📍 해당 글은 Udemy의 Certified Kubernetes Administrator (CKA) with Practice Tests 강의를 듣고 정리했습니다.
49. Scheduling Section Introduction
- Manual Scehduling
- Daemon Sets
- Multiple Schedulers
- Scheduler Events
- Configure k8s Scheduler
51. Manual Scheduling
스케줄링 동작 과정
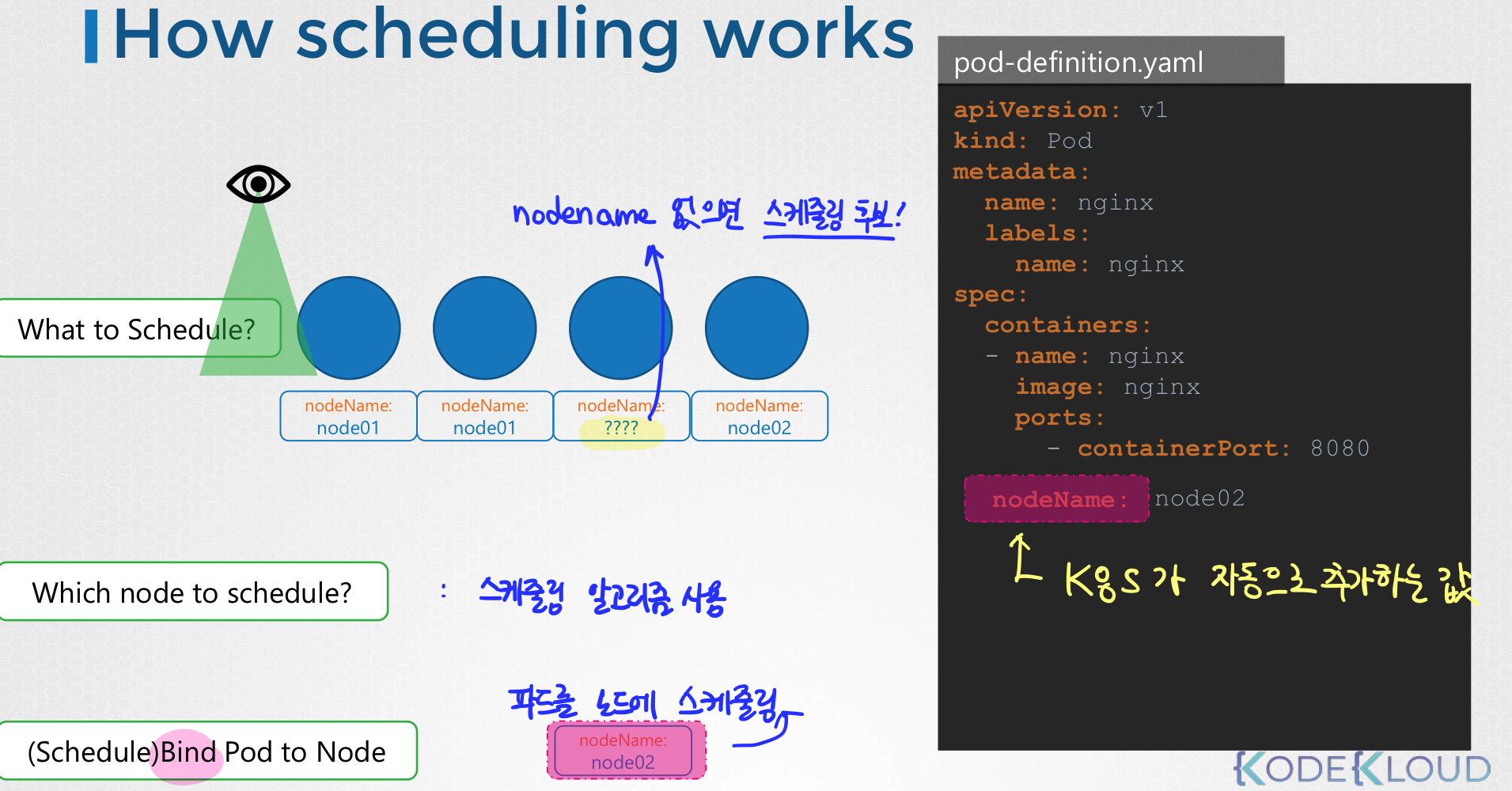
모든 poddpsms Node Name이라는 필드가 존재한다.
default로는 값이 들어가있지 않다. 이 필드는 k8s가 자동으로 추가하는 필드이다.
스케줄러는 모든 파드를 검사한 뒤 nodeName 속성이 설정되지 않는 파드를 찾는다. 이 파드들은 스케줄링 후보가 된다.
그 다음에는 스케줄링 알고리즘을 활용하여 파드에 적합한 노드를 고른다.
노드를 골랐으면 그 노드에 파드를 스케줄링한다. 이때 바인딩 오브젝트를 생성하면서 파드의 nodeName에 그 노드의 이름이 들어가게 된다.
If No Scheduler
모니터링, 스케줄링 역할을 수행할 스케줄러가 없다면, 파드는 계속 보류중(Pending)상태로 남는다.
이를 해결하려면 수동으로 파드를 노드에 할당해야한다.

스케줄러없이 파드를 스케줄링하는 방법
pod definition file에서 nodeName에 노드 이름을 지정하면 파드가 지정된 노드에 할당된다.
nodeName을 지정하는 것은 pod를 만들 때만 가능하다.
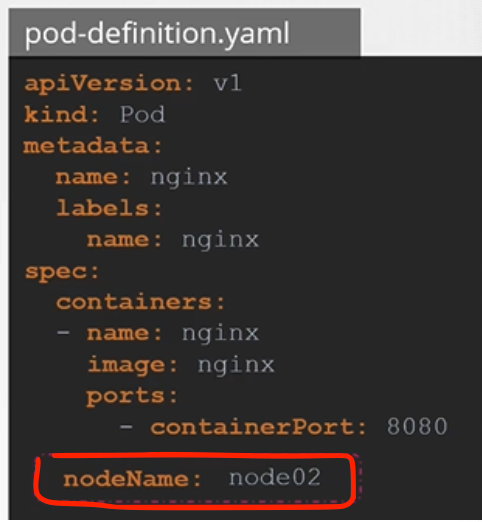
그럼, 이미 pod가 생성된 경우에 pod를 노드에 할당하고 싶다면 어떻게 해야할까? 주의할 것은 k8s는 pod의 nodeName 속성을 수정하지 못하게 했다는 것이다.
이럴 때에는 **Binding 오브젝트를 만들고, pod의 binding API에 POST 요청을 보내면 된다.** 이 방식은 실제로 스케줄러가 수행하는 작업으로, 아래와 같이 Binding Objec 오브젝트를 만든다.
- Binding 오브젝트 생성
apiVersion: v1
kind: Binding
meatadata:
name: nginx
target: # Binding 오브젝트는 target 하위 name에 노드 이름을 지정한다.
apiVersion: v1
kind: Node
name: node02- POST 요청 보내기
curl --header "Content-Type: application/json" --request POST --data '{apiVersion: v1, "kind": "Binding", ...}' http://$SERVER/api/v1/namespaces/default/pods/$PODNAME/binding/단, 요청을 보낼 때에는 YAML 내용을 JSON으로 변환한 데이터를 사용해야 한다.
53. Solultion - Manual Scheduling
Q. pod 생성 후 pending status인 이유
A. k describe po nginx명령을 실행하면 Node: 을 확인할 수 있다. 그리고 k get po -n kube-system 을 확인하면 스케줄러가 없는 것을 알 수 있다.
- 파드를 생성하고 다시 만들 때는
k replace --force명령을 이용할 수 있다.k replace --force -f nginx.yaml pod "nginx" deleted pod/nginx replaced
54. Labels and Selectors
Labels와 Selector는 그룹화 방법이다.
Labels는 어떤 기준에 따라 오브젝트를 그룹화하고 필터링하는 기능을 수행할 수 있는 오브젝트이다.
Labels 는 각 항목에 첨부된 속성이다.
selector는 속성들을 필터링한다.
Labels와 Selector는 왜 사용하는가?
k8s의 사용 시간이 늘어남에 따라 클러스터에는 오브젝트가 수백 개, 수천 개가 생성될 것이다. 이들을 관리하기 위해 유형별로 오브젝트를 그룹화하거나 기능별로 오브젝트를 분류하는 것 같이 다양한 범주별 객체 필터링 방법이 필요하다. 이를 위해 labels를 붙여 그룹화하고 selector로 특정 오브젝트를 필터링 할 수 있다.
ex. Front-End, Back-End / Web-Servcers, App-Servers / DB, Cache / Auth, Audit / Image-Processing, Video-Processing
Labels 생성

Labels Select 하기
파드 생성 후 label이 있는 pod를 선택하려면 selector 옵션과 함께 k get po 명령을 사용하고 app=App1과 같은 조건을 지정합니다.
k get po --selector app=App1ReplicaSet
ReplicaSet의 자체의 label과 pod의 label을 혼동하지 않도록 주의하자.
상단에 정의된 레이블은 ReplicaSet 그 자체의 레이블이고,
template 섹션 아래에 정의된 레이블은 pod의 레이블이다.
ReplicaSet을 파드에 연결하기 위해 파드에 정의된 레이블과 일치하도록 spec 아래의 selector 필드를 구성한다.
apiVersion: apps/v1
kind: ReplicaSet
metadata:
name: webapp
labels:
app: App1
function: Front-End
spec:
replicas: 3
selector:
matchlabels:
app: App1
template:
metadata:
labels:
app: App1
function: Front-End
spec:
containers:
- name: webapp
image: webappService
service 및 다른 오브젝트에 대해서도 동일하게 작동한다.
서비스가 생성되면 서비스 definition 파일에 정의된 selector를 사용하여 ReplicaSet Definition 파일의 파드에 설정된 레이블과 일치시킵니다.
apiVersion: v1
kind: Service
metadata:
name: my-services
spec:
selector: # pod에 라벨과 일치시킨다.
app: App1
ports:
- protocol: TCP
port: 80
targetPort: 9376Annotations 주석
label과 selector는 오브젝틀르 그룹화하고 선택(필터링)하는데 사용되는 반면, 주석은 정보 제공 목적으로 기타 세부 정보르 기록하는데 사용된다.
이름, 버전, 빌드 정보 등과 같은 세부 정보 또는 interface purpose(연락처 세부 정보, 전화 번호, 이메일 ID 등)를 기록할 수 있습니다.
apiVersion: apps/v1
kind: ReplicaSet
metadata:
name: webapp
labels:
app: App1
function: Front-End
annotations:
buildVersion: 1.34
spec:
...55. Practice Test - Labels and Selectors
- 라벨 필터링 후 파드 갯수 세기 kubectl get pods --selector env=dev --no-headers | wc -l
- 라벨 여러 개로 필터링하기 → ,(콤마) 이용하기 k get po --selector env=prod,bu=finance,tier=frontend
56. Solultion - Labels and Selectors
## env=dev label 붙은 pod 찾기
k get po --selector env=dev
## env=dev label 붙은 pod 갯수 세기
k get po --selector env=dev --no-headers | wc -l57. Taint and Tolerations
- Pod와 Node의 관계
- Pod를 배치할 Node에 대한 제한 방법
Taint와 Toleration은 노드에 어떤 포드를 스케줄링할 수 있는지 제한을 설정할 수 있다.
taint와 toleration이 존재하는 스케줄링
3개의 워커 노드, 4개의 파드가 존재하는 상황을 가정한다.
노드의 이름은 1, 2, 3이고 파드의 이름은 A, B, C, D이다.
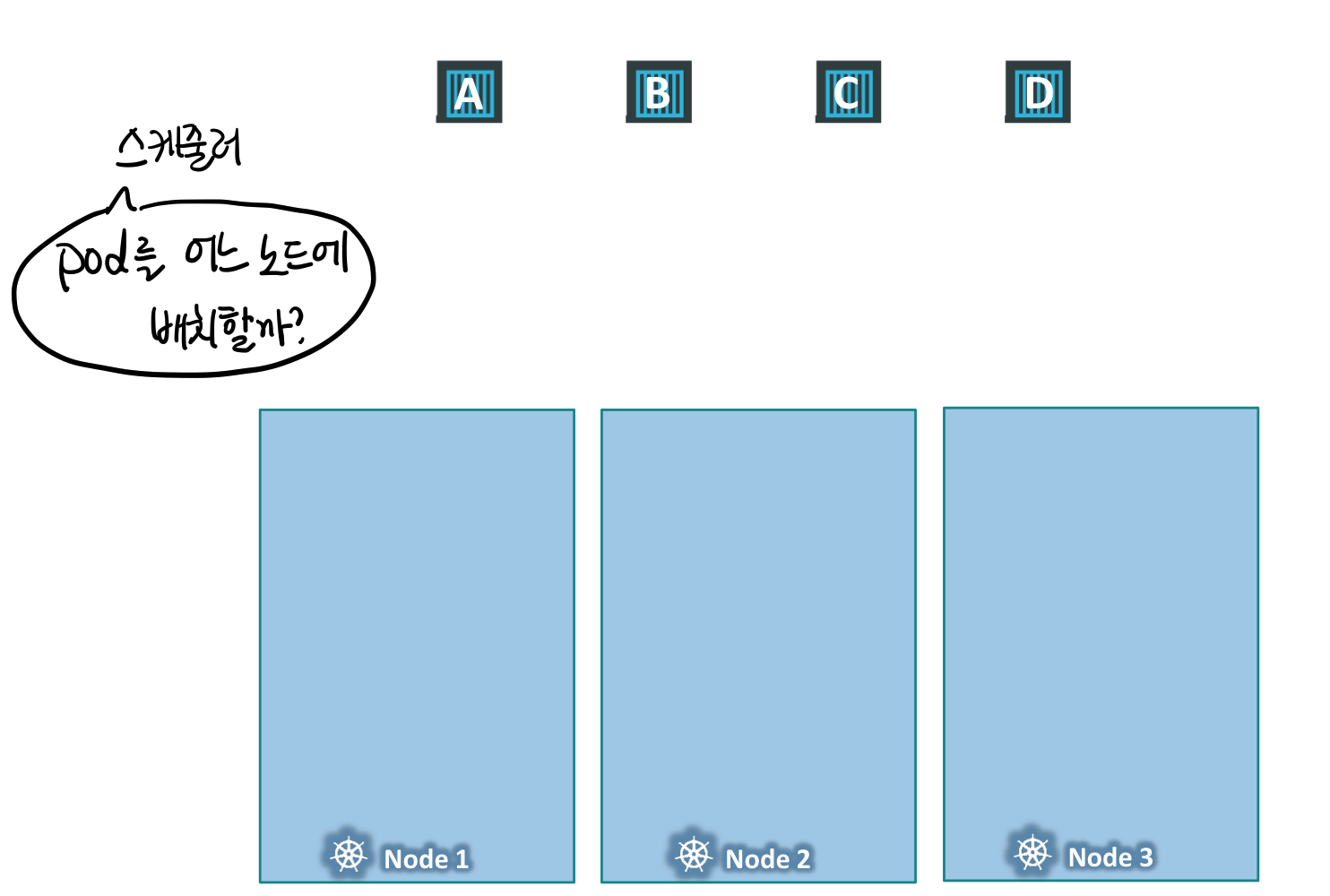
스케줄러는 파드를 사용 가능한 워커 노드에 배치하려고 시도한다. 이때 모든 노드에 균등하게 균형을 맞추어 파드를 배치한다.
이때 노드 1에는 특정 애플리케이션을 위한 전용 리소스가 있어서 그 애플리케이션에 해당하는 Pod만 배치하고자한다.
요구사항을 정리하면 아래와 같다.
- 노드1에 원하지 않는 파드는 배치되지 않는다. (=
taint) - 노드1에는 특정한 파드만 배치된다. (=
toleration)
요구사항을 만족하기 위해서는 아래 단계를 실행한다.
첫째. 노드1에 taint를 배치하여 모든 노드가 그 노드에 배치되는 것을 방지한다. Pod는 기본 값으로 toleration을 가지고있지 않다. 명시해주지 않는 이상 어떠한 pod도 taint가 있는 곳에 배치될 수 없다. (1번 요구사항 충족)
둘째. 배치를 원하는 Pod D에 toleration을 추가한다. 그러면 Pod D는 blue taint를 견딜 수 있게된다.(=배치할 수 있게 된다.) (2번 요구사항 충족)
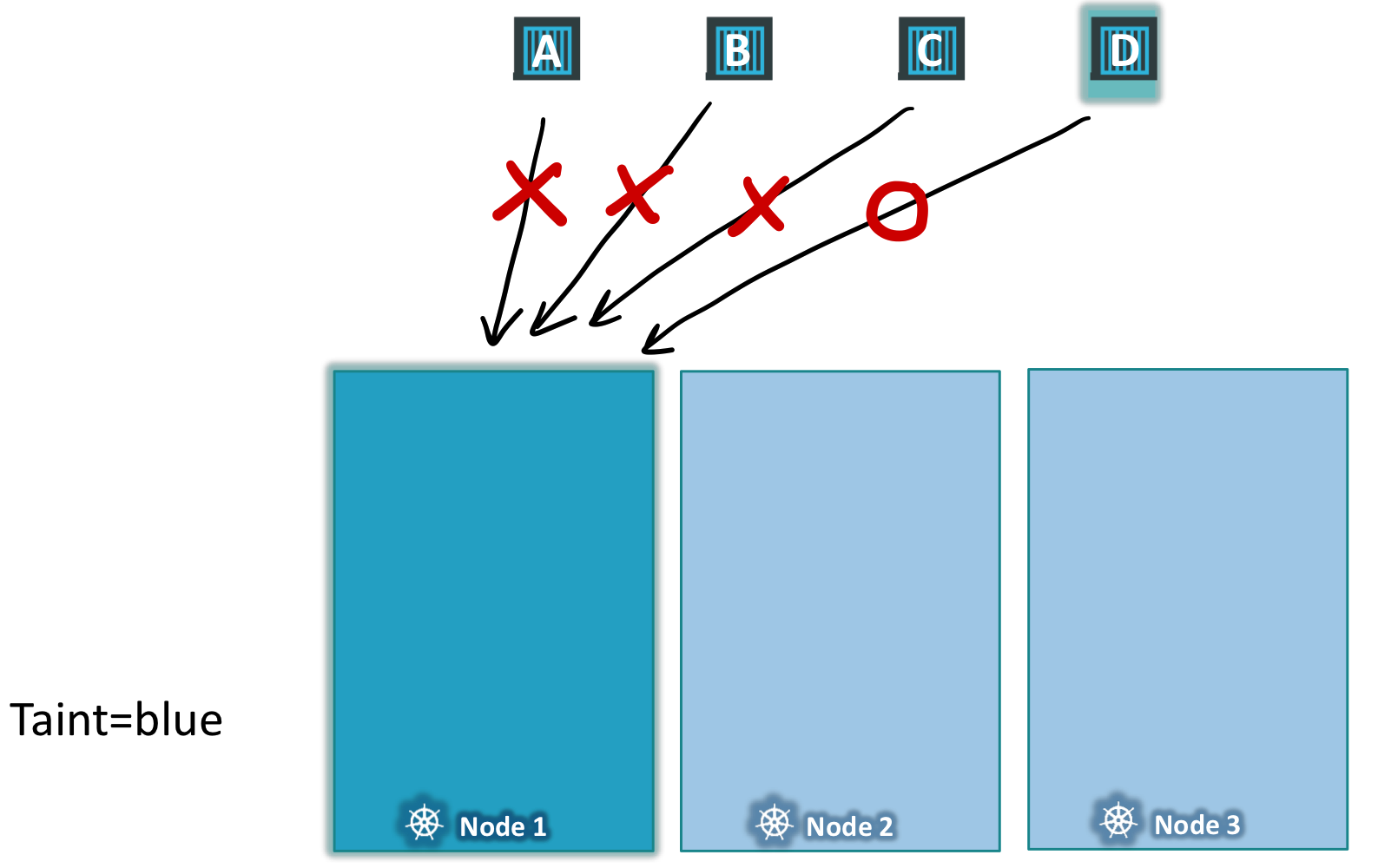
💡 taint는 Node에 설정되고,
toleration은 Pod에 설정된다.
Taint & Toleration 생성하기
-
Taint ( Node )
k taint nodes <node명> key=value:taint-effect- taint-effect
- NoSchedule | PreferNoSchedule | NoExecute
- 만약 pod가 toleration이 없으면 어떻게 처리할지에 대한 옵션
- taint-effect
-
Toleration ( Pod )
Pod definition file의
spec섹션에tolerations섹션을 추가한다.- taint를 생성했을 때 사용한 값과 동일하게 입력한다.
toleration섹션의 모든 값은 쌍따옴표로 감싸야 한다.
# taint
k taint nodes node1 app=myapp:NoSchedule
# toleration
vi pod-definition.yaml
spec:
containers:
tolerations:
- key: "app"
operator: "Equal"
value: "blue"
effect: "NoSchedule"💡 taint와 toleration은 pod를 특정 노드로 배치하는 것을 말하는 것이 아니다 !
노드가 특정 toleration을 가지고 있는 pod만 허용하는 것이다.
만약, 특정 노드에 특정 pod가 배치되는 것을 제한하고 싶다면 node affinity를 이용할 수 있다.
master node와 taint
지금까지 우리는 pod를 worker node에만 배치했다.
master node는 pod를 호스팅하고 모든 관리 소프트웨어를 실행할 수 있지만, pod를 직접 스케줄링(배치)하진 않는다.
클러스터가 처음 설정되면 master node에 taint가 자동으로 설정되어 pod가 master node에 스케줄링되지 않도록 막았기 때문이다.
아래 명령어를 통해 master node에 적용된 taint를 확인할 수 있다.

58. Practice Test - Taint and Tolerations
59. Solultion - Taint and Tolerations
## 02. node에 taint가 존재하니?
k describe no node01 | grep -i taint
Taints: <none>
## 10. taint 삭제
k describe node controlplane | grep -i taint
Taints: node-role.kubernetes.io/control-plane:NoSchedule
k taint node controlplane node-role.kubernetes.io/control-plane:NoSchedule-
node/controlplane untainted60. Node Selectors
Node Selector는 특정 노드에 특정 pod를 배포시킬 수 있는 간단한 방법이다.
Node Selector 생성
data-processor pod가 노드 중 큰 노드에서 실행되도록 제한하기 위해 NodeSelector를 생성하고자 한다.
먼저, spec 섹션에 nodeSelector 속성을 추가한다.
이때, size: Large 는 노드의 label이다. 스케줄러는 이 레이블을 사용하여 파드를 배치할 올바른 노드를 식별한다.
단, 이처럼 nodeSelector에서 레이블을 사용하려면 Pod를 만들기 전에 먼저 노드에 레이블을 지정해야 한다.
apiVersion: v1
kind: Pod
metadata:
name: myapp-pod
spec:
nodeSelector: # spec 섹션에 추가
size: Large # 노드의 label
containers:
- name: data-processor
image: data-processor
Label Nodes 노드에 레이블 지정하기
nodeSelector에서 pod를 배치할 노드를 선택하려면, 먼저 노드에 레이블을 선택해야한다. 노드에 레이블을 지정하려면 다음 명령을 이용하면된다.
k label nodes <node명> <label-key>=<label-value>
ex. kubectl label nodes node-1 size=Large
node-1 노드에 label을 생성해라. key=size, value=Large
Node Selector의 한계 → Node Affinity
위의 예제는 Pod를 size=Large 레이블을 가진 노드에 배치하는 제약사항만이 존재했다.
하지만 여기서 제약사항이 더 많아지거나 복잡해지면 NodeSelector로는 해결할 수 없다.
- Node Selector가 해결할 수 없는
- size=Large 또는 size=Medium 노드에 배치
- size ≠ small인 노드에 배치
이를 해결하기 위해서 Node Affinity를 이용할 수 있다.
Node Affinity는 advance expression을 제공한다.
61. Node Affinity
Node Affinity의 주요 목적은 Pod가 특정 노드에 배치될 수 있도록 하는 것이다.
Node Affinity는 advance expression을 제공하기 때문에, Node Selector와 다르게 복잡한 요구사항을 해결할 수 있습니다.
Node Affinity로 Large 이거나 Medium인 노드에 배치하기
apiVersion: v1
kind: Pod
metadata:
name: myapp-pod
spec:
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressoions:
- key: size
operator: In
values:
- Large
- Medium
containers:
- name:
image:
spec 섹션 아래에 affinity, 그 아래에 nodeAffinity가 있다. 또 requiredDuringSchedulingIgnoredDuringExecution 필드도 존재한다. 이 아래에 nodeSelectorTerms가 있다. 여기에 key-value 쌍을 지정한다.
위 key-value 는 size가 Large 이거나 Medium인 노드에 파치를 배치하라는 의미이다.
Node Affinity로 Small이 아닌 노드에 배치하기
- 노드의 레이블을 Small로 설정했을 때
spec:
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressoions:
- key: size
operator: NotIn
values:
- Small- 노드의 레이블을 Small로 설정하지 않고 나머지 노드는 레이블을 갖고 있을 때
spec:
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressoions:
- key: size
operator: ExistsNode Affinity Type
만약, 일치하는 label이 붙은 노드가 없거나, 파드가 이미 배치되었는데 누군가 노드의 레이블을 변경하면 어떻게 될까?
이런 것들은 Node Affinity Type 에 따라 달라진다.
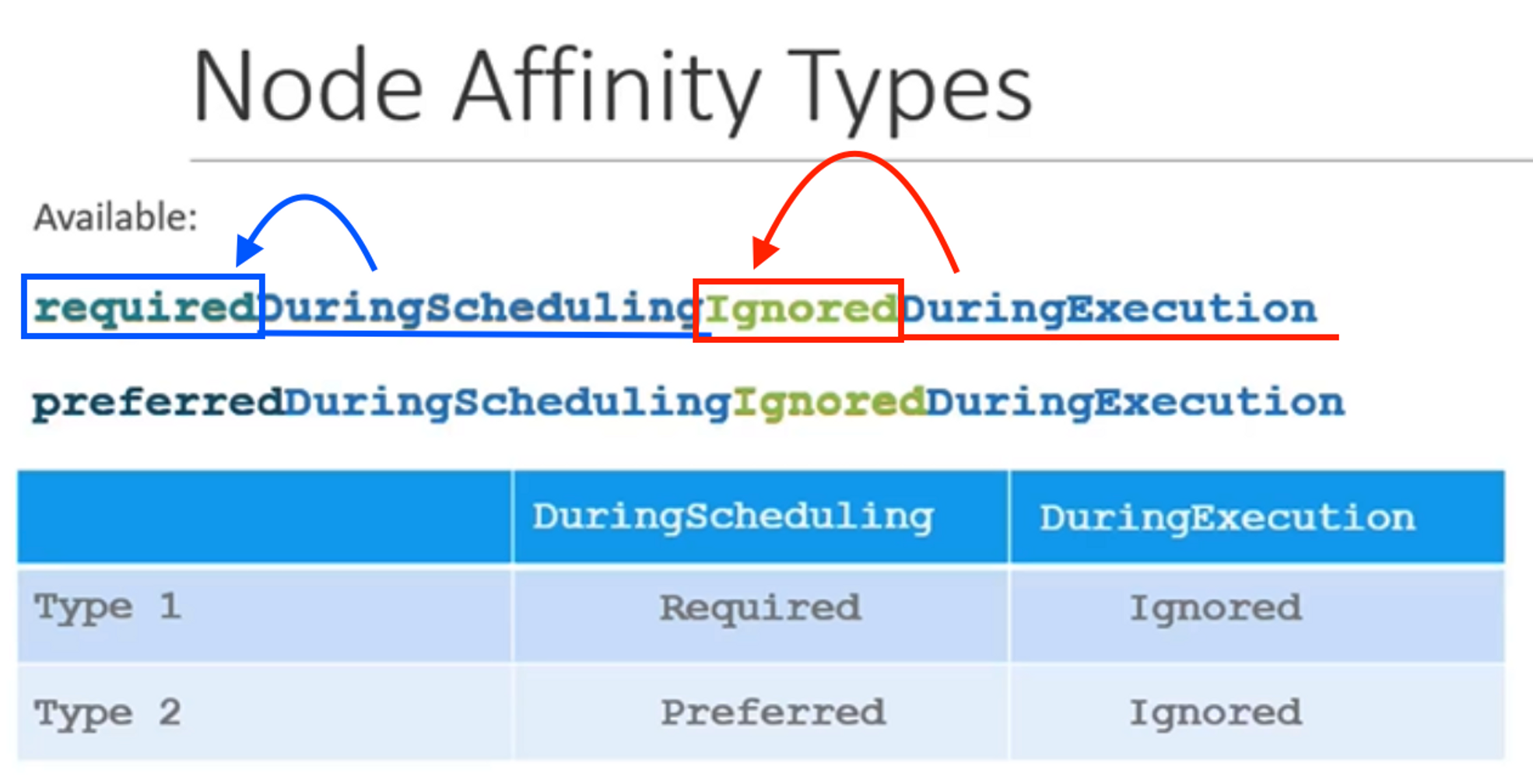
-
Available
- requiredDuringSchedulingIgnoredDuringExecution
- preferredDuringSchedulingIgnoredDuringExecution
-
Planned
- requiredDuringSchedulingRequiredDuringExecution
- preferredDuringSchedulingRequiredDuringExecution
-
파드의 LifeCycle
- DuringScheduling
- Pod가 존재하지 않고 처음 생성된 상태
- Required → 스케줄러는 지정된 Node Affinity를 사용하여 파드를 노드에 배치하도록 지시한다. 노드를 찾을 수 없으면 파드가 스케줄링 되지 않는다. 파드의 배치가 중요한 경우에 사용(?),
일치하는 노드가 없으면 파드가 예약되지 않음! - Preferred → 파드 배치가 워크로드를 실행하는 것보다 덜 중요하다고, 일치하는 노드를 찾을 수 없는 경우 Node Affinity 규칙을 무시하고 사용 가능한 노드에 파드를 배치할 수 있다.
- DuringExecution
- Pod가 실행 중이고, 노드 레이블 변경과 같이 Node Affinity에도 영향을 미치는 변경이 발생한 상태
- if, Node에
size=Large레이블을 삭제했다. Ignored: 이미 만들어진 파드는 변경 사항에 영향을 받지 않고 계속 실행된다.required: Node Affinity를 충족하지 않는 노드에서 실행 중인 파드는 모두 제거한다. 따라서 Large 레이블이 노드에서 삭제되면 Large 노드에서 실행 중인 파드는 종료된다.
- DuringScheduling
💡 특정 노드에 pod 배포하기
label, nodeSelector, affinity
