**2020.01.06 Hadoop Class
Hadoop
-
분산파일시스템(HDFS) :
마스터 노드(name node)가 있으며, 그 아래로 슬레이브 노드(data node)를 두어서 저장을 하게된다.
마스터 노드에는 각각의 슬레이브 노드에 대한 정보를 가지고있으며, 새로운 데이터가 저장될경우 각각의 슬레이브 노드에 나누어서 데이터를 저장시키게된다. 리눅스를 기초 시스템으로 만들었으며, JAVA로 구성되어있다 -
맵리듀스 : 분석파일에 대해서 구성된 클러스터 환경에서 병렬 처리를 지원하기 위해서 개발되었다.
https://hadoop.apache.org/
하둡 공식 홈페이지
Window Hadoop 환경 설정
- 주의할점
경로와 로그인 아이디가 영문 / 빈문자가 없는것으로 설정해야한다.
Program Files와 같은것은 cmd 창에서 dir /x를 누른후 줄임이름(PROGRA~1)이 있는데 그것을 환경변수의 JAVAHOME에 Program Files 대신 넣어주면 가능하다
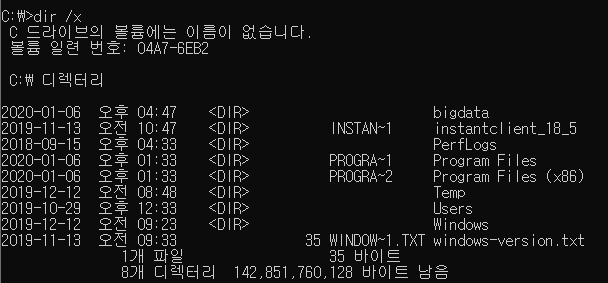
1. HADOOP_HOME을 환경변수에 설정
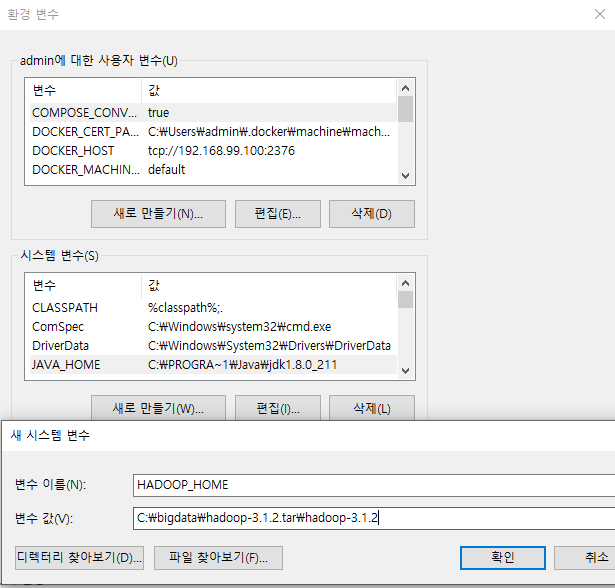
2. PATH를 변경
3. hadoop win파일을 hadoop파일의 bin에다가 덮어쓰기

4. hadoop 설정 경로

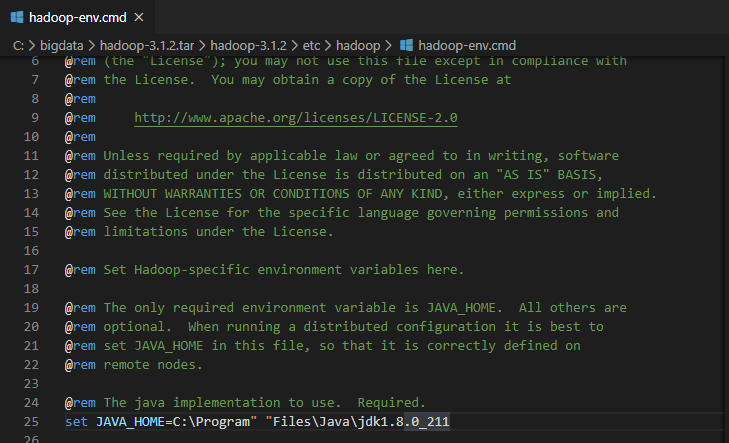
5. 위의 경로로가서 hadoop-env.cmd에 가서 JAVA_HOME을 java홈으로 잡아주되Program" "Files라고 지정해주어야 띄워쓰기를 인식한다
hadoop_indent_string = 환경변수가 인식이 잘안될경우가 있는데 이때에
하드코딩으로 직접 Username을 설정해주면된다
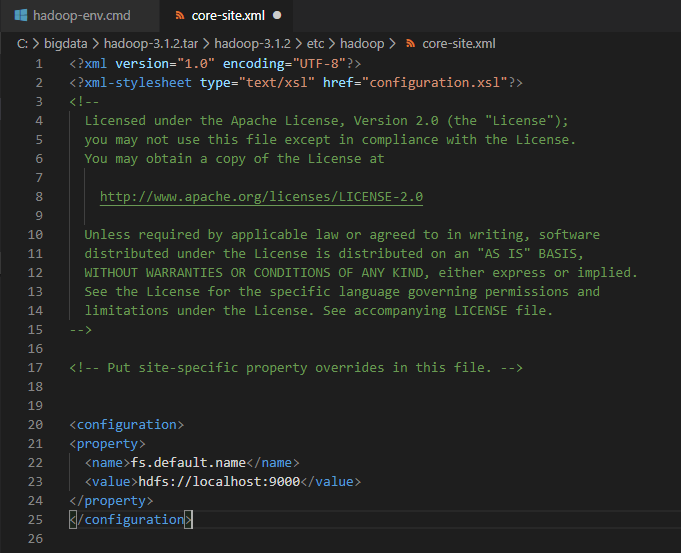
6. core-site.xml 파일을 설정한다
fs.default.name은 namenode(master)가 되는것이 어디냐라는것을 설정하게된다
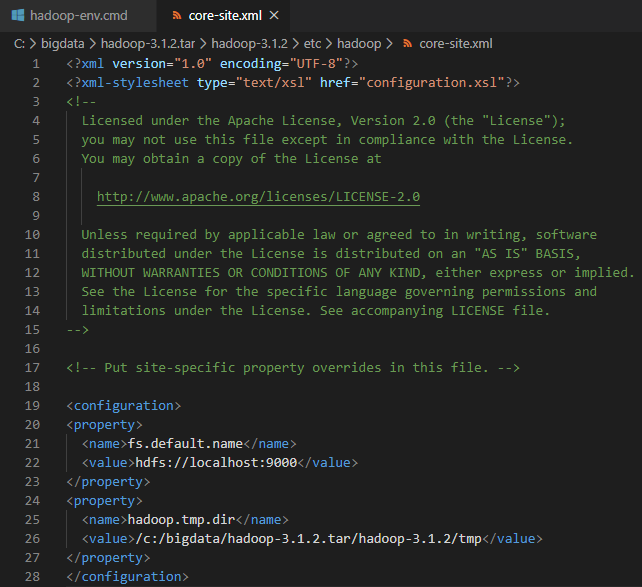
7. tmp라는 폴더를 하나 만들고 아래처럼 추가해주고, tmp의 폴더 경로를 지정C는 대문자가 아니라 소문자로 해준다
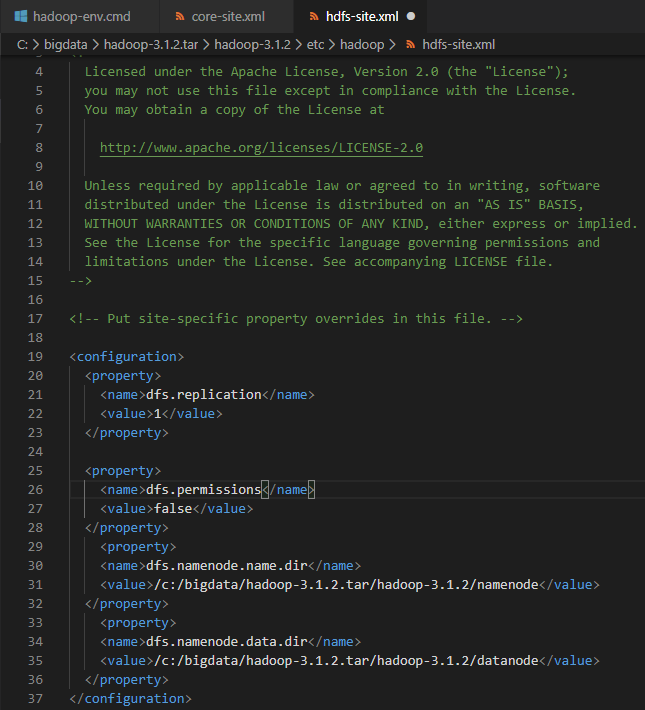
8. hdfs-site.xml 파일을 열어서 아래와 같이 입력해준다. namenode와 datanode는경로에다가 폴더를 만들어준다
dfs.replication은 여러개의 옵션인데 분산 파일 저장을 위해서 같은 내용을
copy해놓아야한다 그것을 몇개나 복제시킬것이냐 라는것을 나타낸다
또한 namenode와 datanode는 특정 폴더안에다가 생성되게끔 만들어놓는다
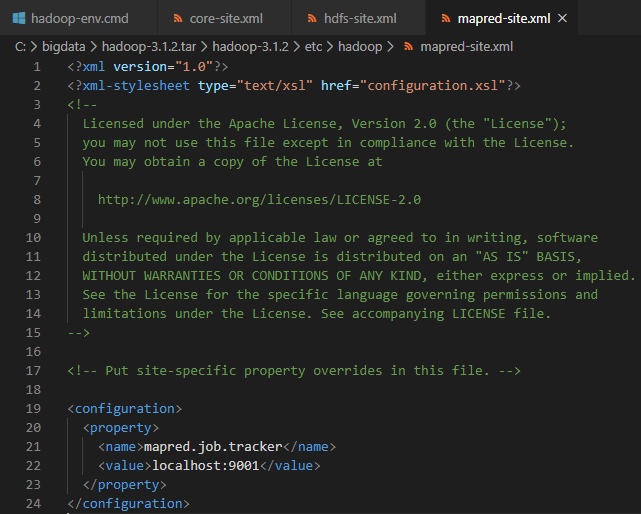
9. mapred-site.xml에 아래와 같이 설정
mapreduce를 처리해주는 masternode가 누구인지 설정하기
10.workers에 있는곳에 자신의 datanode의 주소들을 적어주면 된다.
datanode를 등록시키기(컴퓨터를 여러개를 사용할경우)
Window에서는 ssh를 사용하게된다

Hadoop 실행
- hadoop namenode -format
namenode를 초기화 시켜준다(주의 할것!)

Let's do it developer