
안녕하세요.
저는 비브스튜디오스 연구소 서비스개발팀 정인호 연구원입니다.
오늘은 Unity Japan, Keijiro님의 작업을 보고 감명받아 진행한 토이 프로젝트를 소개해드리려 합니다.
이 프로젝트는 실시간으로 손을 탐지해 파티클 이펙트를 적용하는 것으로 기존 딥러닝 모델의 추론이 GPU에서 진행되기 때문에 매 프레임 CPU, GPU를 두 번씩 오고 가야하는 문제의 최적화에 대해 알아보았습니다.
Barracuda Package
| Baraccuda | Onnx Model |
|---|---|
 |  |
Baracuda 패키지는 유니티에서 딥러닝 모델을 사용할 수 있게 해주는 라이브러리입니다.
Baracuda는 모델의 런타임 엔진을 비롯해 텐서 클래스 등 프로그래머에게 여러 가지 편의를 제공해줍니다.
가장 큰 장점으로는 역시 유니티답게 크로스 플랫폼을 지원한다는 것 입니다.
Onnx 모델을 import하면 유니티 내부 프레임워크인 NN model로 변환이 되고, 플랫폼에 상관없이 GPU 가속을 받을 수 있습니다. (물론 CPU 추론도 가능합니다)
하지만 모델 추론에 필요한 전처리, 후처리 과정까지 지원하지는 않습니다. 만약 전처리/후처리 과정에서 GPU 가속을 받고 싶다면, Compute Shader를 이용해 직접 코드를 작성해야 합니다.
Mediapipe Hands
| Mediapipe Hands | Result |
|---|---|
 |  |
Google Mediapipe에서 제공해주는 Hands 모델은 손을 탐지해 21개의 키포인트를 찾아줍니다.
모델 크기에 따라 light/full 버전이 존재하고, 다른 모델들에 비해 매우 가볍고 빠른 것이 특징입니다.
해당 모델의 output에 바로 파티클 이펙트를 적용하면 손바닥 가운데가 뻥 뚫려있어 약간 어색한 결과가 나오는 것을 확인하여 손바닥 가운데에 키포인트를 추가했고, 아래와 같이 조금 더 자연스러운 결과를 얻었습니다.
| Mediapipe Hands | Result |
|---|---|
 |  |
Problem
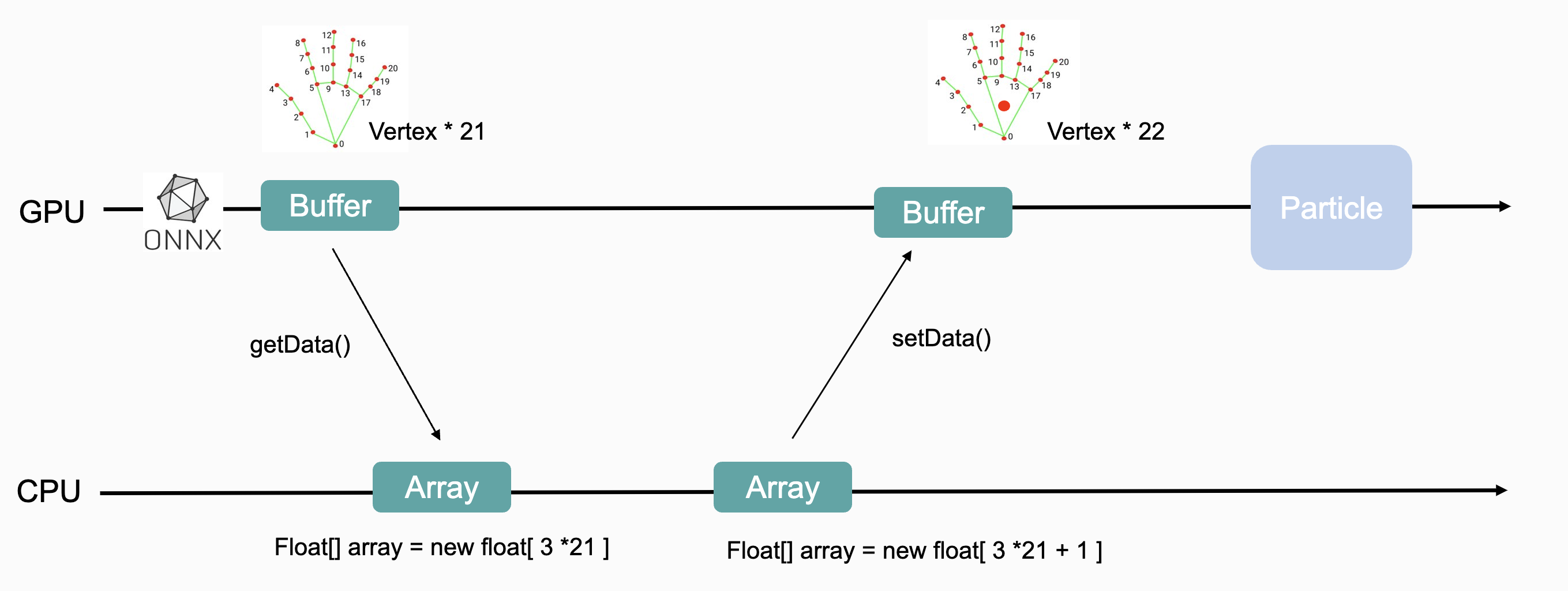
여기서 한 가지 불편한 상황이 발생합니다.
모델 output에 키포인트 하나만 추가하고 싶을 뿐인데 연산이 아주 비싼 getData(), setData() 메서드를 이용해 GPU와 CPU 사이를 오가야 합니다. 간단해 보이지만 생각보다 많은 과정이 필요합니다.
- CPU에 Buffer 사이즈와 동일한 Array를 생성
- ComputeBuffer.GetData() 메서드를 이용해 데이터를 CPU로 가져오기
- 사이즈가 1 큰 새로운 Array 생성 (position 하나의 사이즈)
- 기존 Array의 데이터를 복사하고 새로운 키포인트 추가
- 기존 Buffer보다 사이즈가 1 큰 새로운 Compute Buffer 생성
- ComputeBuffer.SetData() 메서드를 이용해 데이터를 GPU로 보내주기

이때 필요한 메서드가 바로 ComputeBuffer.BeginWrite/EndWrite 메서드 입니다.
해당 메서드의 경우 ComputeBuffer를 생성할 때 SubUpdates모드로 생성해주어야 사용할 수 있고, ComputeBuffer.SetData()방식보다 훨씬 적은 메모리 카피를 통해 데이터를 받아올 수 있습니다. 유니티 공식 문서를 찾아보면 그 이유를 대략적으로나마 알 수 있습니다.

ComputeBuffer의 SubUpdates모드는 버퍼를 GPU가 아닌 GPU-visible CPU 메모리에 저장한다고 합니다. 따라서 CPU에서 버퍼를 자주 수정해야 하는 상황에 적합한 모드입니다. 저의 경우가 딱 이렇습니다.
| Default Mode | SubUpdates Mode |
|---|---|
 |  |
코드를 바꿔 테스트해본 결과 초당 약 10프레임 정도의 성능 향상이 있었습니다. 사실 버퍼의 사이즈가 원체 작아서 최적화가 필수적인 상황은 아니었습니다. 모델과 후처리가 무거워질 경우를 대비해 공부를 해보았는데, 다행히 조금이나마 성능 향상이 되었습니다.
마지막으로 최종 결과를 보여드리고 이번 포스팅을 마치겠습니다.

감사합니다.
Reference
