import pandas as pd
df = pd.read_excel('./행정구역인구수.xlsx', sheet_name='데이터변경', engine='openpyxl')
df.columns = ['region', 'tot_num', 'm_num', 'f_num']
df = df.set_index('region')
df[['tot_num', 'm_num', 'f_num']] = df[['tot_num', 'm_num', 'f_num']].astype('int64')
df.head()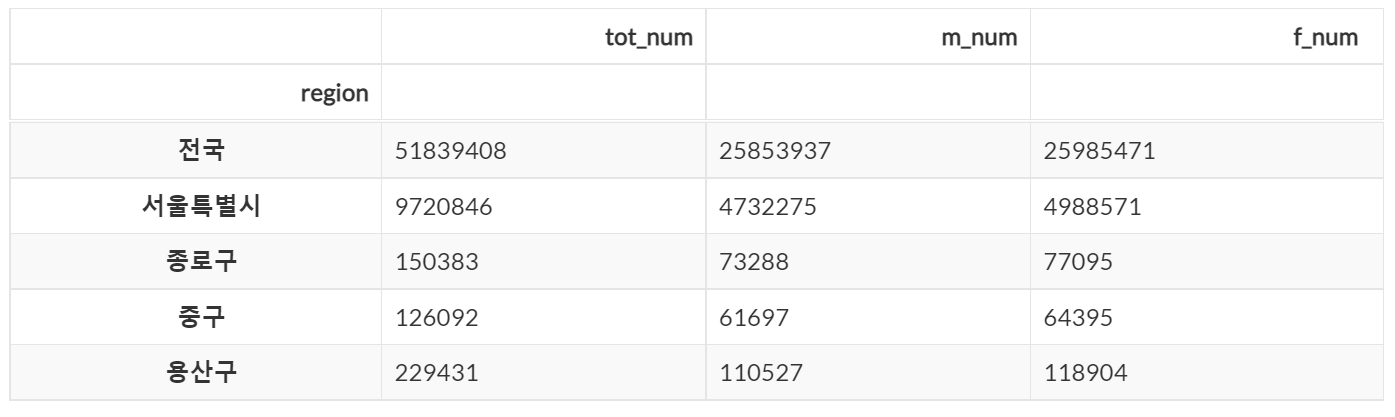
head() 메소드를 통해 상위 5개의 데이터만 결과값에 반환한 상태
1. loc[]
📌 인덱스 명(값)을 기준으로 행 데이터 조회(Location)
dataframe.loc[['index values']]📌 행의 인덱스 명을 이용하여 행 데이터에 접근할 수 있음
📌 SQL의 WHERE절과 유사하다. pandas에서 유용한 메소드
다음과 같은 데이터가 있다고 가정했을 시
loc 메소드를 활용하여 여러형식으로 데이터를 추출할 수 있다.
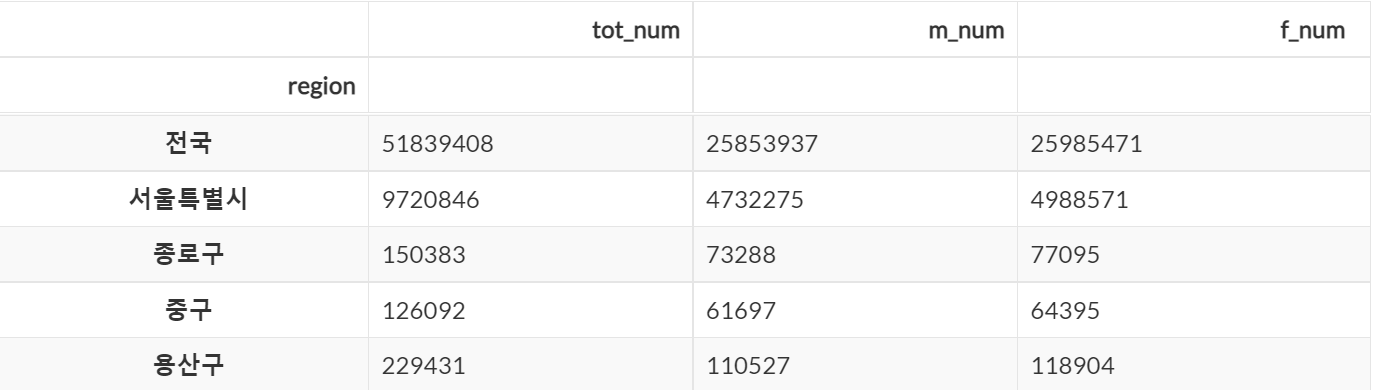
1-1. 행 데이터 조회
💻 특정 행 조회
# 하나의 특정 행만을 조회(Series 형태)
dataframe.loc['전국']
# 결과
tot_num 51839408
m_num 25853937
f_num 25985471
Name: 전국, dtype: int64
# series로 조회되는 loc반환값을 데이터 프레임으로 변경
dataframe.loc[['전국']]
💻 특정 행 다중 조회
# 특정 행을 여러개 조회하고 싶을 경우
dataframe.loc[['서울특별시', '종로구']]
💻 특정 행 제외후 조회
# 특정 행을 제외하여 가져오고 싶은 경우 !=을 이용
dataframe.loc[dataframe.index != '전국'].head(5)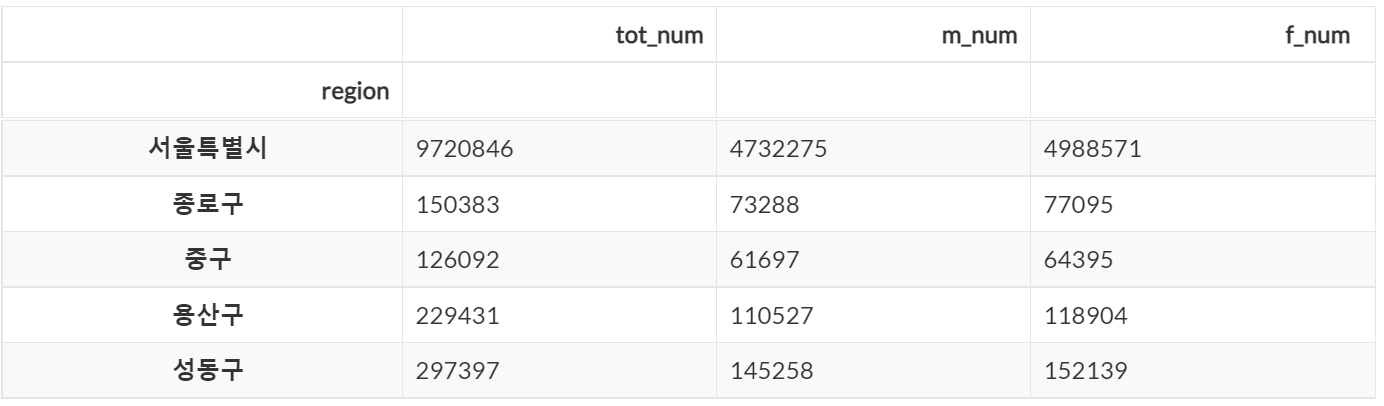
💻 특정 범위의 연속 행 조회
#슬라이싱을 이용해서 연속 행 조회
dataframe.loc['서울특별시' : '용산구']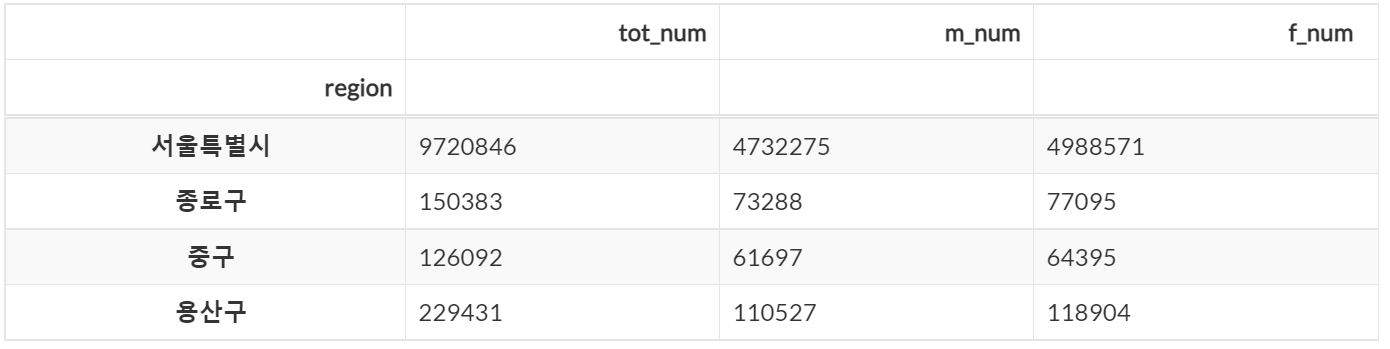
1-2. 열 데이터 조회
열을 조회하는것은 행을 조회하는것 이랑 크게 다르지 않다. 단순이 : 와 , 을 이용한다는 것이다. list에서 열을 조회하는 방법과 비슷하다.
💻 특정 열 조회
# 특정 열 하나를 조회
dataframe.loc[:, ['tot_num']].head(5)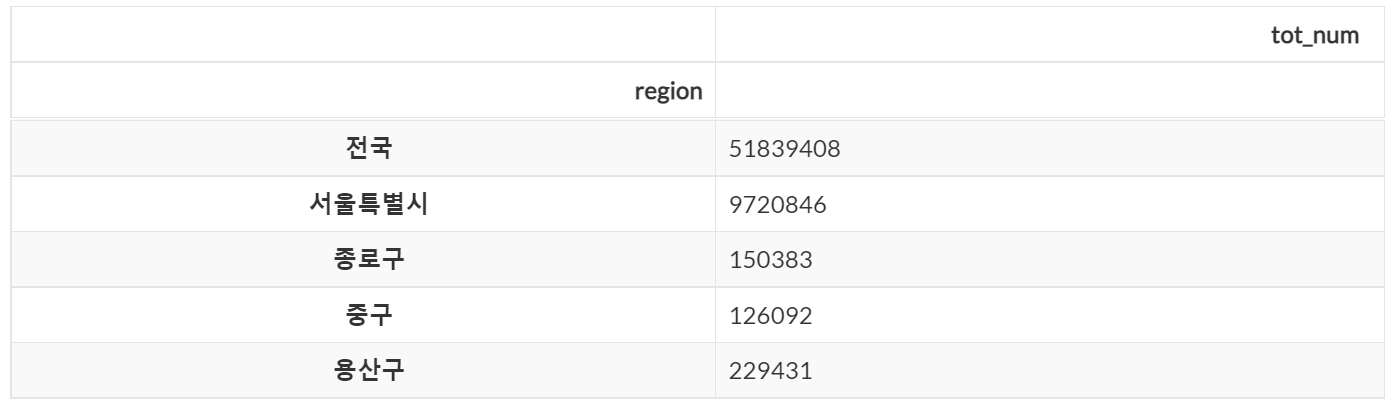
💻 특정 열 다중 조회
# 특정 열 다중 조회
dataframe.loc[:, ['tot_num', 'm_mum']].head(5)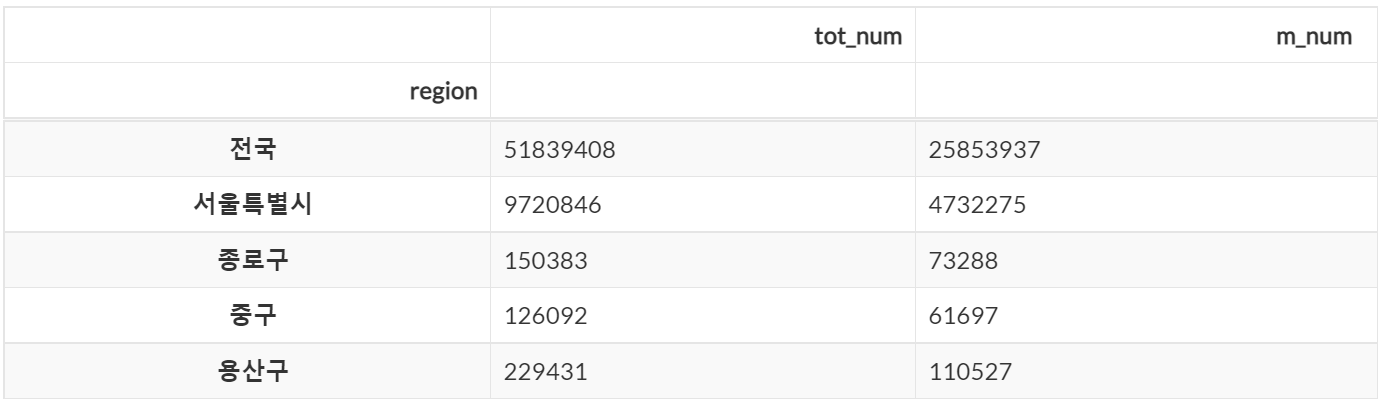
💻 특정 열 제외 후 조회
dataframe.loc[:, dataframe.columns != 'm_num'].head(5)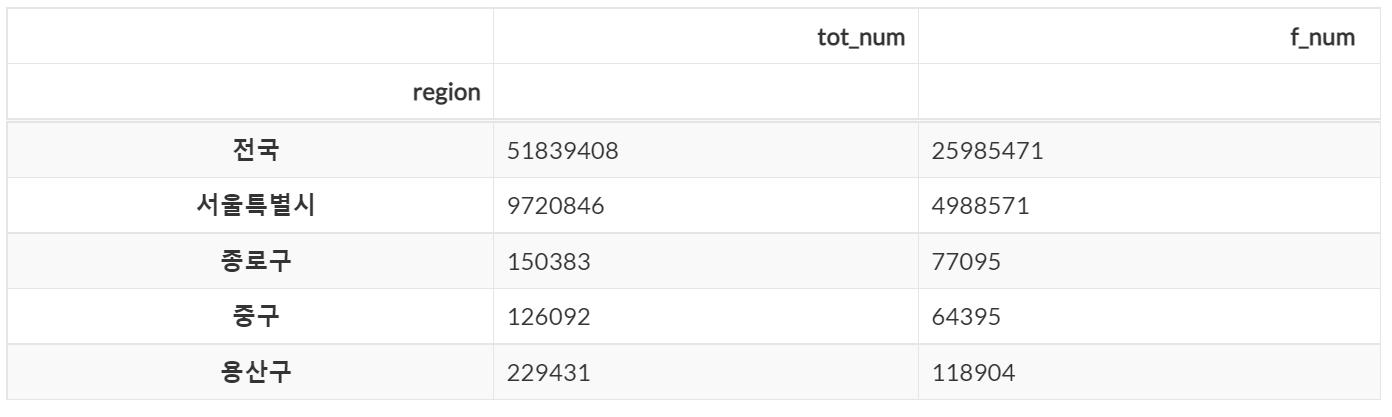
💻 특정 범위의 연속 열 조회
# 슬라이싱을 이용해서 연속 열 조회
dataframe.loc[:, 'tot_num' : 'f_num'].head(5)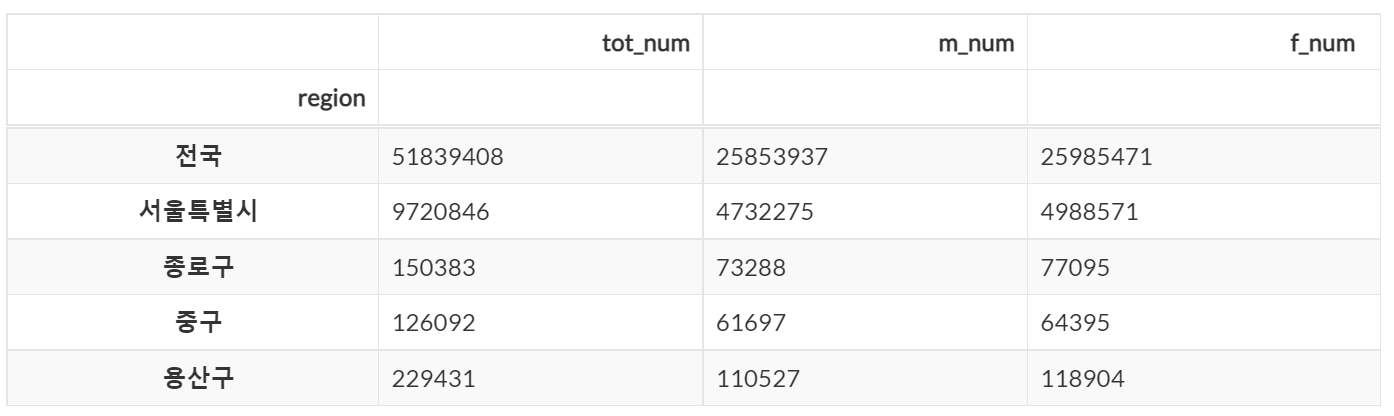
1-3. 행과 열 데이터 조회
특정 행과 열을 동시에 조회하는 것은 위 두가지 방법을 혼합하여 조회하는 것이다.
# 슬라이싱을 이용해 행과 열을 제한하여 조회
dataframe.loc['서울특별시' : '용산구', 'm_num' : 'f_num']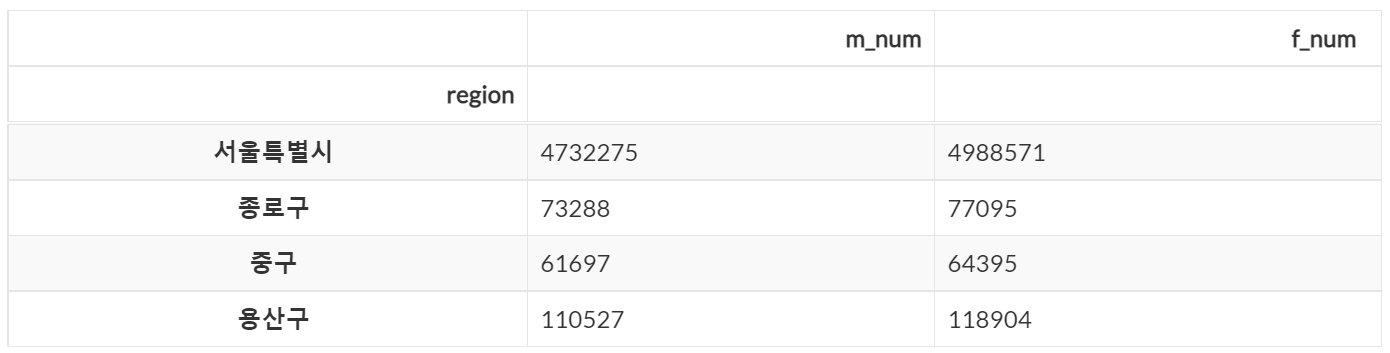
# 특정 값을 출력
dataframe.loc['서울특별시', 'tot_num']
result
>> 9720846# 특정 조건을 만족하는 값을 출력# 조건 1개
dataframe.loc[df['m_num'] <= 70000].head(5)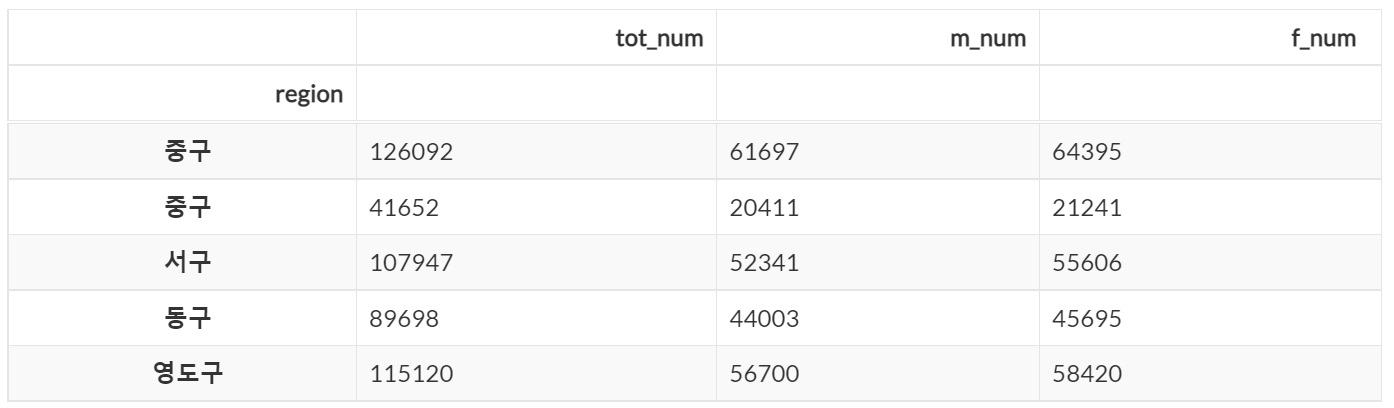
# 조건 2개
dataframe[(dataframe['m_num'] <= 70000) & (df['f_num'] <= 70000)].head(5)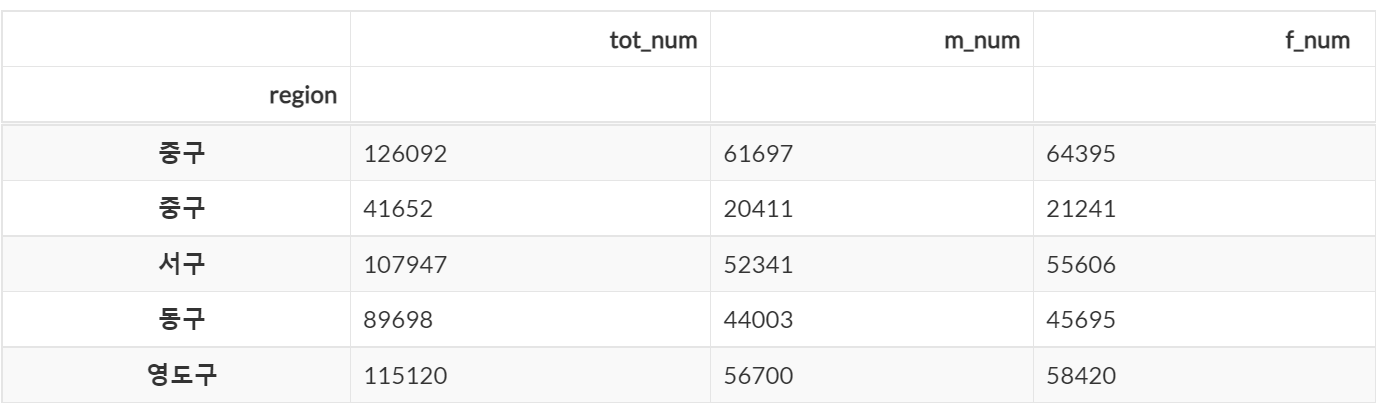
# 조건 2개 + 특정 컬럼만 출력
dataframe.loc[(df['m_num'] <= 70000) & (df['f_num'] <= 70000), ['tot_num']].head(5)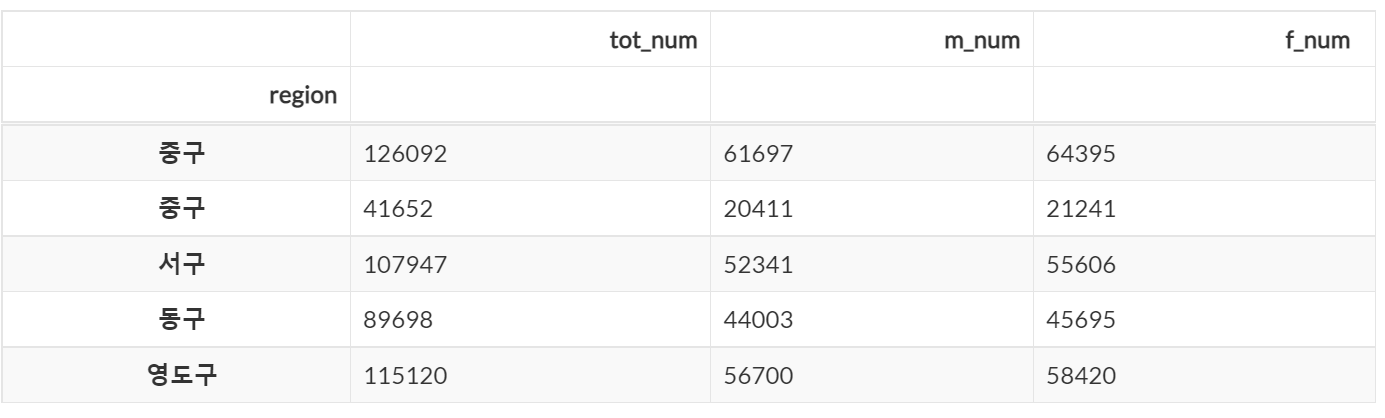
2. iloc[]
Integer location의 약어로, 데이터프레임의 행이나 칼럼의 순서를 나타내는 정수로 특정 값을 추출해오는 메소드이다. loc는 칼럼명을 직접 적거나 특정 조건식을 써줌으로써 사람이 읽이 좋은 방법으로 데이터에 접근하는 방법이었다면,
iloc는 컴퓨터가 읽기 좋은 방법으로 데이터가 있는 위치에 접근한다.
datafraem.iloc['index_num', 'column_num']loc의 사용방법에서 인덱스 숫자로 값을 추출한다.
즉, loc의 String을 index_int로 바꾸어 값을 추출하면 똑같은 결과가 반환된다.
dataframe.iloc[[0]]
dataframe.iloc[[0, 1, 3, 5]]
dataframe.iloc[1:4]pandas를 통해 데이터프레임을 다루는데에 있어 코드프레소 강의가 큰 도움이 되고 있습니다. 몰랐던 메소드 개념부터 활용까지 꼼꼼하게 짚고 넘어가고 있습니다.
다음 포스팅은 Pandas의 집계함수에 대해 자세하게 알아보겠습니다.
이 역시 코드프레소 강의와 함께 알아보도록 하겠습니다.
