Machine learning Class
AI, Machine learning, Deep learning
-
머신러닝과 딥러닝의 차이점
머신러닝은 어떠한 패턴을 잡아주어서 그것을 훈련시키는것인데
딥러닝은 이상치누락치를 잡아주지않아도 자동으로 바뀌게된다 -
대용량 데이터 처리(Data Engineering), 데이터 분석(Data Analysis)
-
데이터 마이닝(data mining)은
대규모로 저장된 데이터 안에서 체계적이고 자동적으로 통계적 규칙이나 패턴을 찾아 내는 것이다. -
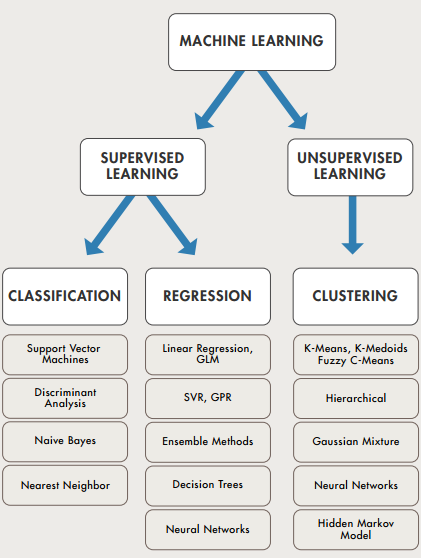
머신러닝 알고리즘의 유형
-
Regression - 회귀, 추세선을 긋는것(모든데이터가 거쳐갈수있는 지점을 선을 그어서 예측)
답이이있는 데이터를 예측해본다(Y데이터가 있다)
[Supervised]
ex) 주가 예측, 경제 성장률 예측, 영화 관람객 예측 -
Classification - 분류, 데이터의 유형을 나누는것(두 지점간 서로가 제일 멀리 있을수있는곳)
결과를 분류한다(Y데이터가 있다)
[Supervised]
ex) 스팸메일여부, 게임어뷰저 여부, 신문기사 분류 -
Clustering - 군집, 데이터를 모으는것, 아무런 사전정보없이 데이터 유형을 나눠보기
결과가 없어도 된다(Y데이터가 없다)
[UnSupervised]
ex) 고객 집단 나누기
- 로지스틱 회귀
Sigmoid 함수를 사용하여서 결과값을 나타내는 방법
Overfitting : 머신러닝을 위해 훈련된값에 너무 잘맞게된다면 새로운 데이터가 입력되었을때
그 데이터를 인식하지못하게된다.
y = ax + b
y : 종속변수(내가 알고자하는것)
x : 독립변수(알고자하는 값에 영향을 주는것)
a, b : 알고리즘을 통해 최적값을 찾음
KEY
- 모델 : 예측을 수학 수학공식, 함수, 1차방정식, 확률분포
- 알고리즘 : 어떠한 문제를 풀기위한 과정 Model을 생성하기위한 훈련과정
연속형값 VS 이산형값
- 연속형값 : 값이 끊어지지 않고 연결되는것
온도, 시험평균점수, 속도등 실수값들을 의미한다
이산형값 : 값이 연속적이지않은것
성별, 우편주소, 등수 Label로 구분되는것
SVM
- 로지스틱 회귀와 함께 분류를 위한 강력한 머신러닝 알고리즘, 퍼셉트론의 개념을 확장하여 적용한 개념
GridSearchCV라는 메서드는 최적의 파라미터를 찾아주게된다.
Noise가 많은 데이터라면 C를 작게 하는것이 좋고
Noise가 적은 데이터라면 C를 많게 해주는것이 좋다.
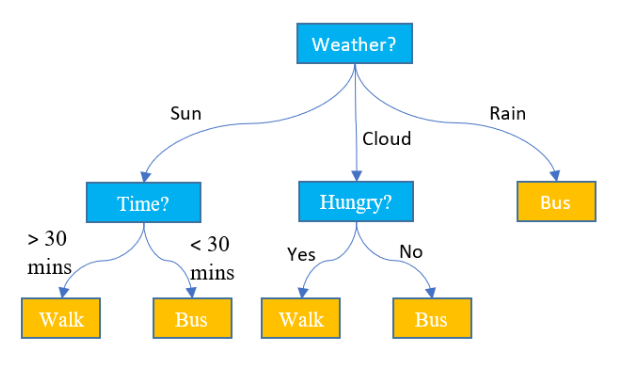
의사결정트리학습(Discision Tree)
-
트레이닝 데이터를 이용해 데이터를 최적으로 분류해주는 질문을 학습하는 머신러닝
질문의 불순도를 측정하여 질문을 수정해나가게된다
불순도를 측정하기위해서는 지니인덱스, 엔트로피 인덱스방법을 사용
불순도: 데이터가 제대로 분류되지 않고 섞여있는 정도
-
교차검증은 데이터 돌려막기다
-
Mean Absoulte Error = MAE
from sklearn.metrics import median_absolute_error
y_true =[3, 0,5, 2, 7]
y_pred = [2, 0.0, 3 ,1]
median_absolute_error(y_true, y_pred) -
Root Mean Squared Error(RMSE)
from sklearn.metrics import mean_squared_error
y_true =[3, 0,5, 2, 7]
y_pred = [2, 0.0, 3 ,1]
mean_squared_error(y_true, y_pred) -
R squared
from sklearn.metrics import r2_score
y_true =[3, 0,5, 2, 7]
y_pred = [2, 0.0, 3 ,1]
r2_score_error(y_true, y_pred)
0과 1사이 숫자로 크면 클수록 높은 적합도를 지닌다 -
랜덤포레스트
의사결정트리학습의 문제점을 극복하기 위해서 만든것
데이터세트에서 무작위로 중복을 허용하여서 가져온다 -
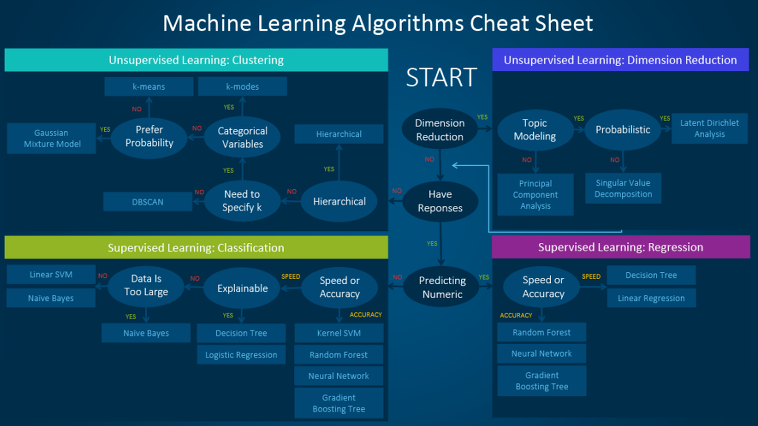
머신러닝 Cheat sheet(참고)
형태소분석기
soynlp
한국어 자연어 처리를 위한 라이브러리
https://github.com/lovit/soynlp
wordcloud
- 불용어처리에도 주의하자
자주등장하는 단어이지만 의미가 없어 불용어처리를 하게된다
word2vec(유명자료)
- cbow
- skip-gram
