RestoreFormer: High-Quality Blind Face Restoration from Undegraded Key-Value Pairs 논문으로 transformer를 통하여 구현한 Reference Face Super Resolution이다. DFDNet과 같은 Dictionary를 사용하는 Super Resolution 방법이지만, 여러 방법을 이용하여 그 성능과 자연스러움을 높이는 데에 성공하였다. 깃허브
3줄 요약
- 기존의 방법과는 다르게 multi-head cross-attention 레이어를 이용해서 원본 이미지의 정보와 그 이미지의 특징 정보를 동시에 훈련할 수 있다.
- 이미지의 특징 정보는 Vector Quantization으로 미리 만들어진 고화질의 얼굴 사전에서 찾아 모델에 투입한다.
- 1개의 인공 데이터셋과 3개의 실제 데이터셋에서 기존의 SOTA 방법을 뛰어넘었으며, 더 좋은 이미지 퀄리티를 보여준다.
Proposed Methods
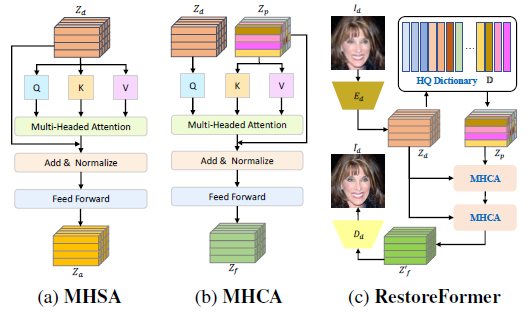
RestoreFormer는 알 수 없는 방법으로 저화질이 된 사진을 고화질로 복원하는 것을 목적으로 하며, 고품질의 이미지를 이용하여 제작된 사전을 이용한다. 첫 번째 인코더인 로 저화질의 사진 에서 특징 와 사전 에서 와 가장 비슷한 특징인 를 뽑아낸다. 그리고 multi-head cross-attention(이하 MHCA)를 이용한 두 개의 트랜스포머를 이용해 저화질 이미지와 인코더에서 나온 특징을 혼합한다. 트랜스포머를 이용해 나온 최종 를 디코더 에 적용해 고화질 사진 를 복원한다.
고화질 이미지 사전 를 만들기 위하여 vector quantization을 사용한다. VGG에서 얼굴 부분 특성을 때어낸 기존 연구와 다르게, 는 reconstruction-oriented이며 더 뛰어난 디테일을 복원에 사용할 수 있다.
RestoreFormer
기존의 사전 기반의 Reference FSR은 얼굴의 일부분만을 때어 복원한다는 한계점이 있었다. 최근의 ViT(Vision Transformer)에서는 사진의 맥락적인 정보를 파악할 수 있다. 하지만 대부분의 ViT 기반 방식은 한 가지의 정보만을 인풋으로 받아들일 수 있었다. 이를 해결하기 위하여 RestoreFormer는 MHCA를 사용한다. MHCA를 이용하면 기존의 Multi-head self-attention(이하 MHSA) 기법과 달리 이미지 정보와 얼굴 특징 정보를 혼합하여 훈련에 사용할 수 있다.
MHSA
기존의 ViT 계열 모델에서는 주로 MHSA를 사용하였다. MHSA는 저화질 이미지에서 전체적인 정보들을 모두 학습에 이용할 수 있었다. 이 경우 query, key, values는 아래와 같이 정의된다.
이 때 와 는 학습 가능한 파라미터이다.
가 개의 채널 차원으로 분리될 수 있다고 하면 각 블록은 개의 채널을 가진다. 그러면 해당 attention map은 아래와 같다.
그래서 multi-head attetion의 최종 아웃풋은 를 합친것이다.
는 residual로 여겨지며 normalization 레이어와 feed forward 네트워크 전에 다음과 같이 더해준다.
이제 는 전체로 feature map을 얻을 수 있다.
MHCA
MHSA와 다르게 MHCA는 저화질 사진과 개인 식별 정보와 고화질 사전으로부터의 고품질의 얼굴 정보를 결합하는 것을 목표로 한다. 그러므로 MHCA는 를 저화질 사진에서 쿼리 로 뽑고, 키 와 value 를 고화질 사전 에서 가져온다. 즉, MHCA의 query, key, values는 아래와 같다.
그 이후의 과정은 MHSA와 유사하며, 최종 결과는 다음과 같다.
RestoreFormer
RestoreFormer의 구조는 위 사진을 참고하면 좋다. 먼저, 저화질 이미지 를 인코더 에 투입한다. 이 때 인코더는 12개의 residual 블록과 5개의 average pooling 레이어로 이루어져 있으며, 를 결과로 내놓는다. 그 후 고화질 사전 에서 가장 비슷한 특징인 를 가져온다. 자세한 사항은 아래서 설명한다. 이제 아래와 같이 와 를 두 개의 MHCA들에 각각 넣어서 를 얻어낸다.
마지막으로 디코더 에 를 넣어서 고품질 이미지 를 얻는다. 이 때 디코더는 12개의 residual 블록과 5개의 nearest neighbor upsampling을 사용한다.
학습 방법
RestoreFormer 학습을 위하여 픽셀 단계, 구성요소 단계, 이미지 레벨의 loss 함수들이 필요하다.
픽셀 단계 loss
SR에서 주로 사용되는 다음과 같은 L1 loss와 perceptual loss를 사용한다.
는 VGG-19에서 각 layer마다의 feature map을 의미한다.
또한, 사전에서 비슷한 feature를 고르기 위하여 기존과 사전에서 선택한 것과의 차이 역시 loss로 사용하며 다음과 같다.
구성요소 단계 loss
눈과 입이 얼굴에서 중요한 역할을 하기 때문에, 이러한 구성요소들을 비교하는 loss를 사용하였다. 눈과 입이 저화질과 SR 결과 이미지에서 얼마나 비슷한지 보기 위하여 discrimination loss와 style loss를 사용하며 다음과 같다.
은 오른쪽 눈, 왼쪽 눈, 입을 의미한다. 또, 은 ROI align이며 는 discriminator의 multi-resolution feature이다. Gram은 style 차이를 계산하는 Gram matrix의 correlation이다.
이미지 단계 loss
이 단계의 loss는 더 진짜같고 정확한 이미지를 얻기 위한 것이다. 실제처럼 보이게 하기 위하여 이미지 전체의 adversarial loss를 적용했고, 정확한 이미지를 얻기 위해서 identity loss를 적용했다. 수식은 다음과 같다.
여기서 는 얼굴 이미지로 훈련한 discriminator이고, 는 ArcFace 얼굴 인식 모델을 사용해서 훈련한 feature이다. 즉, 각 얼굴이 얼마나 다른 사람인지를 알 수 있다.
이리하여 최종적으로 RestoreFormer를 훈련할 때 사용하는 loss는 아래와 같으며, 는 각 loss들의 가중치이다.
고품질 사전
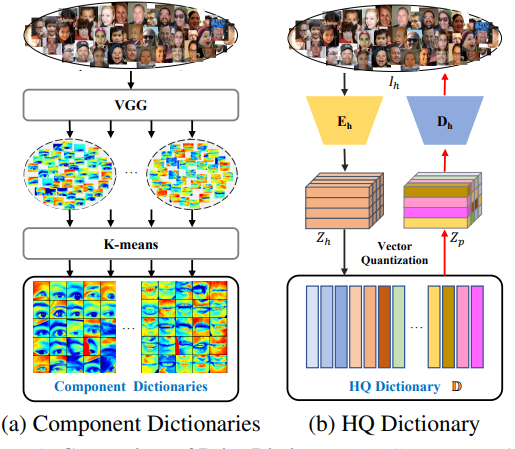
DFDNet과 같은 기존 연구에서는 VGG에서 나온 feature를 통해서 사전을 형성했으며, 눈, 코, 입등의 부분을 때어 내어 사전에 저장하였다. 이는 얼굴 전체의 정보를 포함하지 못해 디테일한 부분이 떨어지기 때문에, 본 연구의 사전에서는 이를 해결하고자 vector quantization을 도입한다.
먼저, 고품질의 샘플 사진 에서 feature 를 추출하는 인코더 가 있다. 이후, 를 곧바로 디코더 에 투입하지 않고 양자화하여 를 얻어낸다. feature 양자화(quantization) 과정은 다음과 같다.
는 feature 벡터의 위치를 의미한다. 를 인풋으로 디코더 는 고품질 얼굴 사진 를 복원할 수 있다. 인코더 와 디코더 는 RestoreFormer에서 사용한 인코더 , 디코더 와 동일하다.
학습 방법
사전 의 각 요소 은 uniform한 확률 분포에서 랜덤으로 선택된다. 거기서 높은 품질의 얼굴 정보를 찾아내기 위하여 dictionary 학습 알고리즘인 Vector Quantization(이하 VQ)를 적용했다. 를 로 VQ를 수행하는 과정은 다음과 같다.
여기서 는 stop graident를 의미한다.
인코더 를 사전 와 같은 학습 공간에 유지하기 위하여 아래와 같은 commitment loss도 사용한다.
위의 두 loss를 사용하면 를 고퀄리티의 이미지에서 추출한 와 가깝게 위치하게 하여 가 높은 얼굴 디테일을 포함할 수 있게 한다.
최종적인 이미지 복구를 위하여, L1 loss, perceptual loss, adversarial loss 역시 사용된다.
가 가중치일때 최종 loss는 다음과 같다.
Experiments
데이터셋
훈련용 데이터셋
사전을 훈련하기 위하여 FFHQ 데이터셋의 70000장 사진을 모두 512x512 크기로 resize하여 훈련하였다. 또한 저품질의 사진을 만들기 위해 FFHQ를 저화질로 변경했다. 구체적으로, 높은 퀄리티의 사진에 Gaussian blur를 적용하고 bilinear 방식으로 다운샘플했다. 그후 Gaussian 노이즈를 추가하고 JPEG 포맷으로 압축했다. 이후 원하는 저화질 크기로 재조정했다.
테스트용 데이터셋
테스트용으로 인공 생성 데이터셋 CelebA-Test와 real-world 데이터셋인 LFW-Test, CelebChild-Test, WebPhoto-Test 를 사용했다.
실험 결과
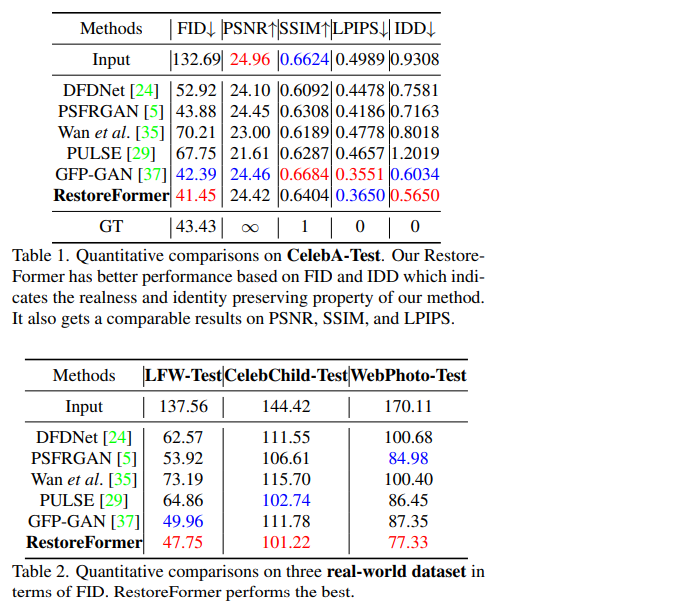
인공적인 데이터셋을 통해 실험한 결과, 실제 얼굴과 얼마나 비슷한가를 측정하는 FID와 저화질 이미지와 얼마나 동일한 사람처럼 보이는가를 측정하는 IDD에서 가장 좋은 성능을 보였다. 대표적인 FSR 지표인 PSNR, SSIM, LPIPS에서도 나쁘지 않은 지표를 보여주었다.
real-world 데이터셋에서는 실제 얼굴과 얼마나 비슷한가를 측정하는 FID 지표에서 굉장히 높은 성능을 보였다. 위의 표에서도 볼 수 있듯이 세 개의 모든 데이터셋에서 다른 모든 모델보다 낮은 FID 점수(낮을수록 정확함)를 보였다. 이렇게 실제로 더 좋아 보인다는 것을 증명하기 위해, 연구진은 100명의 실험자에게 200개의 샘플 중에 더 시각적으로 훌륭해 보이는 것을 고르라는 실험을 진행했으며 기존 모델에 비해 최소 2.5배에서 많게는 9배까지의 높은 확률로 선택을 받았다.

