
본 게시물은 코드프레소의 code.PRESS-UP 체험단 과정을 담은 게시물입니다.
해당 게시물 수강강좌 :
파이썬으로 배우는 데이터 분석 : NumPy
NumPy 라이브러리로 데이터 분석 시작하기
NumPy의 데이터타입
NumPy 는 다양한 값을 저장 및 표현할 수 있는 다양한 데이터 타입을 제공합니다.
파이썬에서 제공하는 데이터 타입과 호환되며, 대표적인 데이터 타입은 다음과 같습니다.
- np.int64 : (64비트) 정수
- np.float64 : (64비트) 실수
- np.complex : 복소수
- np.bool : Boolean (True, False)
- np.object : 파이썬 객체
- np.str : 문자열
ndarray.astype(dtype)ndarray 에 저장된 데이터를 주어진 dtype 으로 변환해서 반환하는 함수
Parameters :
- dtype : 변경하고자 하는 배열의 데이터 타입
reshape()
np.reshape()
기존 데이터는 유지하면서 차원과 shape 만을 바꾼 배열을 반환
Parameter:
- array : reshape 할 ndarray
- newshape : 변경하고자 하는 shape 값(튜플 형태)
호출방식 (결과는 동일)
- np.reshape(array, newshape)
- array.reshape(newshape)
reshape(-1,N)
기존 데이터를 유지하면서, shape 을 변경하는 방식
shape 은 주어진 N 에 따라 자동으로 추정되어 변경됨
-1 의 자리는 가변적이 됨
NumPy 연산
NumPy 에는 기본적인 산술연산부터, 비교연산, 기타 수학 관련 고급 연산 등 다양한 함수가 구현되어 있습니다.
NumPy에서 제공하는 연산 함수의 리스트는 아래 공식 사이트를 참고해주세요.
Mathematical functions
https://numpy.org/doc/stable/reference/routines.math.html
몇 가지 자주 사용되는 연산 메소드를 코드프레소 강의와 함께 알아봅시다.
예시코드 import numpy as np
a = np.array([20,30,40,50])
b = np.arange(4)
c = a-b
print(c)
print(b**2)
print(10*np.sin(a))
print(a<35)[20 29 38 47]
[0 1 4 9]
[ 9.12945251 -9.88031624 7.4511316 -2.62374854]
[ True True False False]a-b 와 같이 ndarray의 차는 각 요소의 차를 갖는 ndarray를 만듭니다.
b**2 과 같은 지수 연산이나 np.sin(a) 도 마찬가지로 요소 단위로 적용됩니다.
a<35 와 같은 비교 연산자의 경우에는 True, False 의 진리값을 갖는 ndarray가 출력됩니다.
혹은 메소드를 활용하여 연산이 가능합니다.
코드프레소 강의에서는 메소드를 활용한 연산을 예시로 강의하였습니다.
-
더하기 연산 : np.add(x, y) = x + y
-
빼기 연산 : np.substract(x, y) = x - y
-
곱하기 연산 : np.multiply(x, y) = x * y
-
나누기 연산 : np.divide(x, y) = x / y
NumPy 집계
umPy 는 sum(), mean(), count(), min(), max() 등의 다양한 집계함수를 제공하며, 이때 가장 중요한 특징이 데이터의 집계 방향을 결정하는 axis 값 입니다.
axis = None(default)
- 대상 ndarray 의 모든 요소가 연산 대상이 됨
- Default 값이므로 집계 함수 호출시 생략 가능
axis = 0
- 열을 기준으로 동일 인덱스의 요소를 그룹으로 연산함
axis = 1
- 행을 기준으로 동일 인덱스의 요소를 그룹으로 연산함
예시
x.sum(axis = 1) // 열을 기준으로 동일 인덱스의 요소를 그룹연산
x.mean(x, axis =2) // 행을 기준으로 동일 인덱스의 요소를 그룹연산통계 Method
-
평균 : np.mean(x)
-
최대값 : np.max(x) -> 최대값을 나타내주는 함수
-
최대값의 index : np.argmax(x)
-
분산/중앙값/표준편차 : np.var(x), np.median(x), np.std(x)
합계 Method
-
전체 합계 : np.sum(x)
-
누적 합계 : np.cumsum(x) (합계 과정이 출력됨)
조건 Method
출력값을 boolean의 형태로 나타내주는 조건함수들이 있다.
-
np.any(조건) -> 특정 조건을 만족하는 것이 하나라도 있으면 True, 아니면 False를 반환(or의 개념)
-
np.all(조건) -> 모든 원소가 특정 조건을 만족한다면 True, 아니면 False를 반환(and의 개념)
-
np.where(조건, true일때 값, false일때 값) -> 조건에 따라 원하는 값을 얻고 싶을 때 사용하는 함수이다.(if else개념)
BroadCasting
BroadCasting 개념
shape이 같은 두 ndarray에 대한 연산은 쉽게 할 수 있다.
하지만 예외로 broadcasting을 활용해 연산되는 두 ndarray가 다른 shape을 갖는 경우, numpy에서 자동적으로 shape을 맞춰준 후 연산해주는 것이다.
broadcasting 연산 규칙 :
1) 차원의 크기가 1일때 가능하다.
두 배열 간의 연산에서 최소한 하나의 배열의 차원이 1이면 가능하다.
2) 차원의 짝이 맞을 때 가능하다. 차원에 대해 축의 길이가 동일하면 브로드캐스팅이 가능하다.
두 가지 조건은 한꺼번에 이해하여 정리하면 다음과 같다
두 배열이 뒤에서부터 대응하는 축의 크기가 동일하거나, 1이어야만 합니다.
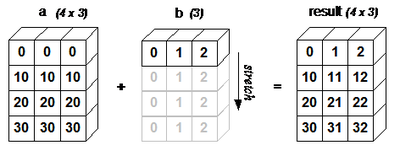
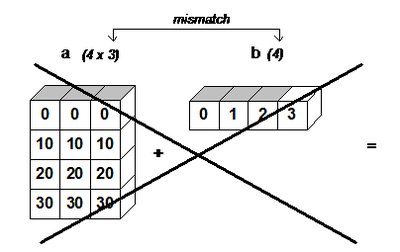
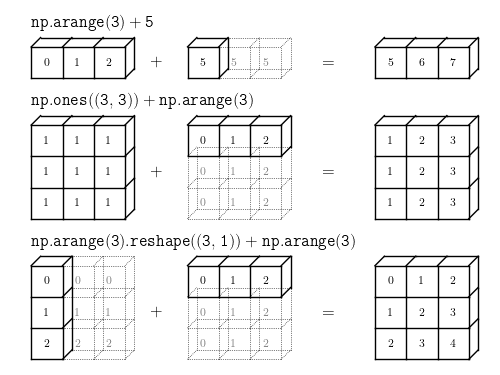
조금 더 자세 하게 조건을 말하면
-
맴버가 하나인 배열은 어떤 배열에나 브로드캐스팅(Broadcasting)이 가능(단, 맴버가 하나도 없는 빈 배열을 제외)
ex) 4x4 + 1
-
하나의 배열의 차원이 1인 경우 브로드캐스팅(Broadcasting)이 가능
ex) 4x4 + 1x4
-
차원의 짝이 맞을 때 브로드캐스팅(Broadcasting)가능
ex) 3x1 + 1x3
코드프레소 강의에서는 브로드캐스팅에 대한 설명은 조금 빈약하며 추가로 공부하여 찾았습니다.
궁금증에서 시작한 브로드캐스팅 공부는 확실하게 개념을 파악하여 활용 할 수 있게 되었습니다.
모르는건 역시 찾아봐야 직성이 풀리는것 같습니다.
