Python Library - Pandas(2)

본 게시물은 코드프레소의 code.PRESS-UP 체험단 과정을 담은 게시물입니다.
해당 게시물 수강강좌 :
파이썬으로 배우는 데이터 분석 : Pandas
Pandas 라이브러리로 데이터 분석 시작하기
Pandas 구성 - 기본 자료구조
1-1. Series
Series는 1차원 데이터를 저장하는 Pandas의 기본 자료구조로, 리스트, 튜플, 딕셔너리 등의 파이썬 객체를 함수의 data 인자로 전달하여 다양한 형태로 생성할 수 있고, Series 객체는 동일한 데이터 타입의 값을 저장할 수 있다는 특징이 있다.
물론, Series 안의 데이터들은 모두 같은 타입이여야 저장이 가능하다.
year = ['2019', '2020', '2021', '2022']
result = pd.series(data = year)
print('nType: ', type(result))
print(result)Type: <<class 'pandas.core.series.Series'>
0 2019
1 2020
2 2021
3 2022주요 속성
- .index : 개별데이터를 고유하게 식별하는 일종의 key 값
- .values : Series 객체내 모든 데이터 값
- .dtype : Series 객체에 저장된 데이터의 타입
- .shape : Series 객체의 모양
- .name : Series 객체(데이터)의 이름
- .index.name : Series 객체의 인덱스(index)의 이름
1-2. Series 생성
pd.Series(data, index, name)
- index : Series 객체 생성시 index 설정
- name : Series 객체 생성시 이름 지정
year = ['2019', '2020', '2021, '2022'] idx = ['a', 'b', 'c', 'd'] result = pd.Series(data = year, index = idx, name='Year') print(result)a 2019 b 2020 c 2021 d 2022 Name : Year, dtype:object# 딕셔너리 데이터로 Series 생성 score = {'Kim':85, 'Han':89, 'Lee':99, 'Choi':70} result = pd.Series(data = score, name = 'Score') print(result)Kim 85 Han 89 Lee 99 Choi 70 Name : Score, dtype: int64
2-1. DataFrame
DataFrame 은 행과 열을 가진 2차원 자료 구조로 Pandas 의 핵심 자료구조입니다. DataFrame에서 함수의 인자로 다양한 파이썬 객체들이 입력될 수 있습니다. 또한 각 컬럼은 서로 다른 데이터 타입으로 구성될 수 있다는 특징이 있습니다.
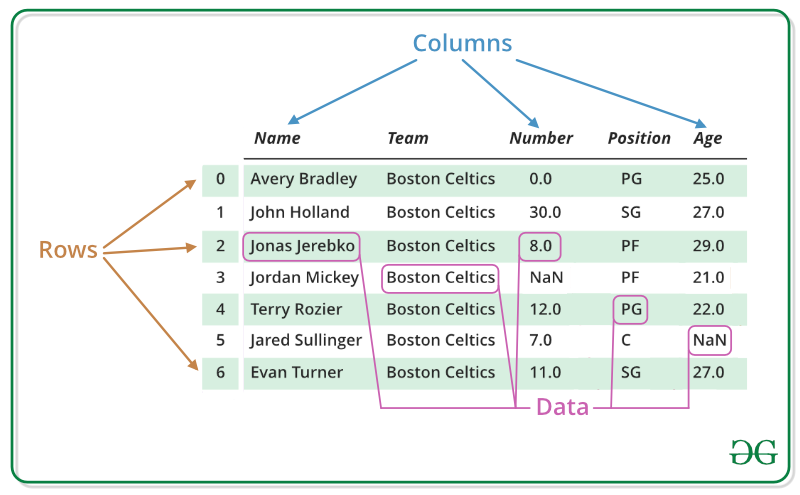
2-2. DataFrame 생성
pd.DataFrame(data, index, columns)
Parameters :
- data : DataFrame에 저장할 데이터 객체
- index : DataFrame의 행의 인덱스, 순서를 지정
- columns : DataFrame의 열의 인덱스, 순서를 지정
2-3. DataFrame의 주요 속성
- .index : DataFrame 객체의 행 인덱스
- .columns : DataFrame 객체의 열 인덱스
- .values : DataFrame 객체에 저장된 데이터에 접근
- .dtypes : DataFrame 객체에 저장된 각 컬럼별 데이터 타입 출력
- .shapes : DataFrmae 객체에 저장된 행과 열에 대한 크기 정보 반환
3-1. Summary
Pandas 의 대표적인 자료구조인 DataFrame 은 행과 열을 가지는 2차원 데이터를 저장할 수 있는 자료구조입니다. 각 컬럼은 서로 다른 데이터 타입의 데이터들로 구성될 수 있으며, 각 컬럼 데이터는 Series 객체 타입을 가집니다. 실무에서 가장 많이 다루는 데이터가 2차원 형태의 정형 데이터이기에 파이썬 기반의 데이터 분석을 위해서는 Pandas 의 DataFrame 에 대한 이해가 중요합니다.
DataFrame Summary
행과 열을 가진 2차원 데이터를 저장할 수 있는 자료 구조
각 컬럼은 서로 다른 데이터 타입으로 구성될 수 있음
1개의 컬럼은 Series 객체로 구성됨
3-2. DataFrame 생성
pd.DataFrame( data, index, columns)
주요 인자 소개
data : DataFrame 을 구성하는 다양한 형태의 파이썬 객체를 전달하여 생성 가능함
index : DataFrame 의 행의 인덱스를 지정
columns : DataFrame 의 열의 인덱스를 지정
주요 속성 소개
.index : DataFrame 객체의 행 인덱스
.columns : DataFrame 객체의 열 인덱스
.values : DataFrame 객체에 저장된 데이터
.dtypes : DataFrame 객체에 저장된 각 컬럼별 데이터 타입
.shape : DataFrame 객체에 저장된 행과 열에 대한 크기 정보
#예제 코드
import pandas as pd
import numpy as np
# 주어진 series 데이터를 이용하여 DataFame 을 생성
series = {'one': pd.Series([1., 2., 3.], index=['a', 'b', 'c']),
'two': pd.Series([1, 2, 3, 4], index=['a', 'b', 'c', 'd'])}
result = pd.DataFrame(series)
print(result)
print('\n')
# 딕셔너리가 저장된 리스트 객체(data)를 이용하여 index 가 있는 DataFrame 을 생성
data = [{'a': 1, 'b': 2}, {'a': 5, 'b': 10, 'c': 20}]
idx = ['row1', 'row2']
result = pd.DataFrame(data, index=idx)
print(result)
print('\n')
# 주어진 ndarray 데이터를 이용하여 index 와 column이 지정된 DataFrame 을 생성
arr = np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]])
col = ['col1', 'col2', 'col3']
idx = ['row1', 'row2', 'row2']
result = pd.DataFrame(arr, columns=col, index=idx)
print(result)#결과
one two
a 1.0 1
b 2.0 2
c 3.0 3
d NaN 4
a b c
row1 1 2 NaN
row2 5 10 20.0
col1 col2 col3
row1 1 2 3
row2 4 5 6
row2 7 8 9
지금까지 포스팅은 가벼워 보이지만 매우 중요한 내용입니다.
코드프레소 강의에서도 강조한 부분이기도 합니다.
DataFrame은 pandas를 구성하는 가장 기초적이면서 중요한 자료구조입니다.
지속적으로 복습하는것이 좋을 것 같습니다.
다음 포스팅은 pandas 라이브러리의 DataFrame을 다루는 여러 기초 메소드를 코드프레소 강의와 함께 작성될 예정입니다.
